Topic split from here: http://forum.audacityteam.org/viewtopic.php?p=184850#p184850
A very brief answer so as not to distract from the main topic.
Firstly, the difference in quality will be small. The most noticeable differences occur when the volume level (amplitude) is very low, such as at the end of a fade out.
Audacity works internally in 32-bit float format as this provides much better accuracy (and hence quality) and better performance (speed) than working in an integer format. This means that if you process the sound in any way (anything other than a simple cut/paste/delete type edit) in any format other than 32-bit float, Audacity needs to convert the audio to 32-bit float, process, then convert back to the original format. For best sound quality, this should be avoided if possible.
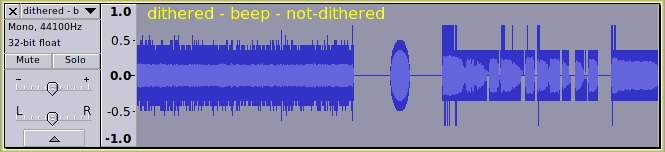
The hiss that you notice when exporting from 32-bit float to 16 bit WAV is due to dither noise that is intentionally added during the conversion from a high bit depth to a lower bit depth. You can read more about dither here: Missing features - Audacity Support
Standard audio CDs always use 16 bit 44.1 kHz stereo. This means that if processing the audio, converting from 32-bit float to 16 bit is unavoidable at least once somewhere along the line. The “trick” is to minimise the noticeable effects of the conversion. The optimum way to do this depends on what exactly you are doing with the audio.
- If you are only performing simple cut/paste/delete type edits, then the quickest/easiest methods are to either:
- set the Quality preferences to 16 bit, and/or
- set “dither” for the “High quality conversion” settings to “none”. These options are not recommended if you process the audio in any way.
- If you apply 1 and only one process to the audio, then the above method may be used, but gives little or no benefit over using the default (32-bit float with dither enabled) settings. This will incur 1 conversion from 32-bit float to 16-bit integer (the same as if you work in 32-bit float throughout and export to 16-bit integer).
- If applying more than 1 process, then for best quality the first method (1 a) should not be used because with each process the audio will be converted from 16-bit (lossless) to 32-bit float, then back from 32-bit float to 16 bit integer (not lossless). Method (1b), if used with the track setting to 32-bit float is better in that there will be just one lossy conversion (on Export). The choice of trade-off between using or not using dither depends on several factors:
- the type of music,
- whether you listen through headphones or speakers,
- the volume level that you listen at,
- which is more important to you, the sound quality of the sound, or the quality of the silences.
- how much trouble you want to go to,
Regarding item 3.
- Classical music tends to show up dither noise more than other types due to the extreme dynamic range that can be present.
- Headphones tend to show up dither noise more than speakers.
- Dither noise is at a very low level. Normalizing (in 32-bit float format) close to 0 dB directly before export will minimise the relative level of dither noise.
- Dither noise extends the dynamic range for a given number of “bits” and reduces quantize errors. For “sounds” it is beneficial. The problem comes when the sound level approaches silence.
- Without dither in 16 bit, there is no sound below -96 dB
- Without dither in 16 bit, there is no meaningful sound below -90 dB
- Without dither in 16 bit, there is no musical sound below about -80 dB
- With dither, in 16 bit, random noise (hiss) is added with a level of around -80 dB
- With dither, in 16 bit, musical sound can extend down below -100 dB, but against a background of dither noise. Below about -80 dB the noise will be louder than the music, but the music may still be there.
There are different types of dither that may be used. Rectangle dither is the least effective on normal level sound, but produces no noise when the sound level drops to complete silence. Shaped dither is one of the most effective, but produces the highest peak level of noise during absolute silence (but not the “loudest” as the noise is “shaped” to occur mostly at frequencies where low level hearing is least sensitive).
In my opinion, for very best quality, (this is where “how much trouble you want to go to” comes in), all work in Audacity should be:
- done in 32-bit float format,
- then “rendered” to 16-bit with dither enabled,
- then rendered back to 32-bit float,
- then short fade-outs to silence applied (either manually or with a Noise Gate at a very low level (usually around -70 to -80 dB. Fading out from a level below the dither noise level would need to be done manually).
- then exported to 16 bit with dither disabled.
Less arduous methods of minimising dither noise during silences are to either:
a) Trim tracks tightly before export, then use the CD burning software to add absolute silence between tracks.
b) work in 32-bit float and use “rectangle” dither.
If you wish to discuss this further, please start a new topic so that we don’t get totally distracted ![]()
(yes, this was a brief answer ![]() )
)