Hello fellow audiophiles,
First off: the issue I am going to describe here has certainly come up before but I could not for the life of me find the exact situation I am in. Plenty of people have a similar issue, but the fixes either don’t apply to my case or they would take way too much time if done manually. I have read the FAQ on the issue, with the same result.
“Why, pray tell, did you choose to post here anyway, if anything on the topic has already been said and you are just not happy with your options?”, you may ask. The problem I experience does not occur during playback before editing. What this means will become clearer in a second.
The issue:
I like to listen to radio play / audio book type stuff on the go. The publisher (in this case a subsidiary of Universal Music) sees it fit, to release these 30 - 60 minute long episodes cut to pieces of around 90 seconds. Each episode therefore clocks in anywhere between 10 and 30 pieces. For convenience, I always use audacity to join these pieces to a single file (reason: limited file tree structure on mobile device, excessive clutter on mobile device because each part would get listed etc.). With most publishers, this works perfectly.
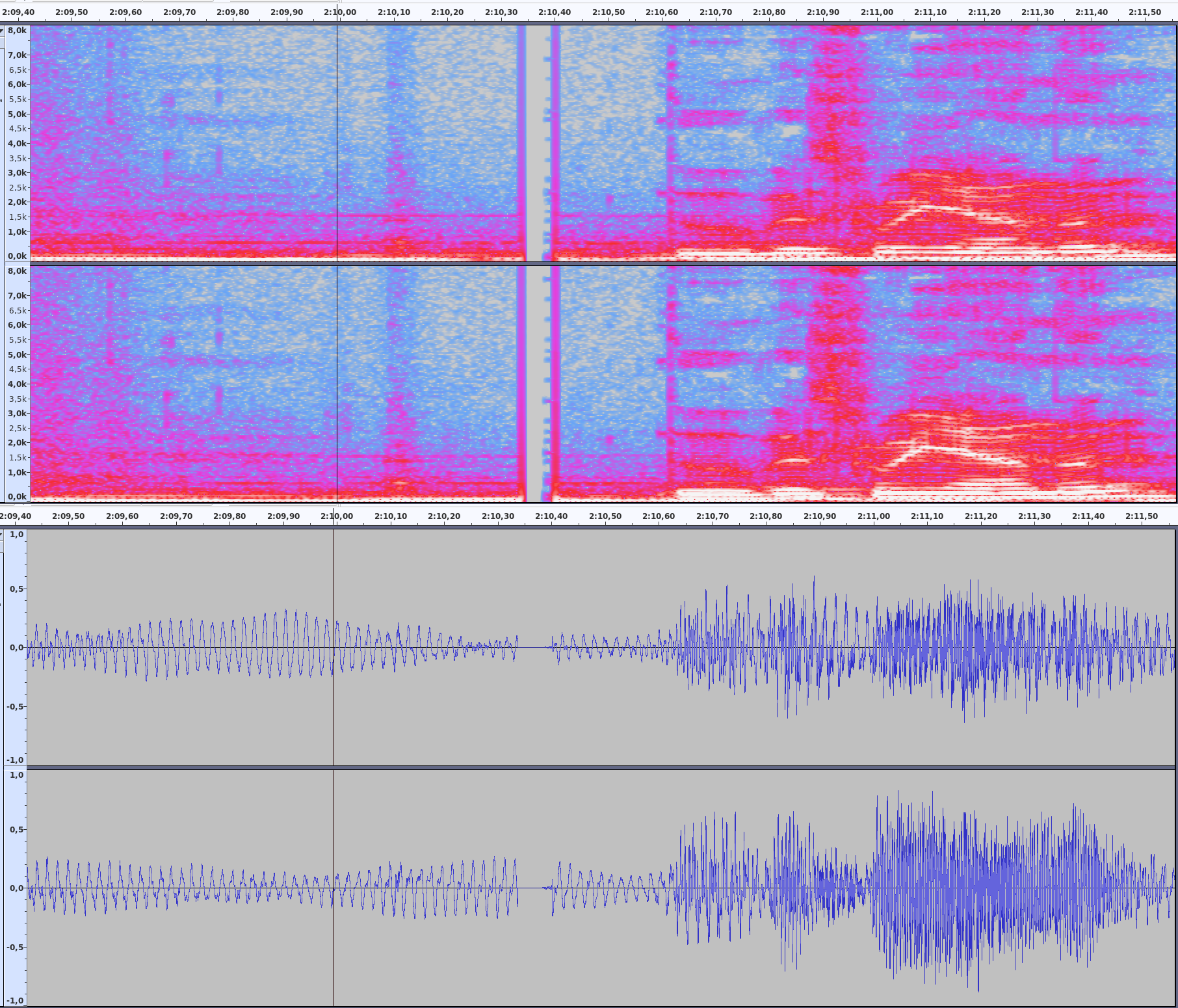
The stuff from Universal always has cracks at the seams on account of the mp3 pieces having silence at the end and the beginning, which does not merge properly. I tried truncating silence, I tried normalizing the tracks. No automated way I can find gives satisfactory results. The only way I have found is to merge the pieces and the manually edit each transition by properly merging the pieces at zero crossings on both channels if possible. That is obviously way too much work, especially considering that the publisher could simply offer a single-track version in the first place.
The thing is though, when I play the pieces as a playlist in a software player - while by no means perfect - the transitions sound a lot better than in audacity (as pieces or merged). The player seems to automatically remove the silence and splice the pieces together with mostly satisfactory results.
The question I now have is: How does it do that and can I emulate that behaviour in audacity, preferably with as little manual work as possible?
Any assistance in this matter would be much appreciated. I’ve been battling with this for years and the publisher will probably not budge on the “single track” front, for whatever reason.