I have a song to play as a Karaoke
I know that is posible to eliminate the voice with Audacity (Effect, Invert, …)
But it is possible only tu reduce the volume of the voice a little bit, not eliminate 100%?
Thanks
Xavi
Effect, Invert, …
Or, you could use the Audacity pre-baked tools: Effect > Vocal Remover and Effect > Vocal Reduction and Isolation.
Maybe that last one has something you could use.
http://manual.audacityteam.org/man/vocal_reduction_and_isolation.html
Koz
Thanks
- In the option Effect + Vocal Remover (for center panned vocals) which REMOVER CHOICE I have to choose? And what FREQUENCY band ?
- In EFFECT I can not find the Effect > Vocal Reduction and Isolation option. Where can I find it?
Thanks
Which Audacity do you have—all three numbers?
The better Vocal Management tools are only available in the last one or two versions of Audacity. Audacity 2.1.3 is current.
http://www.audacityteam.org/download/windows/
Koz
What song is it? It’d help us know whether or not it can be done. Lots of songs these days tend to be laced with reverb and other fancy effects, along with loads of layered vocals. In a few rare cases I’ve had it work satisfactorily. I personally don’t use the built-in vocal remover much, as I use a Python script which does the job and keeps the results in stereo, and usually can remove the vocals extensively and it works on mono tracks, as well. I’ll link you a song I processed through this script (the vocals are almost entirely gone, but keep in mind this particular song has a vocal track with no reverb (or very little)).
The “Vocal Reduction and Isolation” effect in Audacity keeps the result in stereo, (unless you select the “Remove Center Classic: (Mono)” option).
http://manual.audacityteam.org/man/vocal_reduction_and_isolation.html
It does not work with mono tracks though.
What’s the Python script that you are referring to? Is it open source?
Hi. It’s called “separateLeadStereo” and can be found on Github:
https://github.com/wslihgt/separateLeadStereo
It takes some work to get up and running under Windows (Install Python 2.7.6, set up PIP and install numpy ,scipy and matplotlib dependencies). You absolutely must use a 64 bit edition of both Windows and Python since it won’t work properly with a full song on 32 bit systems. You can simply download a copy of the source zip file and open a CMD window in the “separateLeadStereo-master” folder and do this:
python separateLeadStereoParam.py wavfile.wav
Paste the song into the folder first (must be WAV. not MP3) and replace wavfile with the file name. It will take a good amount of time to process a 3 minute song (20 to 25 minutes) and when done it will spit out 4 different files: acc and lead, and 2 others with the name ending in VUIMM. From what I can tell, VUIMM grabs the consonants better, but introduces more drum bleed with the vocal estimation (lead) and the instrumental (acc)'s drums will be preserved less than the normal, non VUIMM estimations. It works on even the muddiest recordings… I’ve used it on mono tracks, and old low-fi pieces. I hope this helps.
Thanks jh90s, very interesting.
It’s quite easy to get it running on Linux, but you’re right that it is extremely slow.
From my short test, I’d not say that the sound quality was ‘good’, there are some very weird sounding noises coming through on the vocal isolated track, but considering how technically difficult the task is, I agree that it does a creditable job.
Looking at the paper from which the algorithm is derived gives interesting background to how it works and what can reasonably be expected. In particular:
In this paper, we consider musical pieces or excerpts where such a leading instrument is clearly identifiable and unique. The latter assumption particularly implies that the melody line is not harmonized with multiple voices. We assume that its energy is mostly predominant over the other instruments of the mixture. These can thus be assimilated to the accompaniment. This implies that we are tracking an instrument with a rather high average energy in the processed song and a continuous fundamental frequency line. In this section and in Section III, the parameters mainly reflect the spectral shapes and the amplitudes, in other words the energy. In Section IV, we focus more on the melody tracking and therefore propose a model for the continuity of the melodic line.
