I’m looking for some help processing audio to optimize it for visualization and this forum seems like the place I may find people who can point me in the right direction.
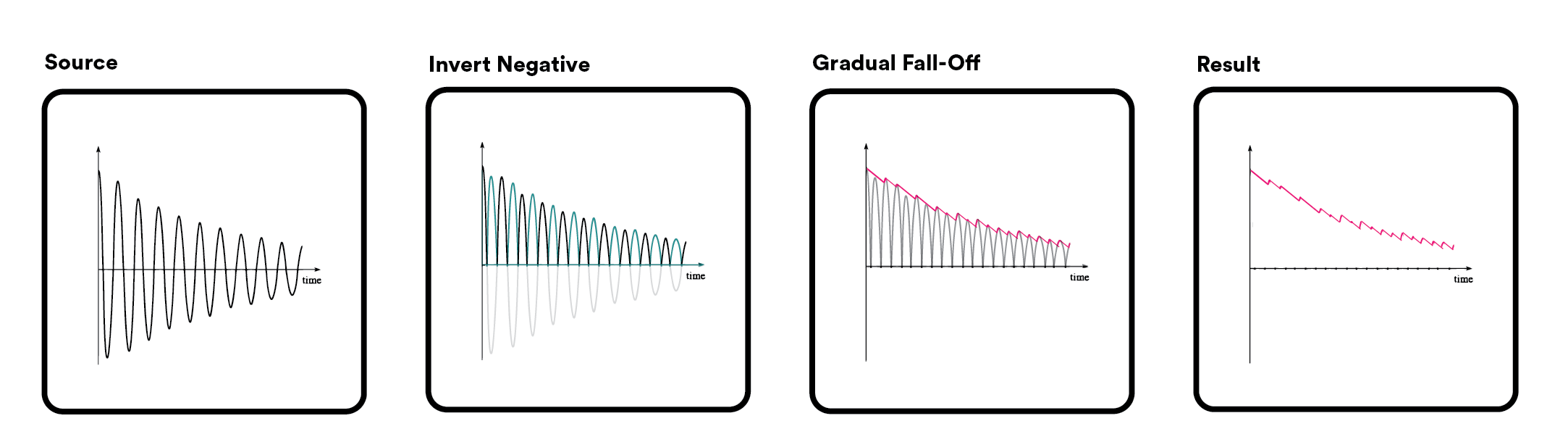
What I’m looking to do is to process any sound-wave as to outputs a waveform that behaves like a ‘VU meter’. So, in other words, has the negative signal inverted and summed with the positive, and a gradual fall off from the peaks. I’ve attached an illustration to demonstrate what I mean:
This may seem like a strange thing to do to a sound-wave, as the result will be unlistenable. However, having the audio processed in this way will optimize it for input it into video creation software like ‘Blender’, use it to drive time based animation, and have it run sample for sample in time with the audio of the video.
All DAWs must use math to do something similar to this for the signal monitor meters on all audio channels.
Is it possible to output this processed signal as an audio file (.wav etc) from Audacity or similar audio processing software?
This code assumes that the selected audio is mono (as in your illustrations). It would need to be modified for stereo.
It is a simple “envelope follower”.
The first line sets a “step” size (in seconds)
The next line converts the step size to samples
The third line converts the output to the same sample rate as the original audio (linear interpolation)
The final line is the interesting one:
It steps through the selected audio (track) in “steps” (as defined by the first two lines) and returns one sample per step. The sample value is the absolute max value within the step.
Interesting thread.
In the past, have also used audio in Blender to “drive” an animation.
I took a different approach by taking the square root of the samples and feeding it to a LPF.
This acted as a software equivalent of a half wave rectifier.
Nice code, wandering if running the result through a lowpass filter (to simulate a capacitor)
might make it less responsive to instantaneous peaks which in this case, is advantageous.
The “envelope” created by that code snippet is already (sort of) bandwidth limited by the “step” size. Consider an extreme case where SND-AVG returns alternate positive and negative sample values - the result would be a triangle wave with a frequency of 1/(2 * step). For a step size of 0.01 seconds, that is 50 Hz. A lowpass filter above 50 Hz would just round the “corners” of the triangle wave.
So, from what I understand from your explanation, the script sort of creates and average of the waves velocity by almost bit-crushing?
The smaller the number in the first line of code; the higher the resolution of the envelope follower - and if you go really low with that number you end up with a result that is similar to the first part of my illustration (Invert Negative)? and you then loose this “averaging” that you get by “bit-crushing”, or down-sampling the resolution?
I’m wondering if there might be a way to keep the fidelity of a higher sample rate, while averaging, or “smoothing” out the result.
What if I were to run the result of the script at a higher resolution through a super fast delay? and by tuning the feedback of the delay, might that provide me with a smooth fall-off?
The Lowpass filter idea is a good one!
