First ever post here - please be gentle. Sorry for going over old ground (even Ive asked about this before!) but Im pretty new at this and just want to make sure Im doing it right. Im looking to see how other people do this and if what Im doing can be bettered.
Previously, I was using a 1210, Audio Technica AT95e cartridge, an old Kenwood amp and a Behringer UCA222 connected to a Win7 laptop to record. I was using Audacity to get the raw data. In Audacity, the levels were through the roof from the Kenwood amp and I had to turn the input volume right down in Audacity to almost nothing to prevent clipping.
After coming to terms with how poor the Behringer was, I bought a Traktor Audio 6 soundcard. So, swapped the Kenwood amp and the UCA222 out for the Audio 6 and went recording again. Everything else remained the same. Now Im getting pretty quiet levels, maybe about 50% of what I was getting previously. Most of my vinyl is pretty loud and so its not too much of an issue, but I do have some fairly quiet ones that I want to rip too. Im concerned that the low levels will mean lots of extra processing after the original recording and thats something I want to keep to a minimum if possible. I only want to cut out any pops and as little noise reduction, amplification etc as possible.
So, does anyone know of a better way of doing things? Perhaps there are some settings that Ive that will allow me to alter the levels going into Audacity. The input volume in Audacity is at maximum already.
About half the track height (-6 dB) for the loudest peaks is a good recording level.
For best quality ensure that the default bit format is 32-bit float (Edit menu > Preferences > Quality).
I make no claim to be expert at this, but you might be interested in my setup, whch seems to work reasonably well. I use a Rega P3-2000 deck with an Ortofon MC 15 Super II cartridge – that’s a moving coil cartridge, but with fairly high output for an MC. Ouput from the deck is fed into a NAD PP2 phono amp set to MC, and the line leve output from this goes into the analogue input of an M-Audio Delta Audiophile 2496 card in my Win7SP1x64 machine. Up to now I have set the samplig rate to 44.1kHz because I often want to make a CD, and I use Audacity ro create a project using 32-bit floating-point format, do any editing in Audacity, and then create a 16-bit WAV file. Editing comprises level adjustment to peak at -1 decibel (as recommended in the Audacity documentation), trimming of the ends of the recording, or of each track into which it is split, and whatever cleaning up I decide is desirable.
Here are a couple of thoughts on which I would welcome expert comments. I know from my very extensive experience of high-end digital photography that even if the final output file specification is fairly modest – a JPEG, for example, has only 8 bits per colour – any post-processing needs to start from a RAW file with much greater bit-depthe and resolution. I assume much the same applies to the post-processing of audio files. So:
First question: is there any benefit is samplig at a higher rate when recording and then down-sampling to CD rate after post-processing? And, if so, is it best to use a multiple of the CD rate, which in my case would be 88.2kHz, but could be 176.4kHz if I had a 192 rather than a 2496 card?
Second question: the M-Audio control panel offers no control over bit depth, so I assume the card always produces a 24-bit output – is this correct? I have read that Win 7 “fakes” the MME and Drirect Sound systems in a way that restricts them to a bit depth of 16, and Audacity requires me to choose one of these (I choose Direct Sound). Is the output from the 2496 getting munged by this on its way into Audacity, and if so is there any way to work round it (apart from not using Win7, which is not an option)?
Thanks for the input. Im considering adding the Kenwood phono amp back into my line up and also including the Traktor Audio 6. I feel like the input levels arent high enough and I cant see any way to alter these yet in anything other than Audacity. They are already maxed out there though. I always though that the less steps in the line, the less chance of losing audio quality, in basic laymans terms anyway, so thats the theory Ive been sticking to.
I agree with you too about editing. I was always told that you should record in the highest quality possible and then edit this file if needs be to chop off run ins and out, pops, crackes etc. That should keep your “master” copy as clean as possible to make future MP3 or CD quality verisons from. Obviously its almost a black art how to do this and there are so many different ways to do this. All tips on this greatly appreciated!
With regard to bit depth the case is similar for audio. Processing in 32-bit float format is far more accurate than i6 or even 24 bit. Unless you are only doing very simple cut/copy/paste type editing I would always recommend working in 32-bit float format.
With regard to sample rate the benefits are less clear cut.
44.1 kHz is about the minimum sample rate required for full frequency range. The theoretical limit to the audio frequency is half the sample rate. With a sample rate of 44.1 kHz the highest possible frequency that can be reproduced is 22.05 kHz. In practice it is a little less.
Human hearing is generally quoted as having a frequency range of about 20 Hz (a very low rumble) up to 20 kHz. This is for a child with “perfect” hearing. As we get older (beyond the age of about 8 years) there tends to be loss of sensitivity to very high frequencies, so for adults over about 21 years of age the upper frequency limit is commonly down to something like 16 kHz and by middle age the limit is frequently below 14 kHz.
With modern digital filters a 44.1 kHz sample rate can get pretty close to 20 kHz audio. 48 kHz arguably has an edge when it comes to high frequency response as it allows a bit more “space” between the theoretical and practical high frequency limits. Academic research indicates that there is no advantage in using sample rates above about 80 kHz for audio.
The argument for using 44.1 kHz throughout the production process is that no resampling is required.
The argument for using 48 kHz is that a frequency range up to a full 20 kHz can be achieved without pushing up against the practical limits of filter technology. The downside is that the audio needs to be resampled for audio CDs which may cause some quality loss, though in practice the quality loss is pretty small.
The argument for using 88.2 kHz for production is that it has the advantage of easily being able to reproduce frequencies up to 20 kHz, and resampling is simply a matter of halving the number of samples, so the resampling can be done losslessly. The down side is that there is double the amount of data as there is for 44.1 kHz, which puts more processing strain on the system, double the disk space requirements and double the amount of data throughput. It also assumes that the sound capture hardware is able to work internally at 88.2 kHz. If the hardware is actually working at a standard rate of 44.1, 48 or 96 kHz then the claimed advantage is lost. (The 2496 card specifies “Supported sample rates: 8kHz to 96kHz” but I’ve not found any documentation that specifies whether oddball rates such as 88.2 kHz are handled directly in hardware or by resampling from one of the more standard rates).
Another consideration is that the audio source may not have frequencies anywhere near 20 kHz in which case the only audio data in the extreme high frequency range will be noise.
Unlike bit-depth, the sample rate remains unchanged for most audio processes so the sample rate rarely has any impact on cumulative errors through processing.
If the final format is to be an audio CD, my recommendation would be to work in 32-bit float at 44.1 kHz throughout the production process.
There may be some marginal benefits to using 32-bit float at 88.2 kHz IF the recording hardware supports 88.2 kHz natively and the source material has a frequency range up to 20 kHz and the rest of the recording hardware is able to accurately reproduce frequencies up to 20 kHz and you have some 8 year old children that are interested in the finer points of audio production. Note that for the vast majority of music the level in the 18 to 20 kHz range is usually so low as to be completely inaudible even to people fortunate enough to have perfect hearing.
As a brief anecdote, there was an Audacity user that visited the forum who was using an ultrasonic transducer to record the echolocation sounds of bats. For that user, not only was a very high sample rate justified, it was essential for recording signals in the 80 kHz range.
M65: Nothing to lose by trying out different combinations, for sure. Please share the outcome. The Traktor 6 is advertised very much as a DJ device; to what extent in your experience do the phono preamp/equalisation stage and the A/D and D/A conversion deliver audiophile standards?
Steve: Many thanks for such a detailed and helpful reply. Much appreciated. Perhaps it is time for me to come clean: as I said, I am not an audio expert, but I am, or used to be, a mathematical statistician with, among other things, a good knowledge of time series analysis (yea, even unto window carpentry, on which I see that Audacity has gone to town in the spectrum analyser!). So your reply is meat and drink to me, and helps to clarify what I was really concerned with in my first question. Fact 1 (a commonplace): our hearing runs out of steam at about 20kHz, or less as we get older. Fact 2 (specific to my setup, but probably also to many more): my cartridge appears (on the basis of looking at a spectrum of what it produces) to run out of steam at about the same point, not only producing no signal but also no noise that I can see in the spectrum above around 20kHz. Inference (the theory): so no point in worrying about anything at higher frequencies. Problem: that’s all fine in a linear world, but editing (noise removal, for example, using a noise-gate approach as in Audacity) is not necessarily linear. So, in principle, at least, a first non-linear editing step might park some stuff in the previously empty part of the spectrum above 20kHz and a second might retrieve it into the audible range, either for good or ill, if the headroom above 20kHz was there in the first place. Can this be seen to happen, and if so is the effect immaterial, malign, or benign? Unless it is benign, there is indeed no point in starting at anything beyond 44.1 kHz or 48kHz, depending on the desired final sampling rate.
I can’t quote chapter and verse, but anecdotally from sources in which I have some confidence I understand that in a properly conducted double-blind experiment subjects cannot distinguish better than random between playback of initially high-sampling-rate material played at different rates at or above 44.1kHz; if they could, presumably some nonlinearity would have to be involved in the playback process or in the ears of the subjects.
As you say, all the evidence is that bit-depth does make a difference, and as I said in my first post I always work with projects using 32-bit floating point, as recommended by you and by the Audacity documentation. My second question was whether the 24 bits coming out of the card really are being delivered to Audacity under Win7SP1. Is there a simple way that I can test this? Incidentally, I would be very surprised if the sampling rates on an a card that claims audiophile quality (and costs accordingly) were not real, but I have often heard it said that older soundcards resampled everything to a common, and perhaps not very high, rate. These days most motherboards have built-in multi-channel sound (often Realtek) but I don’t know what really happens about sampling rates, and I would be surprised if the D/A and A/D conversion was all one might wish for.
