Apologies if I am saying the obvious, but if you want to get rid of noise it’s a good idea to have a microphone array, i.e., multiple recordings of a stationary person speaking (the signal) in a noisy or musical environment (the noise), the track made using the mics that are more distant from the speaker will have more noise and less signal and visa versa. There will be phase delays of at most a 0.1 seconds. Using the principal of superposition, you can allow phases and multiplication factors be free variables to see what combination allows for the highest signal to noise, thus removing most of the background noise. This is basic stuff. But, what is the name of the built in-function that does this in Audacity, if any? I see invert, but that’s just sticking a -1 there and it would take a million years to line each track up and fiddle with the volumes to it’s good. What am I missing. Please don’t tell me people output the waveforms into excel and minimization using it.
https ://manual.audacityteam.org/man/vocal_reduction_and_isolation.html
which uses the spectral-subtraction method, (rather than invert method), so can generate some processing artefacts
The two legacy methods of shooting your show are shooting an interview with a long distance, shotgun microphone.

One of the NPR producers, in spite of everybody poo-pooing the idea, tried this in a close-up interview and it worked so well, many people do it this way now. The down side is the cost. He’s holding about 1000USD and that’s not counting the sound mixer.
The other you will have to take on faith until tomorrow when I can look for the pictures. You custom wire two Electro-Voice microphone cables so they’re backwards to each other. Stick the two hand-held microphones together side by side (duct tape) and only close-talk across one of them. I’ve produced a voice track in the approach path of LAX with little or no interference. It’s not Warner Brothers Studios, but I did walk away with a track.

That’s not trick photography. That’s my favorite IN-N-OUT on earth. Of course, I can’t find the microphone and cable pictures right this second.
In both of these cases, the system was designed to cancel the background sound. One inside the shotgun microphone (that’s what they do) and the other because EV microphones were just well built enough to match and cancel almost completely.
I’ve been through that multiple microphone cancellation thing before. It’s just not stable. Any separation between the microphones introduces volume and environment errors which kill the effect. The other method that looks like it should work is aiming one microphone the wrong way. Same problem. Spacing and the environment just kill you.
That’s over and above finding two (or more) home microphones that match.
As we go.
Koz
There it is.

The black thing is any XLR sound mixer or interface. A Shure FP33 in this case. The gray cable is a straight XLR “Y” cable. F F > M The two microphones are ElectroVoice EV635A.
The magic is in that tube at the back of the bottom microphone. The wiring in that tube has been changed so that pins two and three are reversed. Effectively flipping the phase of the bottom microphone.
You use this by placing one of the two microphone heads against your chin just below your lip, pointed up.
This technique appears in the ElectroVoice microphone user manual.
Koz
But like the title says, both the background noise and the signal, a person signal, are from the human voice boxes, so I’m sceptical.
Koz, that box mimics what I was assuming audacity could so. All cell phones and laptops do this in realtime; they all eliminate background noise with a microphone array. Usually a two-mic setup will do. If my calculations are right, one can also get their results by fitting these 5-parameters, which should happen upon minimizing this function where S is your signal, N is your noise, L and R are the two channels one gets from a recording using a normal cell phone designed for this:

This assume all response functions are single-termed delta functions. Ideally, once that fitting was done other terms (representing, e.g., reflections of N and S) would be accounted for, but the computer time involved goes way up as you increase the number of free parameters so it would be better to solve for those later.
Is it possible in Audacity to solve for free parameters, or do I need to use a different program?
If yes, what’s the next step?
Can any plugins do this free parameter fitting? There are many open source fitting algorithms and of course in the worst case one can do nested looping to cover the complete parameter space.
Strange. How do you guys get images and I get none? Here’s my code:
[img]https://ibb.co/TLwG8bW[/img]
[/quote]
How do you guys get images and I get none?
On the forum?
If you’re hosting your picture from somewhere else, copy and paste the address, select, and add the image tag (ninth from the left).

It’s a given that your link has to be an actual image. This one is a .jpg.
If you want to post a picture file from your desktop, scroll down from a forum window > Attachments > Add Files > Place Inline.

This one is a .png. Again, an actual image.
Koz
There is a Windows thing it’s good to know about. Windows likes to hide filename extensions “to help you.” That’s one of the first options I turn off. I’m perfectly happy seeing .jpg and .png on the end of my picture file names, thanks.
Koz
How can I fit the 5 free parameters using Audacity? Or do I need to use something like Excel? Or is there a plug in that actually does real work?
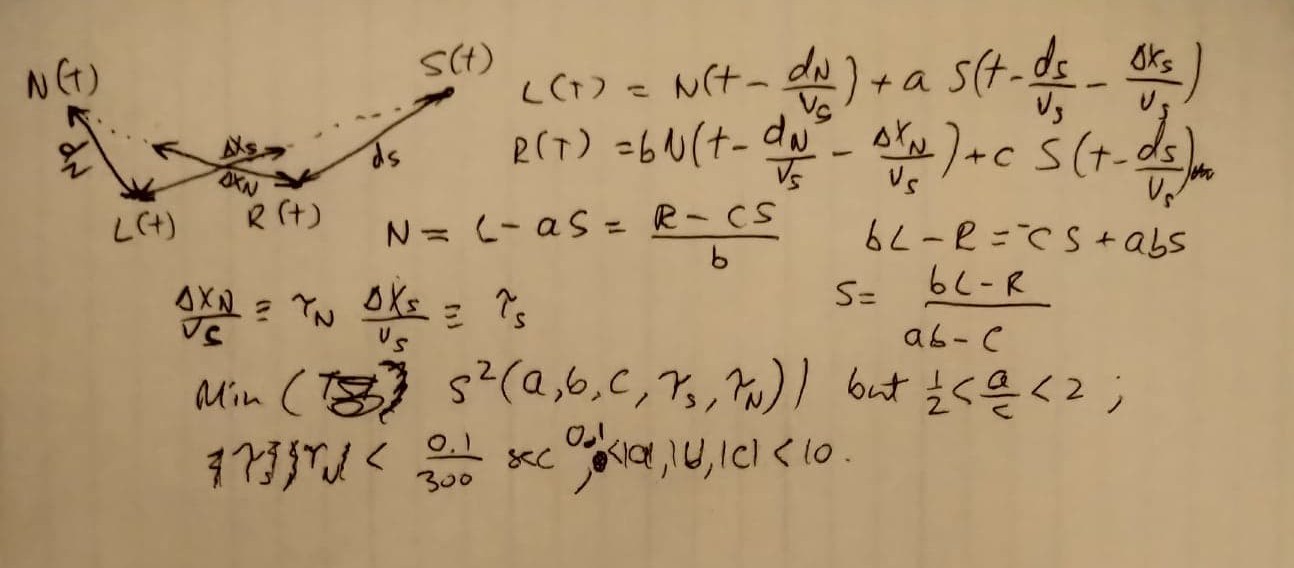
I’m sensing you need to sit down with the developers and not the first line helpers. We’ll see if a senior elf drops by.
It used to be easy to know all the branches of the program and most of the developers. We’re part of a much larger corporation now and we cover more time zones. There is a more serious political consideration. They’re in Russia.
Fair warning the handier and more valuable your ideas are, the better. If you’re solving an odd, rare, or complex problem it might not be worth assigning development time.
There could be a marketing problem, too. Nobody is going to want to issue a tool or product that’s not stable. You do not want to use the editor with the reputation of destroying audiobook readings.
Koz
The best way to put an image into a post is to upload the image as an attachment (see: https://forum.audacityteam.org/t/how-to-attach-files-to-forum-posts/24026/1), then insert the attachment “in-line” using the “Place inline” button (which appears next to the attachment). In the message composing window it will look something like:
[attachment=0]my-image.jpg[/attachment]
Audacity does not include such an effect, but it does provide a programming language to enable users to create custom effects. The programming language is called “Nyquist”. More information here in the manual: Nyquist - Audacity Manual
The best way to put an image…
My account was likely censored/restricted, so even inline images didn’t show. Discuss at Why am I not allowed to post images?
Audacity does not include such an effect, but it does provide a programming language to enable users to create custom effects. The programming language is called “Nyquist”. More information here in the manual: > Nyquist - Audacity Manual
Thanks Steve. I don’t know this language. I fear that I am too busy to learn it. I hereby offer $10-$50 for someone to write it on the condition that audacity+Nyquist has multi-core/threading. I can supply some sample audio (L(t) + R(t)) data to work with as well.
Suggested algorithm: let a=c=10, b=0.5, tauS=0, minimize S^2 or |S(tauN)| just as a function of tauN. (This assume the noise is at least 5% as loud as the signal. If cpu time is an issue listening to the files and making human guesses is more important.) Since there’s a denominator there needs to be a softening constant that is a function of the precision absolute value added to prevent errors. Then keep tauN fixed and minimize S^2(tauS). Then re-minimize S^2(tauN, tauS) … until there is convergence to a microsecond (1e-6 seconds or .03 mm.) in both variables. Next minimize S^2(b), then get convergence of S^2(tauS,tauN,b). Now do min(S^2(a)) and then min(S^2(tauS,tauN,b,a)). Lastly, do min(S^2(b)) and then min(S^2(tauS,tauN,b,a,b)). The output is N(t-tauN) and S(t-tauS) in a new stereo track.
JasonArthurTaylor, This is my first post on this forum.AudacityTeam.Org. I have used Audacity for a few years, and use it most every day to look at statistics in signals of many sorts. My priority is to do things in Javascript, since as Director of the Internet Foundation for 26 years, the only common language available to the 5.1 Billion Internet users is Javascript. Not to get diverted, I am writing because I was looking to see if Audacity supports those 8 and 10 channel audio arrays. I have a 256 channel device and 16 channel devices. Since most humans on the planet are poor and cannot afford $1000 to play with stereo, data, statistics and invention, I always try to find low cost tools.
Today I took microphone elements from two $2.95 Karaoke microphones and wired them to a $1 3.5 mm stereo plug. Black is common, red and white the two channels. Tap the microphones to be sure. I used an “expensive” $12 USB sound card dongle that can do 96000 sps. It can be accessed through Audacity as a stereo microphone. Chrome Javascript can read it, gradually all browsers are picking up sound and video. I have been doing that for about 20 years but audacity only in the last 5 years or so.