I’m experimenting with Steve’s code at “high-res” and trying delays and LPF to smooth.
Yet to get exactly what I want, but I’m getting close - certainly better than using unprocessed audio!!
I think I’m close to being able to describe what I’m still missing with these methods.
What I want is to preserve the attack of the audio events, while elongating the decay - exactly in the way a normal channel strip meter will jump up instantly to the peak of a new sound but slowly drop away when the sounds source ends.
And I want to be able to tune this fall-off if possible.
I think this need to prolong the signal after an audio even is to do with the different ways in which we perceive sounds versus visuals.
A sharp abrupt percussive sound will be very distinct and noticeable even is it fades as fast as it appeared - However if an event happens in a video that is no longer than a frame or two, it can quite easily be missed. This reminds me of a video edit I had to make a few years back - I ended up having to duplicate a single frame of a lightning strike and motion track it over the following frames of footage with a slow fade out - I had to do this otherwise the lightning was barely noticeable and had no impact (it was only captured over one frame).
The problem with the down-sampling to get an averaged or smoothed result is that you lose the sharp jump and precision of the attack.
Using a Low-pass filter also has this effect as it prevents the fast attach from getting through (as it’s too high frequency).
Using a delay also seems to do this as the delayed signal sums with the signal before it, and as such offsets the peak.
If an outboard VU meter (like the one in the link above) can do this with a small IC chip, there must be a way to achieve this with maths in Audacity - right?
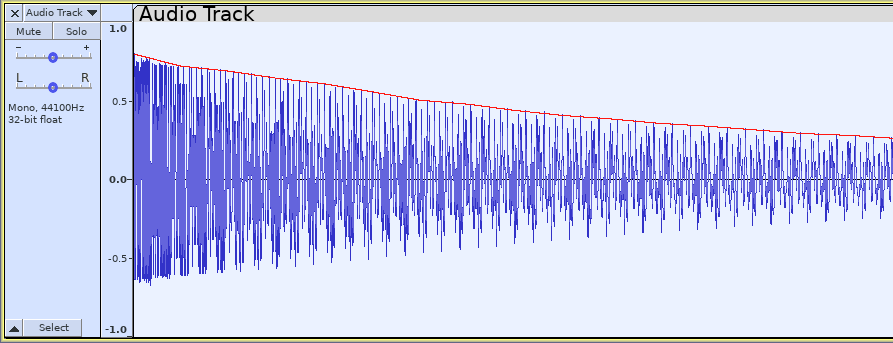
In the example, the “step” size is 10 ms (0.01 seconds).
If the track sample rate is 44100, then 10 ms is 441.
The SND-ABS function will step through the selected audio in blocks of 441 samples.
Because we’re using “op-peak” option, the SND-ABS function will look for the highest absolute value in each block of 441 samples, and will return one sample of that value. For example, if the highest absolute value is a negative going peak of -0.8529, then the absolute value is 0.8529, and that block will return one sample with an amplitude of 0.8529.
We then use FORCE-SRATE to resample the result back to the original sample rate of 44100 samples per second.
The result is a signal (indicated by the red line) that tracks the absolute (+/-) peaks of the original waveform:
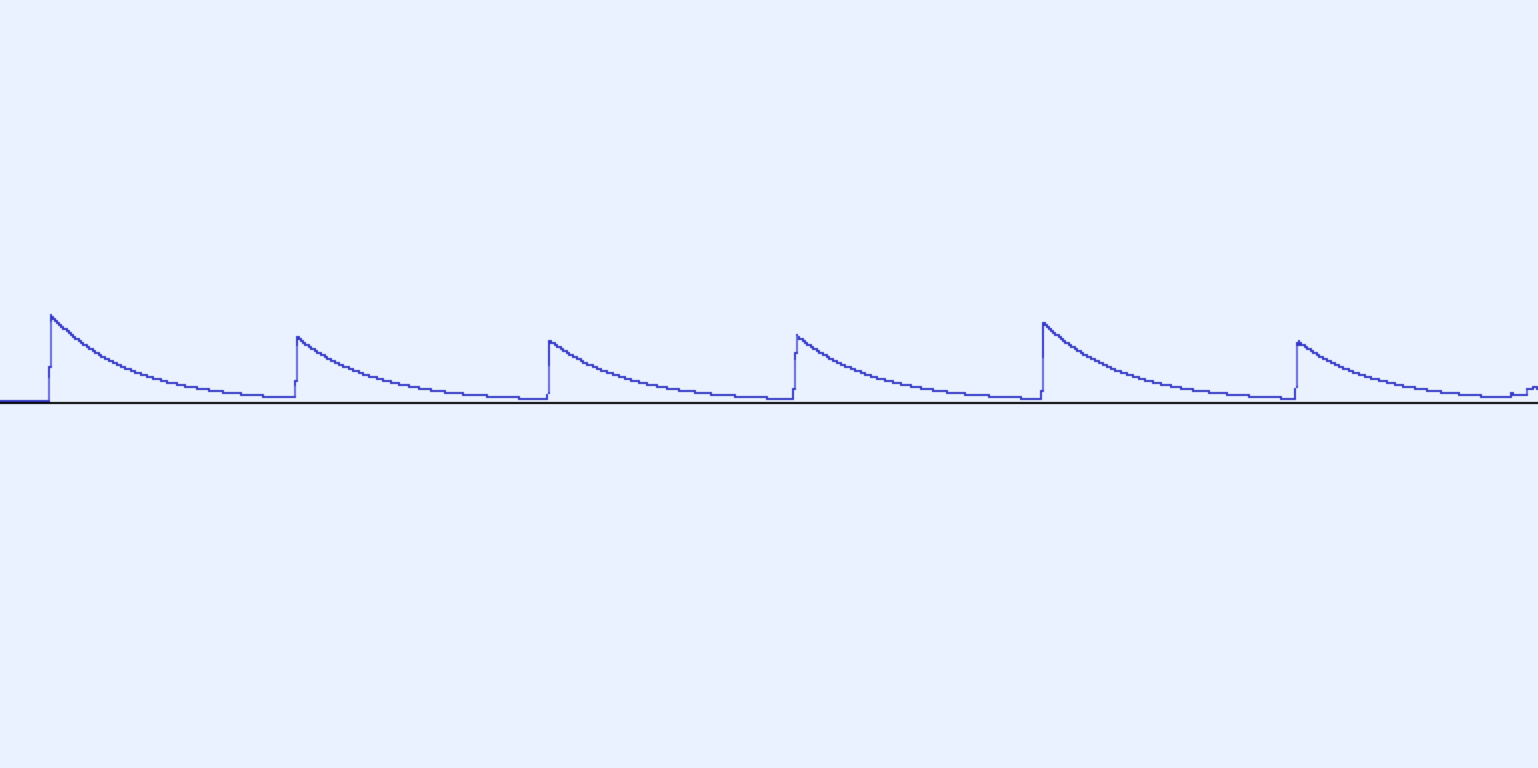