I enjoyed the example about bats. Presumably you know Flanders and Swann’s A Song of Reproduction?
It is possible for that to happen and if it does then it is most definitely malign. Fortunately should never occur in practice.
An example of how it could occur is through the use of a badly written modulation plug-in effect.
With your mathematical background you may enjoy this example:
Amplitude Modulation (AM).
If you take an audio signal and vary the amplitude up and down, that is a simple example of amplitude modulation.
Let’s say that adjust the level cyclically from full volume, to silence, to full volume, to silence… at a rate of one cycle every second - we can then say that we are modulating the amplitude at a rate of 1 Hz. The waveform will look something like this:
Now let’s say that we increase the modulation frequency to say 500 Hz.
For the sake of clarity I’ll use a 1 kHz sine wave rather than the music track, then we can look at the spectrum:
What has happened is that we have the product of the two waves which has three sine components equivalent to the original 1000 Hz and the sum and difference of the frequencies. 500 Hz, 1000 Hz and 1500 Hz.
Now let’s make it more extreme.
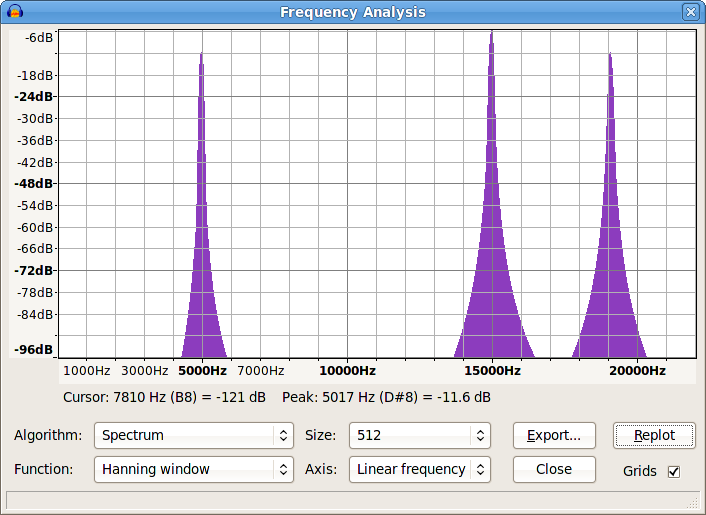
Here’s a 15 kHz sine tone modulated at 10 kHz. I’ve switched the spectrum to the linear scale to make it easier to see:
We have a peak at 15 kHz (the original tone) and at 5 kHz (the difference of the frequencies) as expected, but what is that third spike? It’s at 19.1 kHz
What has occurred here is that the modulation generated a tone at 25 kHz, but as the track has a sample rate of 44.1 kHz the highest frequency that can be represented is 22.05 kHz (known as the “Nyquist” frequency). The 25 kHz signal should not be present, but because I took no steps to prevent it there has been severe aliasing distortion.
In effect, the 25 kHz frequency has “bounced back” into the audio range (very bad). The 25 kHz has interacted with the 44.1 kHz sample frequency to produce a frequency at 44.1 - 25 = 19.1 kHz
A well designed modulation effect should prevent aliasing from occurring by limiting the bandwidth to less than half the sample frequency.
No I didn’t, but I’ve just looked it up on YouTube. Very apt
I’ve been perfectly satisfied with my Behringer UFO-202. There was no discernable difference between it and my Dynaco PAT-4. The overall hiss level was a bit higher, but it did not have the hum present in the Dynaco. The frequency responses were slightly different, but which one was correct? In any case, the hiss level is overwhelmed by the vinyl surface noise, and I’m happy to be rid of the hum from the PAT-4.
If the UCA-222 was giving you grief, is it possible that is was being overloaded by the output of the Kenwood amp? Turning down the level in Audacity won’t help if the UCA-222 is being overloaded from the Kenwood (in fact, I’m surprised you were able to turn down the input level in Audacity as Audacity does not try to control the input level from a USB device).
The UFO-202 gives me peak recorded levels around -9 dBFS which I’m quite happy with. No chance of clipping and lots of room to fix clicks and pops.
Sorry if I took this off-track, but I found it a very interesting excursion. Many thanks again for your time and trouble, Steve (glad you enjoyed F&S!). I’ll pursue the Win7 and hardware queries elsewhere to avoid further diversion from the OP’s topic.
If I can turn this question around a bit, if the final destination for the recording is a computer playing back through a reasonable quality (Audiolab) DAC capable of 96k , what would the ideal sampling rate? (I am assuming of course that my Xitel Inport hardware is capable of handling 96k for recording.)
Whatever sounds best, but if they all sound equally good then you have a choice between saving disk space and using small number or showing off and using big numbers. Big numbers are not necessarily better, but they sound more impressive. If a device handles 24 bit 48 kHz superbly well and handles 24 bit 96 kHz moderately well, then 24/48 will be better.