I am editing a 1 hour seminar and the person speaking must have had a phone in his pocket that sounds like it was beeping because of a low battery. Like me, he’s older and so probably didn’t notice the beep while he was speaking. The beep has a fairly regular time frequency, of about every 30 seconds, give or take a few seconds. I can get a clean noise profile of the beep, but when I apply the noise reduction to the whole track, quite a bit of non-beeping sound is removed too. So, … I was going to get the clean noise profile and then as I listen to the track, apply the noise reduction effect only at the point in the audio where I notice a noise.
Seems like the brute force approach, but I’m not sure of any other way to do it. Has anyone else dealt with this type of issue and do you have a better approach?
Also, once I get the noise profile, I’m assuming it remains in some sort of “noise profile memory” until I get a different noise profile. Is that correct?
That’s not what we mean by consistent noise. Consistent Noise is air condition rumble or computer fan whine.
Your noise is more like trying to suppress jets going over or trucks going by. A way different problem (as you’re finding out).
Do you remember spy/mysteries where they would turn on a radio in the room where they were planning some dare-devil action to keep people from listening in? Only some of that is Hollywood. Constantly changing noises are still nearly impossible to remove.
And it’s for an odd reasons. The tone isn’t pure. It’s designed to get your attention and contains multiple different tones similar to “baby screaming on a jet.” That would be bad enough, but the tone also stops and starts. Each time it does that it generates even more different tones through modulation effects. That’s why a lot of the show gets damaged when you try simple noise reduction.
So if you got anything to work, you win. I would put your chances of getting an automatic solution at zero.
This audio stuff gets more interesting as I encounter more issues. When I started several months ago, I was just chopping stuff out and adjusting stuff here and there. But now, it’s getting more interesting as I find out more about it.
Which is leading me to a lot of questions about how we (people) process audio (hearing), and how the digital representation of audio works. If anyone has a link to something that would give me some more insight into it without getting too technical, that would be helpful. The things I’m thinking of are like the following:
If our voice and a noise happen to match up exactly for a short period of time, which one do we hear?
Does it get louder?
Do we selectively hear the part of the combined noise based on what part of the two noises we were concentrating on before they “matched up”? For example, if we are having a conversation does our intellect fill in what we think we should hear based on the conversation even though it happened to coincide exactly with a noise?
What about if our voice and the noise are different in phase by 180 degrees, would everything go silent?
And in the digital representation of it all, what happens to the individual samples in each case?
Should I play around with two different noises/sounds and do a mix and look at the resulting samples compared to the original?
Just looking for some direction so I don’t spin my wheels chasing this down a rabbit hole.
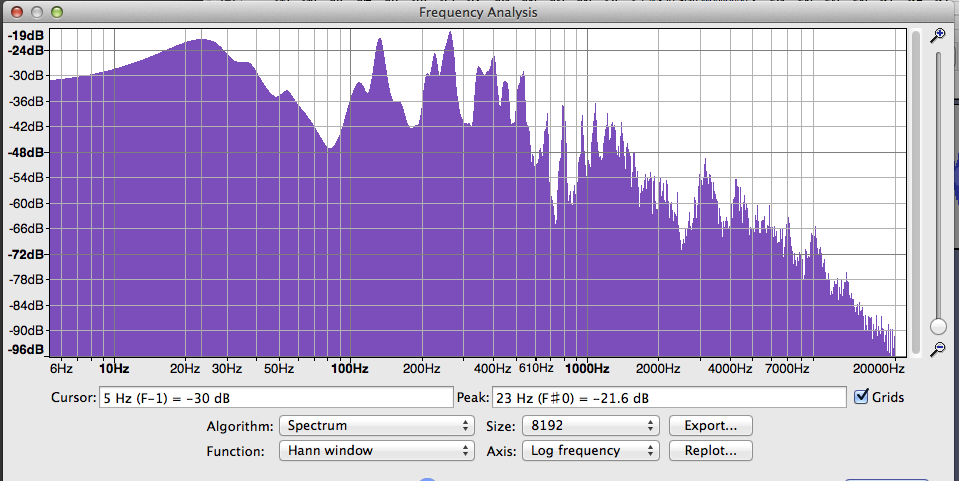
There is no match up exactly. Voices are an insane collection of different tones. This is an analysis of a spoken word or two. Each of those blue peaks represents a different tone roughly labeled by the numbers along the bottom. Many thousands of them.
