I made something revolutionary. True white noise. It has pretty much the same frequency distribution as the old white noise where all samples are random, but it sounds quite different. This is because unlike in the old white noise, the frequency distribution is uniform at all times.
Note that a single sample is a uniform white noise, but it only lasts a single sample. To extend it, what I do is add it many times onto the sound at random positions. How often the single sample is added is a tradeoff between frequency uniformity and volume uniformity; I chose everything to match the human hearing. In the old white noise, every sample is random which causes phases of many frequencies to cancel out and the noise isn’t locally uniform at any point.
“In signal processing, white noise is a random signal having equal intensity at different frequencies, giving it a constant power spectral density.”
Ref. https://en.wikipedia.org/wiki/White_noise
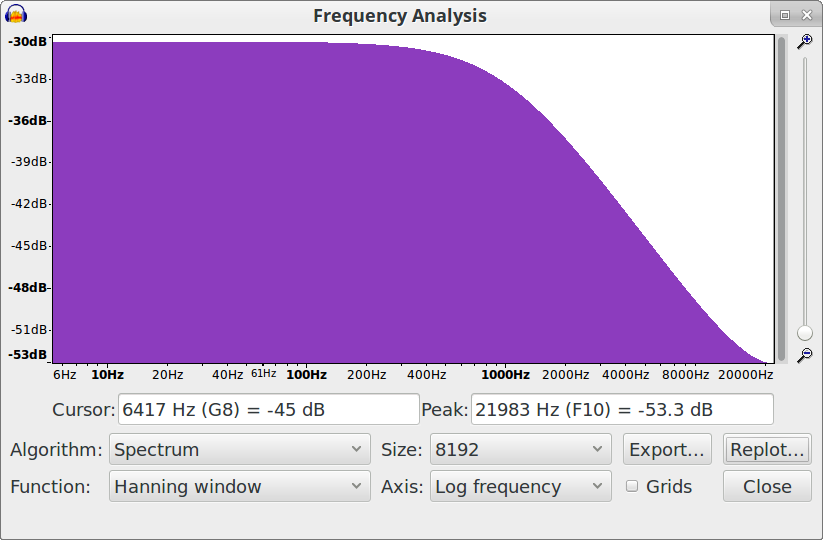
We can see why your generated “white noise” sounds different from Audacity’s white noise by looking at the spectrogram. In this image I have generated white noise amplitude -20 dB (about the same RMS level as your sample.
For testing the response of a filter, it can be useful to generate “white noise” as a single high amplitude sample on an otherwise silent track, like this:
We can see that the spectrum is uniform across the entire spectrum, but only momentarily:
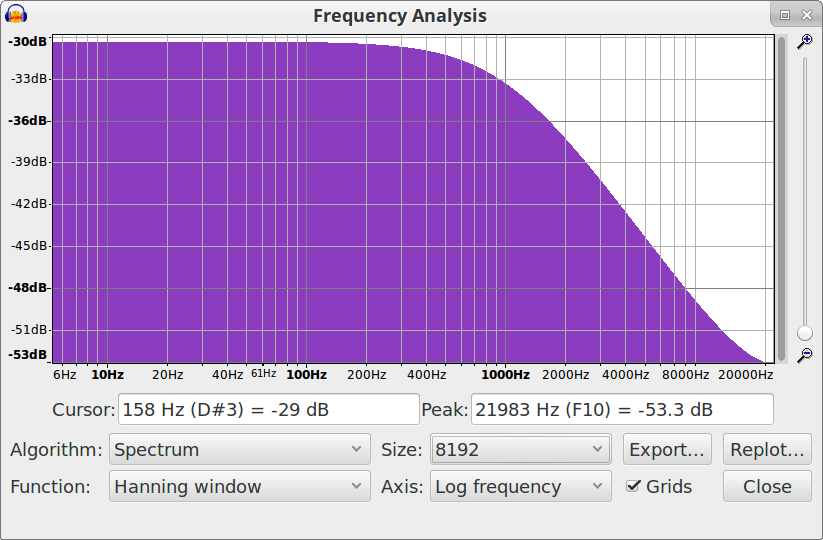
The usefulness is when we look at the spectrogram after applying a filter to the track. For example, here I have applied a first order Butterworth low pass filter with a corner frequency of 1000 Hz. Note how well the spectrogram matches the theoretical response for this kind of filter:
It clearly looks like your spectrograms follow the Audacity’s tradition of “overkill” time resolution. You didn’t even show the time scale. Here are my results:
Interestingly, my white noise sounds similar to the old traditional white noise when processed through paulstretch or Photosounder, because they use the old traditional white noise to generate sound from spectrograms. However, the high quality tempo change (set at 0) does preserve the difference as it makes the spectrograms in super resolution. (when old traditional white noise is slowed down by tempo, it decomposes onto its non-uniform frequency components, and when that is sped back up by tempo, it again sounds like the original)
The problem with making true white noise is the Fourier uncertainty principle. It is possible to add samples to even out the volume distribution, but the frequencies then often phase cancel out, making for an uneven frequency distribution. Similarly, adjusting the audio envelope is multiplying the audio by a variety of low frequencies which implies an FFT frequency convolution which also makes the frequencies phase cancel out. Or it’s possible to adjust the audio in the Fourier domain to even out the frequency distribution, but then the volume is uneven. And with superresolution methods such as the Reassignment spectrogram mode or the high quality tempo/pitch stretches, both of those issues are evident at all points of time and frequency for any white noise. There’s no escape from any of those issues. On one extreme is placing the impulse response only once; the frequency distribution is perfect but the volume distribution is very uneven. On the other extreme is placing the impulse response on every sample, but this leads to phase cancelling in such a way that only the infamous “zero frequency” remains.
A single sample is not any kind of noise, it just represents a voltage. Whether it is noise or not depends entirely on surrounding sample values. For example, if a single sample has a value of +0.5, then you are saying that it is “uniform white noise”, but what if the surrounding samples also have a value of +0.5? If a series of samples all have the same value, then it is silence.
The acoustic equivalent is to ask, “what is the frequency for a given air pressure at a moment in time?” This is unknowable, because sound only exists due to changing air pressure. The absolute air pressure at a moment in time says nothing about what sound may or may not be present.
Even if we have two samples (known air pressure at two moments in time), we still can say nothing about what frequencies may be present, because sound is defined by frequency, and frequency is determined by the rate of change. Sample values (or air pressure) that increases or decreases at a constant rate (a “ramp”) is also silent.
It’s true to say that a “unipolar pulse train” (which is what your audio sample is) has an average frequency distribution that is the same as white noise (constant power spectral density). It’s not correct to say that a unipolar pulse train “is” white noise, unless you redefine “white noise” to mean something different from how white noise is defined in the context of DSP. White noise, in the context of DSP, is defined as: “serially uncorrelated random samples with zero mean and finite variance”.
For each frequency there’s a phase. For your 0.5 volume 0Hz sine wave, each of the samples by themselves is a white noise, but the phase of all except 0Hz ends up cancelling and the overall result is a 0Hz sine wave. And due to the Fourier uncertainty principle it’s impossible to actually fine-tune a song by a spectrogram; for example, the shorter a sine wave is made, the broader its frequency span is, no matter what window is used. The same problem occurs with white noise.
A white noise is a sound where at all points of time is a uniform frequency distribution and at all points of frequency is a uniform distribution across the entire sound. But there isn’t really a way to generate a true white noise. The randomized algorithm isn’t true white noise; for example in a 48000Hz mono 16-bit random sound there’s a 2^768000 chance that a second is silence, so on average 1 out of 2^768000 generated 1 second samples of the “white noise” is a complete silence. Definitely not a uniform volume distribution at all.
A single sample in isolation doesn’t have a sample rate, so inferring frequency from a single sample is nonsense.
You are of course entitled to your opinion Piotr, though I would advise any forum visitors to ignore your fantasy rambling conjectures as they have little basis in reality and exhibit basic misunderstandings of the physics of digital audio. I shall not waste more time on this thread as you clearly have no interest in learning anything.
A single sample, when Fourier transformed, turns into a white noise frequency distribution. A raw single sample results in a single frequency row (analogous to a 1×1 image in bitmap image processing), yet zero padding makes it white noise distributed. Where that sample is placed in a bigger (say, 4096) window affects the phase of the actual frequency components. The samples combine into a window and all the phase cancellations add up to give the final result of a spectrogram for that window.
I’ll admit that I don’t understand this discussion but since white noise is random I don’t see any problems with the traditional random-number generation method. It can be “difficult” to get truly-random numbers from a computer and you can get into a philosophical discussion about randomness and maybe true randomness doesn’t exist… But, you CAN generate numbers that are “random enough” for audio white noise or for gambling purposes or just about any practical application.
for example in a 48000Hz mono 16-bit random sound there’s a 2^768000 chance that a second is silence, so on average 1 out of 2^768000 generated 1 second samples of the “white noise” is a complete silence.
True randomness SHOULD give you some zero-value samples (when digitized/quantized). At 16bits 1/65,535 samples will be zero, on average, regardless of the sample rate. It’s not “silence”… A non-silent sine wave has two zero-crossings per cycle (which may, or may-not be, sampled/quantized to integer zero). There is also a upper-value limit of 0dBFS imposed by the DAC and a Nyquist frequency-limit no matter how you generate the randomness.
[offtopic]If your RNG has a 1/65535 chance of 16 bits being 0 rather than 1/65536 chance, there must be something wrong with your RNG.[/offtopic]
I don’t mean a sample being 0. I meant an entire second of sound (48000 consecutive samples) is 0 with a probability of 2^-768000 (1 in 2^768000). And this obviously makes the noise non-uniform if that occurs. The proper FFT methods of building up a white noise of all frequencies would never generate something like this. Then 48000 consecutive samples being 0 is a chance of ±0 (1 in ±Infinity) because it isn’t white noise so it will never be generated by sensible methods, and neither will many of the regular structures that break the uniformity.
That’s understandable considering half of it is nonsense.
FFT is an integral, and the integral where the upper and lower limits are the same is zero, not “white noise”. There is a basic misconception being made that a single sample value has a spectrum - it doesn’t, it’s just a number.
When speaking about integers, lower limit is inclusive, upper limit is exclusive. A single sample has its upper limit 1 greater than its lower limit because it’s of the length 1. The upper and lower limits are not the same. A sound of length n will be distributed onto n Fourier frequencies. And with zero padding, this means the Fourier transform is sinc interpolated.
How likely is 1 in 2^768000? It’s not going to happen in anyone’s lifetime, or even in the universe’s lifetime. The universe is only about 14 billion years old, or about 2^33.7 years. You would need the lifetime of about 2^(768000-33.7) = 2^767966.3 universes to produce a second of silence in white noise.
It’s not true white noise if it contains a full second of silence.
Of course it’s not true white noise if it contains a full second of silence, therefore a uniformly random sound generator cannot possibly be a true white noise generator. A uniformly random sound generator has equal chance of generating any sound, while a true white noise generator ALWAYS generates a sound that’s uniform in both frequency and time.
I don’t understand why you insist that a uniformly random sound generator is not a “true white noise generator”. A uniformly random signal is white noise.
In discrete time, white noise is a discrete signal whose samples are regarded as a sequence of serially uncorrelated random variables with zero mean and finite variance;
On the other hand, the audio file you posted is not a sequence of serially uncorrelated random variables (I can see a lot of correlation between most of the samples), and it has a non-zero mean, so your “true white noise” is not actually white noise but some other type of noise (I don’t know if it even has a name).
A noise is a uniform volume sound of a certain frequency distribution. In white noise, the frequencies are uniformly distributed in the linear frequency dimension. A random sound does not guarantee this property.
And of course my sound, although it isn’t really true white noise either, has a non-zero mean. It needs to have a non-zero mean because a white noise includes every frequency, including 0Hz. And it needs to have correlation between samples because a white noise is defined by its spectrogram being uniform and every single pixel of the spectrogram implies correlation between samples.