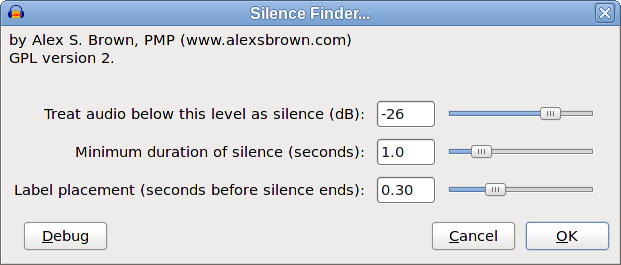
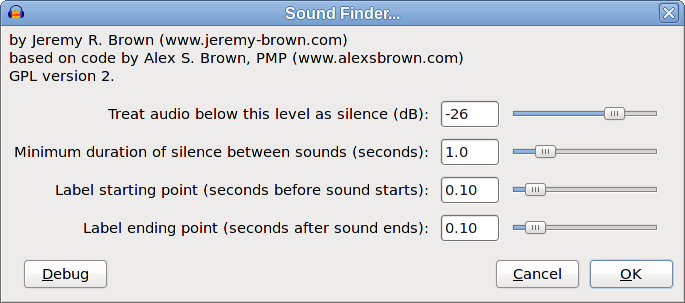
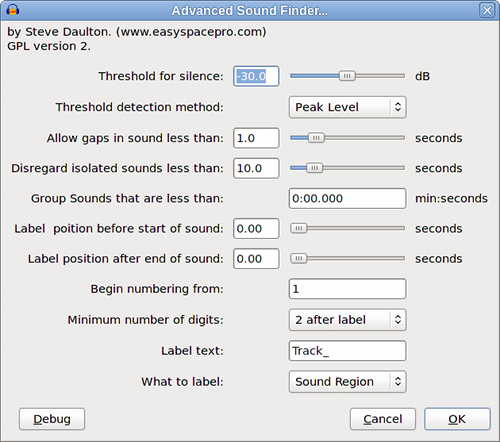
That’s the one about splitting audio books so that you get reasonable size “chapters”. I think this is fairly straightforward but for clarity we can look at that later as a separate issue. The “contentious” issue is about handling “allowed silence” and “ignored sounds”.
Thanks for the input Peter. A fresh pair of eyes is often useful.
In this particular case it’s not really possible to separate out the “allow silence” and “ignore sounds”. Short periods of silence always occur in audio. As said earlier in this topic, taking it to the extreme there is a short “silence” each time the waveform crosses the zero line (typically hundreds of times per second), so this must be “allowed for”.
Not really “proposing” it. I just suggested that such an algorithm may produce the output that you were asking for.
“Precedence” is the key word, in the sense of “the order to be observed”.
My previous post illustrates what happens if “allow silence” takes precedence.
I think that I wrote earlier that if “ignore sounds” takes precedence, then “bad things” happen. Perhaps it would be useful for us to look at that in more detail.
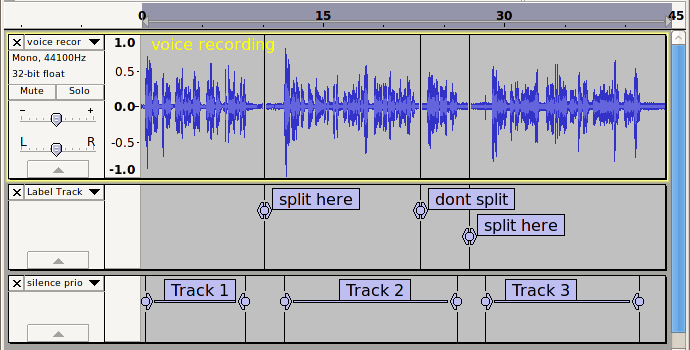
Here is a voice recording made with the built in microphone in my laptop. In this description the term “silence” refers to a sound level below the “threshold”, where the threshold has been set just above the noise floor.
There are 2 pauses longer that 1 second duration where we want to “split” the track. We do not want to split at the shorter silences. The longest “other” silence is just under 1 second. The obvious setting for out “allow silence less than” control would be 1 second, but we are not going to implement this just yet - we will give “ignore sounds” priority and implement the “1 second allowed silence” after.
On the first label track I’ve marked the position of where we want to split, and the largest “other” silence where we do not wish to split.
On the second label track I’ve marked a few of the “shorter sounds”. For the sake of clarity I am putting to one side the issue of zero crossing points - these “shorter sounds” all have silence of at least 20 ms on each side.
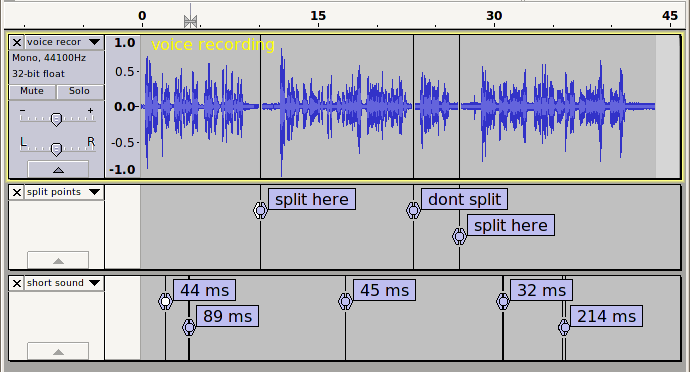
Clearly we do not want to ignore these marked “shorter sounds”, so the obvious setting for “ignore sounds shorter than” will be less than the shortest of these (32 ms). Let’s say we set it to 30 ms.
Going back to your post of Tue Feb 07, 2012 2:35 am.
In order to “not split at zero crossing points”, we are initially allowing silences up to 20 milliseconds.
We then “give priority to” ignoring sounds that are less than 30 milliseconds.
These settings produce the label points shown in the second label track in the image below:
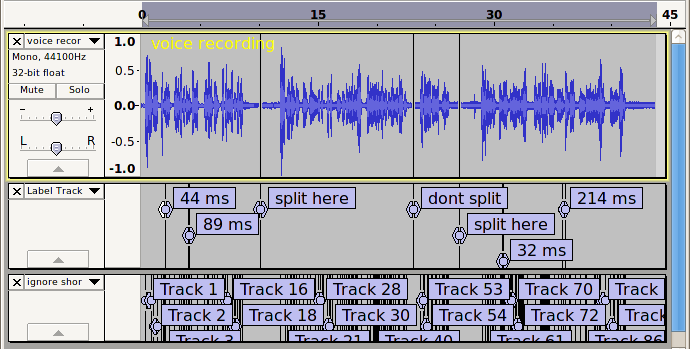
Now we implement the “allowed 1 second silence”.
The questions here are, do we:
- Extend each selection to include the adjoining silence up to a maximum of 1 second but not merge the labels (as per your suggestion)
- Extend each selection to include the adjoining silence up to a maximum of 1 second and “merge” overlapping labels
- Something else
If we do (a) then we end up with 95 labels, which is not what we want.
If we do (b) then we end up with 1 label encompassing the entire track, which is not what we want.
What is (c)?
In contrast, let’s see what happens if we give priority to “allow silence between sounds” (as per my previous post) with “Allowed Silence” of 1 second: