I use Audacity to do minor processing of recordings taken of our sermons during church services. We have a number of babies and young children who can add a lot of unwanted noise. Even though the microphone is at the lectern a screaming baby is incredibly loud and often makes a few seconds of the recording useless - as well as rather unpleasant!
Can anyone suggest any ways I might lesson the impact of this, semi-automatically? I don’t have the time (or skill) to get into editing and micro-management, but maybe some EQ type methods might reduce the ear-pain somewhat. I’m by no means an Audacity expert, I just fumble my way through to get what I need each week.
Many thanks for any help - and is this the right sub-forum for my query?
Can anyone suggest any ways I might lesson the impact of this, semi-automatically?
The short answer is no. We can’t separate voices from each other in a mixed show.
You noticed the ear’s sensitivity to baby’s screaming. That’s not an accident. Ear sensitivity peaks around 3000Hz. I use “baby screaming on a jet” as the worst case, non-ignorable sound. Also see: fingernails on blackboard and rusty brakes.
There are microphone techniques. The head-mounted microphone can help.
There is a rule about getting some number of times closer to the performer than the interference and this can help with that spacing.
You can also get noise cancelling microphones. These are a little odd to use because they have to be close to the lips to work right, but they do work.
If you have unlimited money you can try the shotgun microphone route.
He’s holding about a $1000 there. Oddly, this may not be recommended if you’re in an echoey church.
There are exotic solutions, too. There is a way to wire conventional rock-band microphones such that you can hold two of them but only talk across one. That can offer almost complete environment cancellation with parts you can get at the music store.
That will work with most dynamic microphones. That’s Electro-Voice 635As in the picture. That extra thing in the leg of one microphone is a phase reverser. It exactly reverses the sound signal such that anything that appears on both microphones cancels out. It’s used by having the performer close-talk over only one of the microphones. One microphone is used jammed against your bottom lip.
The gray thing is an XLR “Y” cable. Both that and the phase reverser are good music store parts or Google your brains out.
There’s nothing subtle about this and the quality isn’t perfect, but it works. You can land a jet next to that and still be heard.
Cheers Koz. I don’t know we have the inclination to start making people wear mics, etc, so we might just live with it. The recordings are not used that widely, so it’s a low priority. I suppose individual screams could be identified and squished to avoid hurting the listener’s ears - I’m not bothered about removing them and leaving the underlying speech, just the huge volume peaks where a baby at the back of the room is recorded several dB louder than the speaker a few inches from the mic!
Given I don’t want to separate voices (sorry for implying this), might I get any joy running a filter around 3KHz - most of our speakers happen to be men so I don’t imagine their voices have much in this register?
most of our speakers happen to be men so I don’t imagine their voices have much in this register?
Nice try. Most intelligence or expression happens in the 3KHz range, man or woman.
There is the Noise Gate, but that is just going to poke holes in the performance.
I don’t know we have the inclination to start making people wear mics, etc, so we might just live with it.
We can’t judge how important the work is. If it’s super important, you get somebody to transcribe the performance and have the performer read it again after hours in a clear room. Edit in the clear sentences in place of the screamie ones.
…
…
Noise Gate might help. You can tune its activity to only reduce the volume slightly and you can choose which frequencies to affect.
Thanks Koz. I’ll look into that. We’re just a village church of 20-30 so recordings are really in case someone is ill and likes to stay in the loop. Background noise is acceptable, just annoying - these are not going to be shared publicly or anything like that so I’m just after any “low hanging fruit” to take the edge of the worst of it
Although one follow-up; does Audacity have tools to let me analyse a short bit of audio for frequency distribution (if that’s the right term)? e.g. isolate one shriek and see what frequency it is centred on, to know certain very narrow frequency ranges to try and address?
does Audacity have tools to let me analyse a short bit of audio for frequency distribution
Two of them.
You can turn the timeline into a rainbow that gives a rough indication of pitch distribution. Black arrow drop-down on the left > Spectrogram View. Pull the timeline taller to see more.
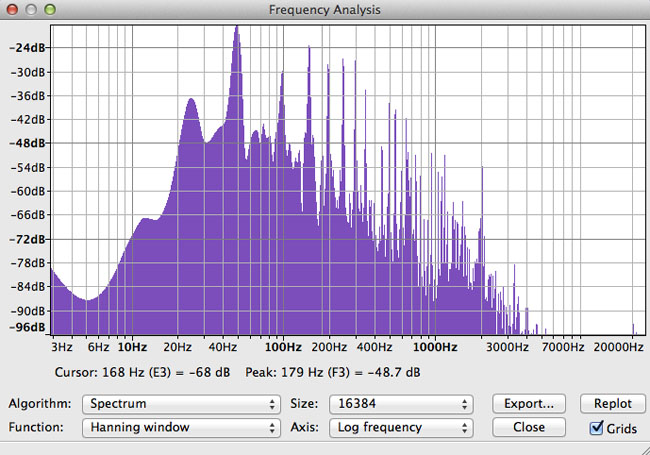
And the full-on Analyze > Plot Spectrum…
Spectrum gets more detailed as you grab and pull the window wider, and increase the Size setting. Smaller numbers are sloppy. Larger numbers can be like trying to identify one blade of grass.
That’s not a gift from the angels, either. You may easily find that there is a forest of different tones in that scream, and each tone has harmonics and overtones (double the frequency, four times, etc.)
There are postings from people wanting to know which single frequency they’re singing. It doesn’t work that way.
This is one single piano note (G, somewhere on the left).