first I’d like to say I’m using Audacity for many years now, mainly for recording my vinyl and I’m very happy with it. Many Thanks for this to all the developers.
Now to my feature suggestion. The one thing I’d like to see in Audacity is a display of the true waveform. Currently Audacity generates the waveform-display by just connecting the dots from the individual samples.
In some cases it is necessary to do some manual editing to my recordings from vinyl and with the current display sometimes I only get a coarse approximation of what the waveform really looks like, especially when the edits are near the nyquist frequency. Another issue is intersample clipping (I don’t know if it is the right term for this). When editing samples close to 0dbfs it is possible that the resulting waveform is clipping even when all the sample are below 0dbfs. With the current display there is no way to detect such a clipping in the waveform.
I’ve looked into this forum and the Wiki but I didn’t find any hint that such a feature was discussed before. Maybe this was discussed before and was omitted but maybe it will be taken into consideration for a future release.
There is no waveform. The blue waves in Audacity are a convenience created by Audacity for the benefit of the humans. The computer only knows the samples.
It’s certainly possible to have sound values at or near 0dB and create distortion or clipping in the final show – assuming you insisted on using MP3 or other compressed medium. This is because compression techniques cause distortion. We have never advocated doing any sound work so close to the zero point that this effect occurs.
We admit that the clipping indication tools are not perfect. It is possible under certain circumstances to get red clipping bars with no sound distortion. Use Analyze > Find Clipping as a check.
The pure Nyquist limit of 44100 samples is 17KHz audio, not as it is sometimes assumed 20 KHz or higher. The apparent response to audio up that far is a result of inaccuracies, noise and pure guesswork. If you look at a sound sweep up that far, it gets ratty and lumpy pretty quickly. Sound systems will not tolerate sound management at or near the Nyquist limits. This is one reason people insist on much higher sample rates for live performance work – specifically to avoid this effect.
You’re applying for membership in the club of people trying to do scientific measurements in Audacity. It’s not a good club. Audacity is not a WAV editor. It’s a sound or production editor and measures are taken to make overall production easy and graceful. Some of those measures make it undesirable to violate good sound management rules.
I understand now that Audacity is not really meant for the type of work that I’m doing with it. So far it worked very good for me, and I thought It would be a good feature to see what is really happening to the music when removing a click from the recorded vinyl. I’m sorry if I’m suggested something that doesn’t make any sense.
Firstly, the reason that Audacity uses “linear interpolation” (joins the dots) in the drawn display is for speed. Linear interpolation tends to be much faster than other forms of interpolation, so you don’t need to sit waiting for long while the waveform is drawn.
The second reason is that there is no “true” waveform. Strictly speaking, digital audio is just the dots - the lines are for convenience, but do not really exist in the digital data. Conversion from sample values to analogue waveform is handled by the D/A converter in the sound card. Precisely how, and how well it does that conversion is down to the design and build quality of the sound card. Theoretically it could use linear interpolation, in which case the analogue output would look exactly like what you see in Audacity. In practice, D/A converters usually use some form of reconstruction filter that limits the frequency bandwidth and so avoid aliasing distortion. There is no way that Audacity can know what the D/A converter will actually do, so really what you are asking is that Audacity should draw an idealised analogue representation of the digital signal, but I’d guess that would be quite slow to calculate - certainly a lot slower than linear interpolation.
I’ve read several articles that discuss this issue, but in reality it is rarely a problem for normal audio.
There are three main reasons why it is rarely a problem:
In normal audio, the amount of energy in the very high frequency range is usually tiny, so even if inter-sample clipping occurs, it will almost certainly be inaudible.
Clipping distortion of “normal” waveforms sounds bad because it creates harsh high frequency overtones. Where inter-sample clipping could be a problem would be with very high frequency tones, but in these cases it is impossible for higher frequency harmonics to be created because they would be beyond the Nyquist frequency, so a high quality D/A converter those overtones should be completely eliminated by the D/A ant-aliasing filter, In effect all that would occur would be extremely mild peak limiting.
Apart from very high end D/A converters ($1000’s) most D/A converters have poor performance very close to 0 dB. Even for high-end semi-professional equipment it is common for D/A converters to clip a little below 0 dB.
The moral of this story - for best quality, always leave a little headroom in your final 16 bit mix-down. (For WAV format, 1 dB headroom is likely to be enough to avoid risk of conversion clipping - for compressed formats such as MP3 it is better to allow a little more headroom). This advice knowingly flies in the face of popular modern mastering techniques that frequently favour “as loud as possible”.
Sorry if it came off that way. People who worry about sample level statistics, pixel count, and that last fractional dB before sound damage are generally using commercial music as the model on which to produce music. This is the commercial music that has been compressed and punished to always be the “loudest on the block” so as to capture the ears of the paying public. Musical quality is frequently irrelevant. You may find that doing sound production at -1dB or even -0.5dB gives you satisfaction and all the overload problems associated with MP3 and other compressed exports vanish.
If that’s not true, you can certainly use the compression tools, too. I like Chris’s Compressor which not only makes the show louder, but evens out the volume variations within the show. Chris designed it to listen to opera in the car.
It’s not my goal to get the music as loud as possible, I just want to digitize my vinyl in the best possible way and Audacity, even not meant for this, is a very good tool for it.
That makes sense to me so I will leave that 1dB headroom before converting to 16bit. By the way, compressing my recordings to MP3-format is just a by-product for portable use and not the primary goal.
I know about the loudness war and believe me I’m not a fan of it, to put it mildly. I fact it is one of the reasons why I’m converting my vinyl to digital instead of buying it again as “remastered” CD or MP3.
(update, Steve posted while I ve-been writing this - so our opinions overlap widely)
I am sure that no offense was intended by Koz. His practical heart bleeds sometimes when a lot of mathematical theory is involved.
The simple Connection of the samples is the fastest method to update the Display because only 2 Points are needed to make an Interpolation.
This method is as wrong or as right as any method one can employ to simulate the real Output, as it would appear on a analog oscilloscope.
Audacity can’t see where and thru what Hardware the Sound goes after the Export or during the playback.
Besides the problem with clipping is not limited to the Nyquist Region. Any steep Transition between samples can cause an overshoot.
Imagine the Membrane of your Speaker that must move within a 1/44100 s from -1 to 1. Either this Membrane acts very fast and overshoots or is damped and stops at the right Point but a Little bit too late.
A work-around to simulate your Feature request would be to Display more Points.
Try the following:
Generate a square wave with Amplitude 1 at about 1760 Hz (far from Nyquist).
Duplicate the track, select it and resample it (under tracks).
Enter a new value of 220500 (if the Project-srate is 44100).
We have now a wave form that has 5 Points instead of only 1.
If you zoom in you will notice that each steep Transition goes over the top.
I have a value of 1.7 dB over dBfs for fast Interpolation (Quality Settings preferences) and 2.0 dB for high Quality.
Your Feature request is therefore not so senseless.
It is imagineable that one can arbitrary set the Interpolation method for the wave form Display
Linear, La Grange, B-Splines etc.
Extremely useful for non-Audio applications too.
[:Update:] Robert posted while I was typing, but there is an interesting overlap
This has got me thinking about the metering.
Although I said that with normal audio so called “intersample clipping” is not really a problem, there is perhaps a case for the meters to show the inter-sample peak level.
The case is hard to demonstrate with “real world” audio, though it could perhaps have an audible effect on transients (very short sounds) that have a very high peak level and a significant high frequency content, such as a cymbal hit.
It’s easy to demonstrate with synthesized tones, so here is a demonstration:
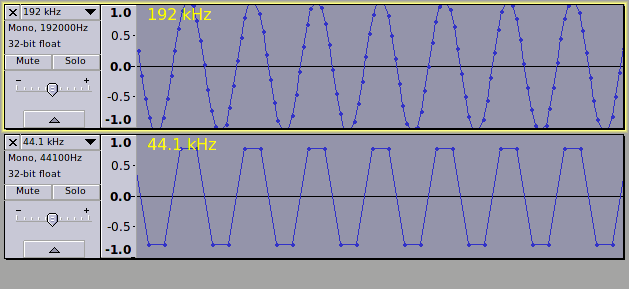
Create an empty track and set the track sample rate to 192000 Hz (192 kHz) using the track drop-down menu http://manual.audacityteam.org/o/man/track_drop_down_menu.html
Select a couple of seconds at the start of the track, then run the following code by pasting it into the Nyquist Prompt effect (Effect menu) and applying.