It would be interesting to know how much quicker the algorithm could run if written in C/C++, but there’s some hellishly complicated processing involved, as indicated by this extract (below):
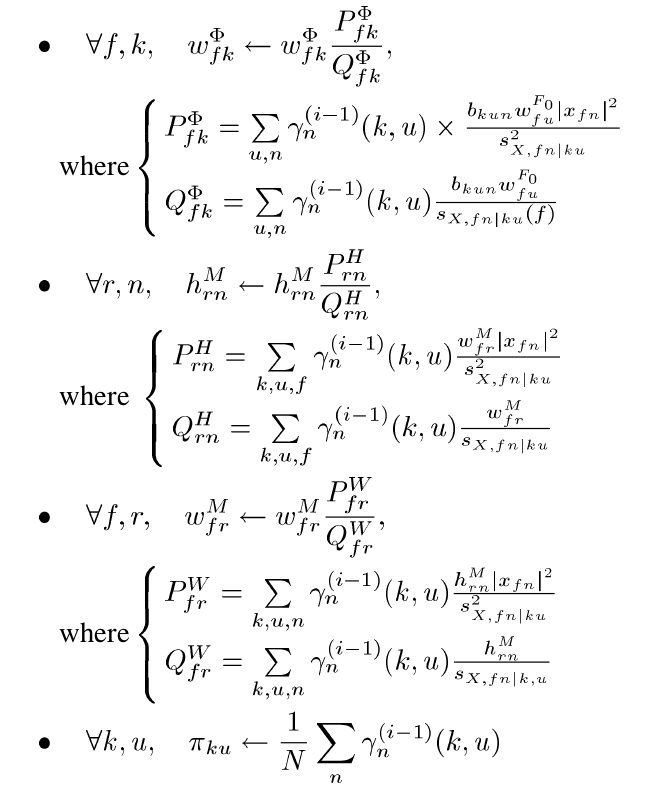
Steve, my brain exploded when I looked at the image you attached. haha. I tried to get it running on Linux, but failed to do so. What distribution did you use? I tried to get it running on Ubuntu MATE 17.04 and it gave me an error. There are a few parameters in the main script “separateLeadStereoParam” which can be adjusted which can allow for better results, but expect to wait even longer (understandably). The script is extremely accurate, considering the fact that it’s automatic with no initial input, and I’ve actually isolated a vocal track before and was able to use it on an (unreleased) mashup between a song I remade and the extracted vocals.
Oh, and as for the parameters: You can either edit the default amount of iterations it does (default is 30) in the script itself, or you could use a flag which you can add when you type the script name and the wav file
python separateLeadStereoParam.py wavfile.wav --nb-iterations x (x being the number)
From what I can tell, iterations are, in simple terms, the amount of times it goes through the mix to grab the calculated estimations. I had a song process with it set to 150 iterations, and it gave better results, but I had it process when I went to sleep and I listened to the results when I got up.
There’s 1 more flag which I’m unsure of what it does, but it improves separation results as well:
–numFilters (It’s defaulted at a measly 10. I had it set to 40, and it gave better results)
On a side note: Be sure to normalize any recordings you want to do this with (-1.5 to -2 dB) as it has a bit of a glitch where it will noticeably clip the drum hits in the _acc estimations (both the normal one and the VUIMM)
Xubuntu 16.04.1 64-bit
Yes thanks, I got the list by reading the instructions ![]()
-h, --help show this help message and exit
-v VOC_OUTPUT_FILE, --vocal-output-file=VOC_OUTPUT_FILE
name of the audio output file for the estimated solo
(vocal) part. If None, appends _lead to
inputAudioFile.
-m MUS_OUTPUT_FILE, --music-output-file=MUS_OUTPUT_FILE
name of the audio output file for the estimated music
part. If None, appends _acc to inputAudioFile.
-p PITCH_OUTPUT_FILE, --pitch-output-file=PITCH_OUTPUT_FILE
name of the output file for the estimated pitches. If
None, appends _pitches to inputAudioFile
-d, --with-display display the figures
-q, --quiet use to quiet all output verbose
-n, --dontseparate Trigger this option if you only desire to estimate the
melody
--nb-iterations=NBITER
number of iterations
--window-size=WINDOWSIZE
size of analysis windows, in s.
--Fourier-size=FOURIERSIZE
size of Fourier transforms, in samples.
--hopsize=HOPSIZE size of the hop between analysis windows, in s.
--nb-accElements=R number of elements for the accompaniment.
--with-melody=MELODY provide the melody in a file named MELODY, with at
each line: <time (s)><F0 (Hz)>.
--numAtomFilters=P_NUMATOMFILTERS
Number of atomic filters - in WGAMMA.
--numFilters=K_NUMFILTERS
Number of filters for decomposition - in WPHI
--min-F0-Freq=MINF0 Minimum of fundamental frequency F0.
--max-F0-Freq=MAXF0 Maximum of fundamental frequency F0.
--step-F0s=STEPNOTES Number of F0s in dictionary for each semitone.
I was thinking of doing the same as an experiment - probably will when I get round to it.
Unless a C/C++ version could massively speed up the processing, I don’t think this will be a viable candidate for a new Audacity effect, but good to know it’s out there. Due to the complexity of the algorithm, I doubt that even a C/C++ version would be quick enough, and it would be a lot of work even to find out what order of speed increase could be expected (unless someone has already coded a C/C++ version).
