There are sometimes claims that the type of DC offset correction used by the Normalize effect in Audacity can cause DC offset errors with asymmetric waveforms. I previously believed this was true, but have since been unable to find any real evidence to support this claim. This post looks at one possible explanation for how this misconception might come about.
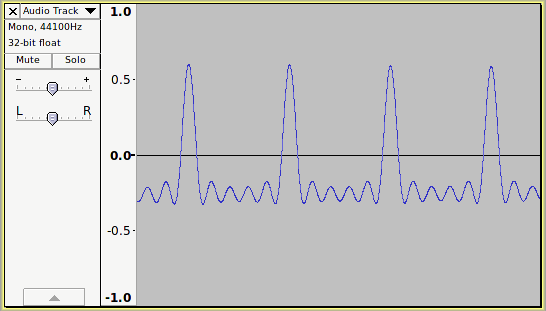
Asymmetric waveforms are common when recording real instruments and are often said to be particularly common to brass, woodwind and string instrument recordings. For demonstration purposes, this audio sample is a crude synthesized “bassoon” type sound.
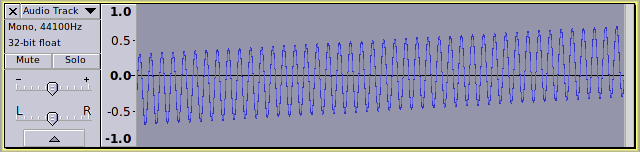
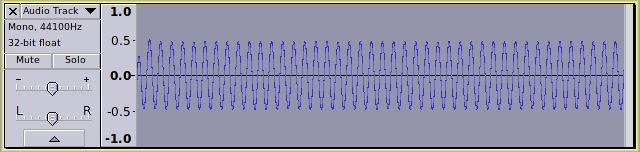
A close-up of the waveform reveals that it is asymmetric (higher above the 0.0 horizontal line than below)
Zoomed out we can see that the waveform is asymmetric, but there appears to be no “DC offset”
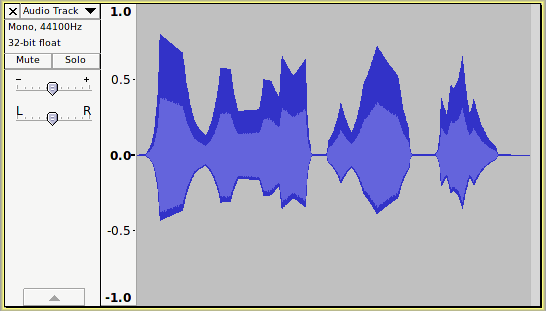
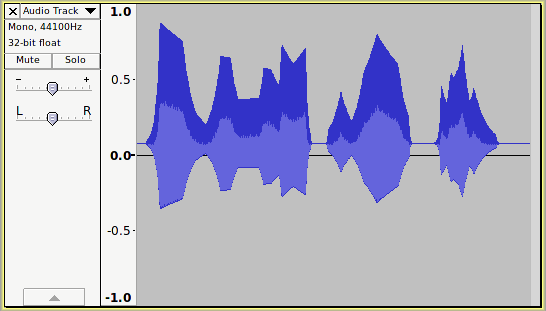
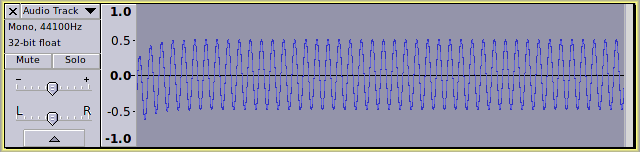
Now let’s see what happens when we apply the Audacity Normalize effect and correct for DC offset:
Oops, that shouldn’t happen should it?
Or should it?
What has gone wrong here?
I’m not sure how you got the original waves. To get DC offset in the original show, the coil, diaphragm or ribbon would have to leave the microphone and slowly walk toward or away from the performer. There was and may still be a school exercise where you created a theoretically perfect music system that responded down to DC. You could put a gust of wind in and the gust of wind would come out on playback. The system would also suck on command.
That’s the only way you can get “DC” in a music system barring something actually being broken.
So even though the digital system can do that, the analog system ahead of it can’t. You also have to be careful not to pick a non-representative subset of sound. You have to select enough music so that a complete 1Hz of music would be supported.
I wish I had kept it, but I listened to a radio show where the presenter and the guest both had aggressively non-symmetrical voices – in opposite directions. The timeline looked like a badly damaged square wave, but I’m sure if I analyzed it, it would all come out zero.
This little Nyquist script allows us to see the offset (bias) for each 1/4 of a second of the audio track (mono only).
(setq step (round (/ *sound-srate* 4))) ; 1/4 second in samples
(force-srate *sound-srate*
(snd-avg s step step op-average))
If you apply this script (in the Nyquist Prompt effect) to the audio sample posted previously it will shed some light on why the DC offset correction in the Normalize effect appears to fail.
Q.That audio sample is not a real recording - you synthesized it to have this problem. Does this ever happen with real audio recordings?
A. Yes I cheated but yes this can occur (though not usually as badly) if a strongly asymmetric waveform is recorded through a sound card that has very poor linearity. It can also occur is a strongly asymmetric waveform is clipped or peak limited.
It may also occur if audio that has DC offset is gated or subject to some “noise suppression” or “recording enhancement” effects.
(All of which amounts to the same thing: non-linear gain).
Q. Is there a solution?
A. The best solution is to use better recording equipment.
If that is not an option, (for example with audio that has already been recorded), use this Nyquist DC offset tool with the options:
Doesn’t the contribution by edgar-rft to the thread referenced above expain what is going on? Surely the asymmetry of peaks above and below the axis is irrelevant to whether there is DC offset? What matters is whether the integral of the waveform over a reasonable length of time is nonzero - think of it in terms of finding the cos nt component in the spectrum when n is zero.
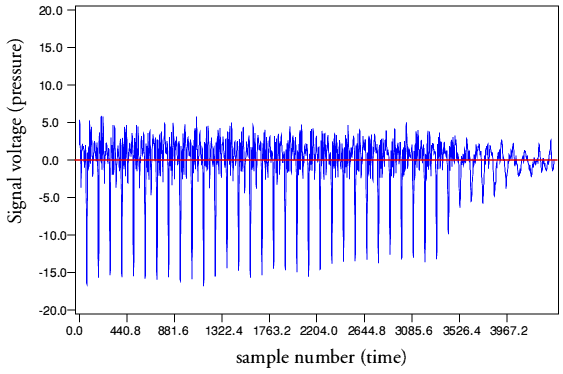
Steve’s artifical example in his first graph clearly has more area between the axis and the part of the waveform below the axis than between the axis and the part of the waveform above the axis, despite the above-axis peaks being larger than the below-axis peaks. So the DC offset is negative.
The second graph, over a longer time period, shows patches of a waveform with DC offset mixed with some zero-offset silence, a combination I would be surprised to see in reality in the absence of clipping of a waveform like the Miles Davis example. No surprise at all that applying DC offset correction moves the waveform up not down.
You’re absolutely correct. When you understand what is happening, then the behaviour is not surprising.
but they do occasionally occur (though not as badly as my illustration), and cause a lot of confusion when they do.
I’ve been searching for a good “real world” example, and I’ve found one. It’s quite a nice trumpet sample that has no obvious clipping.
Try Normalizing this sample to 0 dB with “Remove any DC offset” enabled.
This will have to be all explained in course of time to mere mortals (non-audio-engineers).
Can you define “non-linear gain” concisely as part of that? Googling doesn’t produce anything very usable.
So, are we saying
has negative DC offset because in any given length there is a greater number of samples below zero which outweighs the samples above zero having greater amplitude?
And so when Audacity tries to remove the offset, it moves the waveform upwards, but the result is “wrong” (obviously not because it still “looks” asymmetrical) because the sum is still non-zero?