;; Generate 11025 Hz tone 45 degree start phase
;; peak level over 0 dB
(mult 1.122
(osc (hz-to-step 11025) 1 *table* 45))
This generates a tone at 11025 Hz at +1 dB and it is clearly clipped.
However, if the track is played, and the Project Rate (lower left corner of the main Audacity window) is at the default 44100 Hz, the meters show the peak level to be -2 dB
The reason for this anomaly is that the meters are working at 44100 Hz sample rate.
Create a new track with a sample rate of 44100 Hz (44.1 kHz) and apply the same code as above.
The new waveform is visibly below 0 dB . In fact it is about -2 dB.
If we zoom in really close the reason for the low peak level becomes clear - The choice of frequency and starting phase are just right to miss all of the peaks in the waveform.
I don’t know if it would have a significant impact on performance, but perhaps the meters should run at a higher sample rate so as to give a more accurate reflection of the peak level throughout the full audio range.
[Update: The meters take their input from the audio stream, so the suggested behaviour can be achieved by increasing the project rate]
Thank you Robert! This is a very interesting simulation. I tried it with the square wave and will do a little experimenting with that next time I record one of my vinyl’s.
Thank you too Steve! Is it possible that the sample rate of the meter is connected to the Project rate? I have generated the tones as you suggested. If the project rate is set to 192000Hz the meter goes all the way up to 0dB and the red clipping bar at the meter is illuminated on both tones. With a project rate of 44100Hz the meter shows -2dB and no clipping at both tones.
Cheers
Christian
PS: Steve, it seems you updated your post while I’m writing So the meter is connected to the project rate.
It gets hectic when we’re all typing at the same time
Yes, as I added at the end of my last post, the meters take their input from the AudioIO stream which has the same sample rate as the Project Rate.
Be careful if you change the Project Rate - that is the sample rate that is used when exporting an audio file.
For this particular subtask you may want to consider using Brian Davies’ excellent ClickRepair tool - it costs a little but is well worth it if you have many LPs to transcribe. You can have 1 14-day free trial to see how it works for you. Brian is a retired Australian mathematician who some years ago was undertaking the same task as you, transcribing his LPs. He realized that he could write some very focussed tools to help him with the clean-up tasks - the results of CR are a little shy of magical imo (and I listen on fairly high-end kit QUAD electrostatics ELS-57s)
Immediately after capture I export a 32-bit float WAV. I then process this through ClickRepair and then import the repaired 32-bit file back into Audacity for all further processing. See this sticky thread: Click/pop removal - ClickRepair software
This step also leaves you with an unprocessed raw-capture 32-bit file for archive backup should you require that.
You may also find this suggested workflow tutorial from the manual useful: Audacity Manual
thank you for your suggestions and for the link to the workflow an the thread about ClickRepair. I’m doing my transcriptions pretty much the way you suggested it and as it is described in the manual.
I discovered ClickRepair just recently and I’m using it for a couple of weeks. Currently I’m using fairly low settings in ClickRepair, which leaves a single Click or Pop now an then and for the moment I rather remove these manually instead of increasing the ClickRepair settings. But I’m still in a process of try and error with ClickRepair.
I used to do my repairs manually, originally with the Draw tool in Audacity and then with the Repair effect when that become available - but I found that was taking far too much time and was extremely tedious.
I find Brian’s default settings a little too harsh - after much experimentation I use:
DeClick = 30 (Brain’s default is 50)
DeCrackle = off
Pitch Protection = on
Reverse = on
Method = wavelet
Automatic = All (after initial use I now trust it to do its job)
The reverse is a cute trick to avoid the false positives of the rapid attacks you can get with percussives. Brian’s s/w looks ahead and buffers the reverse so you can still hear the results (if required) as is playing normally forward. One of the things I really like is the ability to choose: raw signal, output, noise or none. The “noise” is particularly useful as it helps you ensure you are nor removing too much real signal (music). Of course it runs much quicker with Sound Output - none.