A “possible” disadvantage (I don’t know if it actually will be a disadvantage for you or not as I don’t know exactly what you are intending to do) is that, because the “release” (“fall”) is exponential, the “floor” must be greater than zero (log zero is an error).
You can get as complex as you like with this - Nyquist is a full featured programming language for audio.
It’s beautiful and exactly what I thought I wanted, and is a million miles better than just using raw audio - thank you so so much for helping me!
I think what I’m looking for in addition to this is a function that:
takes the result of the previous step, subtracts “value x”, and then compares the result to the current step with a “if greater than”, and then implements the highest of the two as the result for the current step - and continues on.
This way the signal can’t fall faster than the rate set by “value x”, but can jump up as fast as it likes at any point in the music.
How long are the sounds?
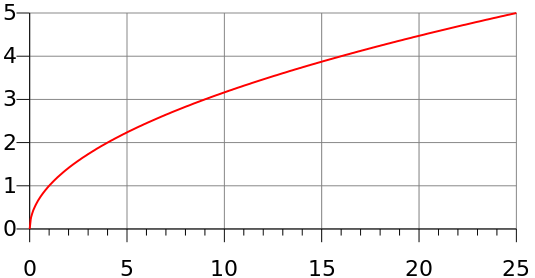
If they are short, then the sound could be grabbed as an array of samples, processed and converted back to a sound. This approach provides a lot of flexibility, but it becomes tricky for long sounds because there’s a limit to how many samples can be grabbed into a single array. Up to a million samples is no problem (about 22 seconds for a sample rate of 44.1 kHz).
The current project I’m working on is a music video.
The primary source is separates from a drum track (Snare, Kick, Toms etc.), where there are no more than a few seconds max between events.
However, if we find a versatile working solution to this, I see it potentially being of benefit to the Blender community at large.
The “Bake Audio F-Curves” feature in Blender is incredibly powerful, it’s just let down by the nature of how raw audio files work.
If a workflow for processing audio in audacity with a “Nyquist Prompt” before importing to blender can be found, it would no doubt be useful to many other Blender users in the future.
Sorry, I get you now.
Most audio clips will be song length (3 to 5 mins) - so much larger than 22secs.
Might cutting an audio file into sections be possible, and then bouncing it down reassembled as one after processing be possible?
Isn’t the square-root function going to cause dynamic-range-compression, compared with rectification + smoothing ?.
It very well could depending on the input level of the audio.
If it was to use the audio, as audio, it could be a problem, however the idea behind it was to use the audio envelope to create
an offset in an animation.
The resulting audio will never be heard, so a bit of dynamic range compression is not a problem.
Blender also allows the tweaking of the “trajectory” so if it looks a bit odd towards the end of the motion path, it’s easy to fix.
{kind=link}