Thanks for posting the instructions here! Btw: What did you do to get it working on xubuntu? I tried it and it keeps giving me a vague error which says:
Traceback (most recent call last):
File “separateLeadStereoParam.py”, line 1195, in
main()
File “separateLeadStereoParam.py”, line 633, in main
window=sinebell(windowSizeInSamples), nfft=NFT)
File “separateLeadStereoParam.py”, line 123, in stft
data = np.concatenate((np.zeros(lengthWindow / 2.0),data))
TypeError: ‘float’ object cannot be interpreted as an index
All i did was I installed pip, and the 3 dependencies and tried to run the script.
pyton-matplotlib 1.5.1-1
python-scipy 0.17.0-1
python-numpy 1:1.11.0-1
(plus dependencies pulled in by the above)
separateLeadStereo-master from the zip file https://github.com/wslihgt/separateLeadStereo/archive/master.zip
EDIT: I got it to work. Man, it is unusually slow. It running on Windows seems to be much, much faster.
I didn’t attempt to time it, (just left it running while I did something else), but yes it is extremely slow.
Python is not generally recommended for heavy number crunching, but Scipy and Numpy do help a lot. I presume that the Windows version makes use of some optimisation(s) that are not available on Linux. Even a small optimisation can make a big difference if it is used a lot, and this algorithm is clearly ‘looping’ through the same or similar processes a lot.
I don’t use Python very much, but I can give an example in Audacity’s Nyquist language to illustrate how much difference in performance can be achieved through differences in implementation. Using the Nyquist Prompt effect on a mono track, three ways to find the peak level:
;version 4
;; Slowest version
(let ((peak 0))
(do ((val (snd-fetch *track*)(snd-fetch *track*)))
((not val) (linear-to-db peak))
(setq peak (max (abs val) peak))))
;version 4
;; Faster version
(linear-to-db (peak *track* ny:all))
;version 4
;; Fastest version
(linear-to-db (get '*selection* 'peak))
Here’s the result of a test where I expected a reasonable amount of separation.
The files were originally 16-bit WAV, which I’ve converted to Ogg format to reduce the size so that I could upload to the forum.
I’ve converted all processed files to mono to reduce file size and normalized to -3 dB.
The “original” file remains as stereo.
The original extract:
Results of “separateLeadStereo” script, default settings. Processing time on my (fairly fast) Linux laptop was greater than 5 minutes.
I also tested with settings of
--nb-iterations=50 --numFilters=20
but the results were not better. If anything, the isolated vocals sounded marginally worse, so I’ve left them out of this comparison.
Vocal Isolation:
Vocal Reduction:
Vocal isolation using Audacity’s “Vocal Reduction and Isolation” effect.
Settings: “Isolate Vocals”, 10, 200, 8000
Processing time: less than 2 seconds
Vocal reduction using Audacity’s “Vocl Remover” effect.
Settings: “Remove frequency band”, 200, 7000
Processing time: Almost instant.
I cannot help but mention I’ve tried that exact song before, and unsurprisingly it struggled greatly. You know what actually might improve the separation results a bit for the verses is if you were to change the minimum fundamental frequency number so it’s lower, but for all I know Glen’s voice is in the same range as the minimum number is. It seems that if the vocal harmonics aren’t prominent in the spectrogram, or if you’ve got some heavy synths going, then it’ll usually give a very… interesting result. haha. That surprises me that your results weren’t as good with the filters bumped up… I’ll try the same part of the same song (I have it, but it’s an Amazon MP3 and it sounds more muddy than yours). I personally suggest doing a small snippet of whatever song it is you’d like to separate and just tweak the parameters and see how (or if) it’ll do any better, and hope for the best and do the full thing if you’d be up for it! That vocal removal file you attached at the end was extremely good for what it is! Sure, there’s a fair bit of reverb left in, but the strings and other stuff drowns it out.
There is one aspect that I think I’ve underplayed in my “review” so far, and that is that “separateLeadStereo” can work with mono recordings, which neither the “Vocal Reduction and Isolation” or “Vocal Remover” effect can manage at all.
Do you have any examples where the “separateLeadStereo” effect excels? If so, perhaps you could post a short sample. I think it could be useful for others if they have a rough idea of what they can reasonably expect from different types of material with the various tools that are available.
Here’s a sample of a stereo mix which worked so impressively that I uploaded the instrumental estimation over on YouTube (I linked it back on page 1. The only modifications I made is I added the instrumental portions to it so it goes between the original and the estimation). I added the VUIMM estimations as those are the "better "ones, so to speak.
As for a song which didn’t yield anything which could be used, here’s one which I tried just now. I truly wished this would’ve turned out great as no official instrumental exists, but I can’t exactly fault the algorithms for not being able to track the vocals all that well, as this track has a lot of guitars and other stuff going on.
That pretty well shows the range doesn’t it ![]()
Here’s an Audacity version of Reptile: