I have been wondering for months now how peaks / levels in individual tracks combine to make composite peaks / levels across multiple tracks. I still don’t fully understand it. Can someone explain it to me? I’m curious about the science / theory side of things as well as the hands on “do ______ to achieve better volume in your songs” advice.
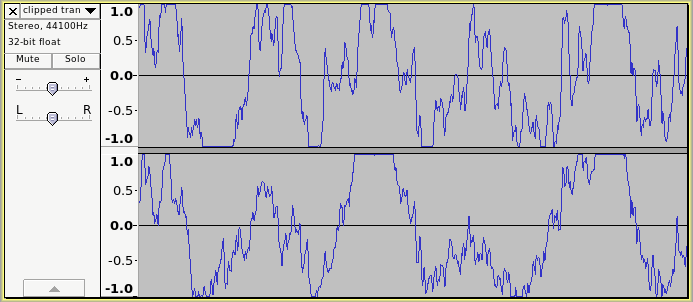
I know that it definitely IS important to keep individual tracks under clipping. Most instruments sound crackly and just plain bad when they exceed 0 dB. So I have all of them set to a max of -.1 dB, usually actually more like -3 or -6 (I understand this is standard practice if you were ever to send stems to be mastered). And up until very recently I always did my best to avoid clipping on the aggregate / track level i.e. a song consisting of multiple tracks. But lately I’ve been experimenting with just saying “f%&^ it” and just ignoring the clip meter in Audacity when mixing a full song. I’m going well over clipping in multiple spots, which I know is bad in theory, but it doesn’t SOUND bad! It doesn’t sound bad in the way that a single track over clipping sounds bad. It actually sounds good.
Not sure if it matters, but I think I’m mainly getting the clipping on percussion / transients, things like kicks and snares mainly. Are the peaks of quick transients so brief that the “crackle” of clipping is inaudible? Is it there, but I’m just not hearing it because it’s masked by the transient? If so, then is clipping really an issue?
So does this relate to the difference between volume and gain? I can get a track up to -.1 dB (maximum without clipping), but then I can turn the gain up a number of decibels above zero? And it doesn’t necessarily start to sound like sh17? Huh?
I also read somewhere that sometimes during mastering engineers will use analog equipment (instead of digital) to get the signal to go above 0 without clipping, hence boosting the overall loudness of the track. At least I think that’s what I read.
Can someone help me make sense of this? Use all the jargon and science talk you want, because I want to understand this fully.
Thanks!