And:
(setq step (round (/ *sound-srate* 4))) ; 1/4 second in samples
(force-srate *sound-srate*
(snd-avg s step step op-average))
shows this “non-zero-ness” for quarter second steps, so shows very clearly where the Audacity DC remove is still wrong? (And this code only works on mono tracks, right)?
This visual result isn’t very “scientific”. Is it possible to get some debug output that says which 1/4 second regions were offset?
Your Nyquist “DC offset” has multiple removal options.
Is the “absolute” one what Audacity uses?
Would your default “dynamic” method (clearly better visually than Audacity removal) show no 1/4 second sections with offset?
Is the dynamic always the best method? Or high pass if you can be sure to avoid clicks? Or have you got to use different methods each time? Can the result be “verified” statistically?
Let’s say that we have a series of sample values from an audio signal:
-10 dB
-15 dB
-20 dB
-25 dB
If we amplify the signal by +1 dB we would expect the sample values to become:
-9 dB
-14 dB
-19 dB
-24 dB
If we amplify by a further +1 dB (+2 dB total) we would expect the sample values to become:
-8 dB
-13 dB
-18 dB
-23 dB
This is “linear amplification” (linear gain) and is what an “ideal amplifier” will do.
In the real world of analogue electronics, amplifiers are never quite “ideal”, though usually they are very close with modern electronics.
Let’s say that we have a very bad amplifier and after attempting to amplify our original signal by +2 dB we get the following sample values:
-8.3 dB
-13.1 dB
-15.9 dB
-22.7 dB
We can see that the highest sample value (was -10 dB) has been amplified by +1.7 dB, whereas the lowest sample value (was -25 dB) has been amplified by +2.3 dB.
The relationship between the input signal (the original sample values) and the output signal (the amplified sample values) is not linear - the “gain” changes according to the amplitude. This is an example of “non-linear gain”.
This image shows the typical current gain of a single transistor circuit. It shows that at very low current, the gain is non-linear, but then there is a (fairly) linear region as the input signal increases, until the transistor becomes “saturated”, at which point the gain begins to decrease (non-linear):
It has negative DC offset because the overall sum of samples below the 0.0 centre line outweighs the overall sum of samples above the line.
For “DC” offset we are interested in the net value of all the samples. By definition, “DC” is a “constant” value.
For a signal that has no DC component, if we add up the values of all samples, the total is zero. This is how the Audacity DC offset removal works - it adds up all of the sample values and calculates the average sample value (which is zero if there is no DC offset). If the average sample value is not zero then there is a “DC offset”.
Quick definition: “DC offset” is how much the average sample value is offset from zero.
Coming back to your definition: “has negative DC offset because in any given length there is a greater number of samples below zero which outweighs the samples above zero”
there is a potential problem:
What if the “average sample value” in the first half of the audio is different to the average sample value in the final half of the audio?
Overall, the samples may balance out (no DC offset), but if we look only at the first half we would see DC offset, and if we look at the second half we would see a different DC offset. This is where the Audacity DC offset falls down.
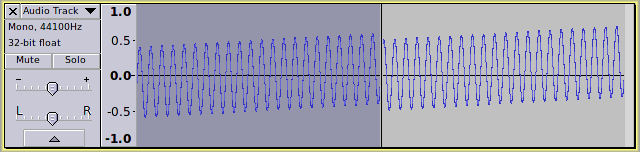
As an illustration, consider:
If we apply DC offset correction to the first half of the track we get:
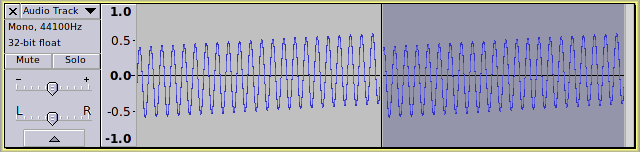
and if we then apply DC offset correction to the second half of the track we get:
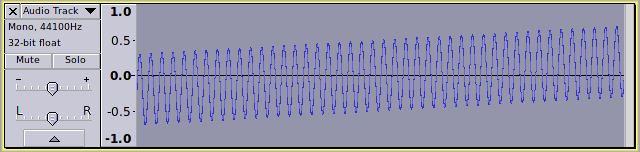
but if we applied DC offset correction to the entire track, then we would have (no change):
The problem here is that there is a gradually drifting offset, but overall the offset is zero.
The DC component (overall) is zero, but we can clearly see that there is a negative “bias” at the start of the track which gradually becomes a positive bias at the end of the track.
What my “Dynamic bias adjustment” does is to look at a rolling average rather than an overall average. The period for each subset of samples must be great enough to not be influenced by low audio frequencies. The result of "dynamic bias adjustment looks like this:
To complete this series of illustrations, this is the effect of the high-pass filter method:
Based on my Nyquist implementation of “dynamic bias adjustment”:
“Dynamic” is best if there is a changing bias.
“Absolute” is marginally more accurate than “Dynamic” if there is constant DC offset (a “bias” is present that does not vary over time).
“Absolute” is better that “High-pass” if there is constant DC offset.
“High-pass filter” is better than “Absolute” if there is a non-constant bias, but not as good as “Dynamic”.
The results can be verified with the method described in the post above this one.
A C++ implementation of “Dynamic” could improve the accuracy for “pure” DC offset (a “bias” is present that does not vary over time).
I think that ideally, offset correction should test if non-constant bias is present and use “dynamic” if it is, and “absolute” if it isn’t. With careful implementation this could probably be done with very little performance overhead as Audacity already loops through the samples to calculate the overall offset.
99 users out of 100 would probably expect offset removal to move the bassoon waveform down and the trumpet waveform up, but that’s another issue.
So is Audacity offset removal getting both these wrong because of non-constant bias, or because parts of the selection have no bias? I assume the former? I notice if you just select the first trumpet note and remove offset with Normalize, Audacity seems to do a respectable job.
Are we now saying that non-constant offset is a feature of brass recordings, or a feature of brass recordings made with non-linear equipment, or a feature of any type of recordings made with non-linear equipment?
Are we now saying that asymmetrical recordings made with good equipment should be fine - they are asymmetrical (so look to a novice like they are in need of offset removal) but won’t have offset?
It was just a temporary test tone. I don’t remember the frequency that I used, but this file has the same offset:
They are showing the amount that the audio is offset in each 1/4 second period. The audio sample is 1 second duration, so there are 4 offset readings.
The closer the samples are to zero amplitude the better.
The “Audacity DC Offset correction” is absolutely accurate for “DC” (overall bias).
-0.15000 + -0.05000 + 0.05000 + 0.15000 = 0.00000
However we can also see that there is an offset in the first 1/4 second of -0.15, and an offset in the second 1/4 second of -0.05, and so on.
The LADSPA effect shows a significant offset in the first 1/4 second of -0.01694. After the first 1/4 second it settles down to an offset of 0.00907
The “Dynamic bias adjustment” shows an offset in the first 1/4 second of -0.0052, which is much less than either of the other methods. After the first 1/4 second it settles down to a tiny offset of 0.00011, with an increase in the offset at the end, but still a lot better (closer to zero) than the LADSPA effect.
For the first and final 1/4 seconds a “perfect” result is debatable. It’s a bit like the situation with repairing clipped audio, where it is impossible to know what “should” replace the truncated audio. The best that can be done for the start and end of the selection is to make intelligent guesses.
Other than the initial and final 1/4 seconds, the samples should ideally be zero.
An intelligent guess for the initial and final 1/4 seconds is that they should be close to zero. The “unknown” factor is that there is no way of knowing whether the very first and very last samples in the audio selection should be at zero or a non-zero value. Probably the best guess for the first sample would come from extrapolating the offset from the third 1.4 second and the second 1/4 second to the first 1/4 second, then taking an average of the extrapolated value and the actual offset value for the first 1/4 second. The Nyquist implementation is not that sophisticated as it would be too slow.