Sound is a good practice for things like superconducting gravimeters, seismometers, accelerometers, magnetometers, temperature, infrasound, vibration, sensors. Some of the experimental seismic arrays have thousands of three axis seismometers operating each at 1000 sps up to 5000 sps. There are also many software defined radio networks and data from many online experiments. I found about 2000 live videos on YouTube, and a few dozen to 100 with live sound. Some sites have multiple cameras with microphones. There are GPS/GNSS, and radio telescopes. The list is very long and I have been tracking such “emerging global networks” for about 20 years. I started with the superconducting gravimeter array to measure the speed of gravity, then found that the three axis seismometers can also track the sun and moon, so I went through all the seismometers to see which ones and which sites are useful. Then I found dozens of ways to measure gravity and hundreds of kinds of data streams where multiple sensors and arrays are used.
But getting that kind of ability to Internet users is hard. Every time someone says “interferometer” they jack up the prices by 10 times. If they say “medical” 100 times. And it is often the same stuff underneath.
Nyquist language is NOT a global language. I know, I check all computer and human language and domain specific languages used on the Internet. I would recommend that Audacity adapt its algorithms to work in plain vanilla Javascript. There are native compilers that compile to libraries that Python can use or that browsers can use. I am working on the Chromium source code to greatly simplify and organize it and separate DevTools and applications from the browsing. I reviewed about 300 of the larger project on GitHub and am simplifying that as well. It should not take groups hundreds of volunteers to do things. I am also working on “wikipedia” and many other site specific re-writes.
But to stay on track here. I am just saying hello. This equation is two traveling waves from one source to two detectors. If you read the literature on radar and sonar this is pretty basic stuff. Even if the paper and pencil math is tedious and a bother to memorize and use. I am trying to get all the LLM and other AI groups to handle mathematics in a formal and standard way on the Internet, so pretty much all humans using browsers can simply mention a method, get the full symbolic math for it, have it tied to calculators, simulators and visualization tools. I want to get humans out of “education by memorization” and “let the computers do it”. If someone want to do long division by hand, or symbolic manipulations in math, they can ask the computer to show them how. But that is like pushing a car. Better to drive the car, or tell it where you want to go.
I just download Audacity-master again from Github. It has 606 folders and 7700 files. And for some reason is 143.871087 MegaBytes. There are lots of c cpp h files py nq - so the group is splitting its efforts and attention. There are many duplicate names, which usually indicates “which one should I use” issues.
When I try to run record while looking at spectrogram it ALWAYS crashes.
I am just saying hello.
Usually to minimize the difference between two things, you can correlate. Auto correlation and pairwise correlation is often called regression. So simple linear regression works. The core of LLM methods is multiple linear regression and most machine learning has roots in probability and statistics. I am 75. I learned those things starting 60 years ago and have used some things for all those years. But I am just one person, so I mostly cannot do more than make videos, review plans and papers and websites, and give some examples and advice. I am on Twitter(X), YouTube, ResearchGate, and Hackaday.io and I comment many places on the Internet as Richard Collins, The Internet Foundation.
I just wanted to share that microphones are not expensive. Those guitar pickups are fun and can be mounted to things to increase sensitivity. The SDR software also works with sound cards and oscilloscopes and that gives you nice FFT water falls and data tools. I am trying to build low cost, three axis, high sampling rate, time of flight, gravitational imaging arrays.
Filed as (Array methods for Audacity, SDRs and Javascript. Low cost array microphones and sensors)
Richard Collins, The Internet Foundation