I’m not an expert audacity user, so possibly this capability already exists and I just don’t know how to use it. I’m good with DSP in matlab, so I wrote my own audio splitter that separates tracks into tonal and transient subcomponents. This was very helpful for addressing a loud page turn in one of my favorite recordings. The page turn overlapped the music in frequency and time. But after splitting the audio into the subcomponents, the music was mostly tonal at the time, while the page turn was mostly transient. It was pretty easy to edit the subcomponents. Then I recombined them and realized the result I was looking for.
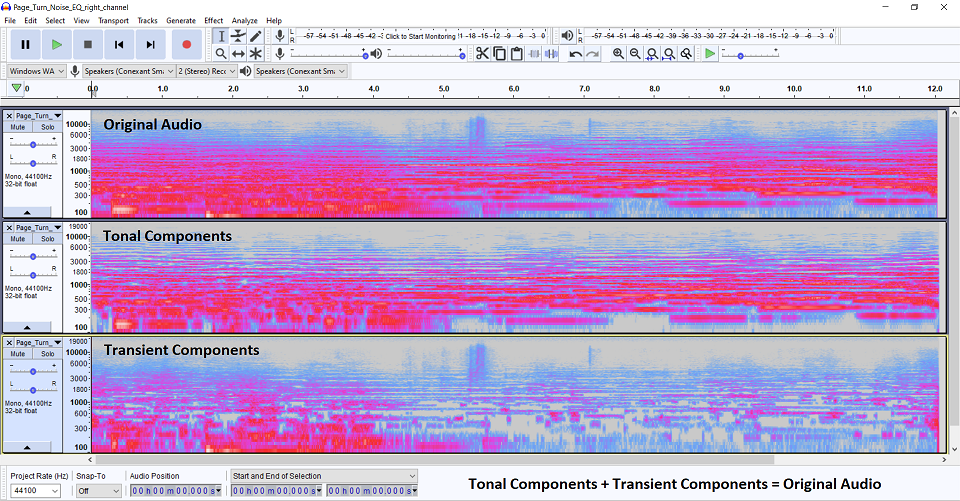
I’ve attached a picture that shows the original audio spectrogram at the top, with the tonal components in the middle, and the transient components on the bottom. The loudest part of the page turn happens at about 5.5 seconds in.
If this capability doesn’t exist, perhaps it could be added. I think it’s useful. People may also want to consider gaining transients and tonals differently, though I think there is a way people are already addressing that.
I don’t know if it works with Audacity but there’s a plug-in called “Physion” by “Eventide” that claims to do that. I’ve not tested because it costs $179.
If someone is selling something similar for $180, then it sounds like there is some demand for this capability. I would be happy to work with someone to help develop a (free) plug-in based on methods I can point them to from published literature. I don’t see myself tackling all the issues required to develop a plug in myself.
If you can point to the literature, and perhaps include your matlab code, that would probably allow me to asses how difficult it would be to implement in Nyquist (Audacity’s built-in scripting language). I’m not very familiar with matlab, but I may be able to work out enough to see what it’s doing.
In that description, it is applied to the range dimension of active sonar data. That’s not what we’re doing, but good detail is provided into how the algorithm runs.
In this paper, the same technique is applied to generating spectral noise estimates:
“Performance of split-window multipass-mean noise spectral estimators” by Jeffrey H. Shapiro and T.J. Green Jr.
I modified the concept of a multi-pass split-window normalizer to work on the spectrum of music samples by using window sizes and gap sizes that are “constant Q”, meaning they grow as frequency grows. Tonal components have high SNR compared to their local spectral noise estimate. Atonal components have lower SNR. I defined a gradient to split components that have moderate SNR, with some portion going into each component.
My algorithm operates in the frequency domain, on overlapping FFTs, and can be put back into the time domain by IFFT and overlap remove. These functions must be standard in Audacity, which already supports many spectral modification routines.
Audacity does use FFT (Plot Spectrum, track spectrogram view, Filter Curve EQ, …) but does not expose that functionality to plug-ins.
Audacity’s built-in scripting language “Nyquist” also has FFT / IFFT, but it’s a bit tricky to use. If you download the standalone version of Nyquist (see: Nyquist Info) there is an FFT tutorial in the included docs (If I recall correctly, it’s in the “Demos” section).
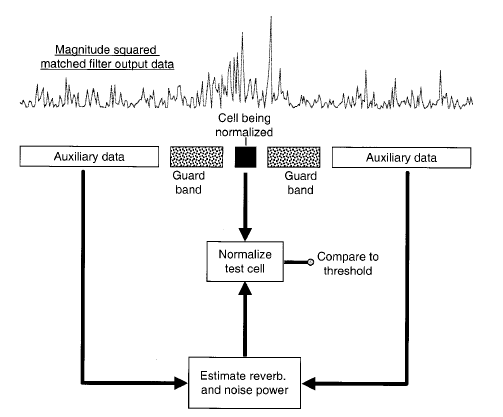
Thanks Steve. I’ll take a look at the documentation. In the meantime, I wanted to post this reference picture for how a split window normalizer works, to support the mathematical description provided in my earlier links:
It says it works on “magnitude squared matched filter output data”, but an FFT can be considered a matched filter for frequencies, so these really are analogous.
I eventually made a video that highlights a few ways to use the ability to split music (or noise) into tonal and atonal components. Removing transients from the atonal part, while not touching the tonal part allows for more thorough removal without ducking. Also, excised noise (from a noise reduction algorithm) can be split, and each component (tonal vs atonal) can be attenuated different amounts. I have found this technique extremely useful.