But the more interesting answer is we would hear the voice, but possibly not the words. The brain is good at turning trash into meaning. Three people listening to the same distorted voice will hear different things. Also see: zodiac signs. Obviously, those three stars look like an archer, right?
Does it get louder?
That depends on the sounds. There is a movement to stop using plain waveform size—RMS—for measuring loudness and start using LUFS which takes into account your ear working much better at some tones than others. See: baby screaming on a jet and fingernails on blackboard.
does our intellect fill in
Yes. Your ear works in the subjuntive. It’s the words that would have been there had they been clearer. That also gives you the hilarity of getting people to tell you what they think song lyrics are just by listening.
What about if our voice and the noise are different in phase by 180 degrees, would everything go silent?
Yes. Or as silent as the sound channel allows. Make an exact copy of some sound track > Control+D (duplicate). Select one and invert it. Effect > Invert. Listen to both of them together and system reverts to electronic background noise.
There is an adapter cable I call the Devil’s Adapter.
It suggests you can easily connect an XLR microphone to a computer soundcard. What it actually does is create a stereo show (two blue waves) with your voice exactly out of phase left to right. It only sounds a little weird if you’re listening in stereo (voices coming from behind you) but when played on a mono system which tries to mix them, the voice vanishes. So of the four clients that got your show, one of them claims to have received a dead silent track. …!!! That last one is listening on a mono speaker system, a stereo system that accidentally mixed to mono, or their phone.
If you work on the forum enough, you get to recognize the magic. “What kind of microphone are you using and how do you have it connected?”
Sound cancellation also fails in the wrong places. You can’t make one person sing the same song twice, invert one, and have it cancel. You also can’t cancel out an alert tone by casually recording it twice. Nice try, though.
individual samples in each case?
Digital throws some interesting curve balls into the system. The digital system assigns numbers to the analog wave. You can see the assignments if you magnify an Audacity show enough.
Audacity works internally at a super high quality bit depth to keep distortion down when you’re doing effects. The problem comes when you have to make a normal sound track in the world you and I live in. There can be conversion errors, so Audacity very slightly scrambles things so the errors don’t line up and become audible.
This gives another common forum post. A scientist wants to know why their sound experiment didn’t work out exactly as theory would have it. Because they don’t have the sound file they think they do. Audacity will always go in the direction of a good sounding show, not one that’s scientifically perfect.
Audacity can’t split a mixed show apart into individual voices, instruments, and sounds. Correct me, but that’s your problem.
Thanks for the detailed response - hearing all of the ins and outs associated with audio processing shows me how much there is for me to learn. I’m going to keep looking into the math and theory behind it.
I have a math degree, with a minor in physics, and ended up programming in my early career (Cobol) and still do some programming in Power Basic to provide myself with various actuarial calculations I need for my business. So this sort of thing has always interested me.
You asked about the microphone I have - I have a Yeti Blue connected via USB. But since most of what I do is editing of seminars, I don’t use the microphone that often.
I ended up purchasing a gaming laptop (even though that’s a pastime I never really got into) so that I would have a faster processor and graphic card as my previous laptop really processed this audio stuff quite slowly.
At any rate - I’m enjoying learning and seeing what others are doing via this forum.
There is a caution there, too. I think it’s still true Audacity can only use one core of a multi-core machine, so that’s not a place to look for stunning speed increases. You will get neck-snapping acceleration by changing from a spinning metal, mechanical hard drive to a solid state drive. SSD. It will seem to be a bad trade-off because SSDs can have a lot less memory, but the speed increase is amazing.
One of the Systems people had nearly my exact laptop except I had an SSD and he had spinning metal. I needed to do a process on his for a job and I though it was broken. It was like wading through deep snow. “No,” he said, “That’s normal.”