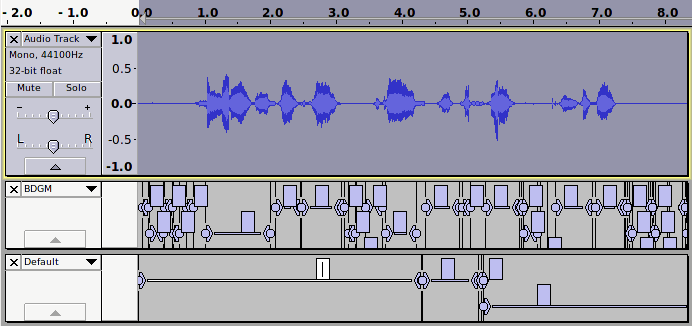
Record some of your speech. Can you instruct Audacity to separate vowels and consonants?
So far it’s just my own exercise in understanding snd-fft, but it might evolve into something useful for my work with spoken word. Several knobs to play with, I hope the dialog is self explanatory.
The default settings seem to do a pretty good job of separating “th” or “f” from the rest of the sounds. It seems 90% below 750 Hz is pretty good to separate b, d, g, m, n, ng from the rest.
Crude but promising. Not bad for a few days’ work and just a couple pages of code. Am I reinventing somebody’s wheel here? PhonemeFinder.ny (6.43 KB)
What did you say and what were your settings? There are several dials to fiddle with as you can see.
I see you got a lot of extraneous labels in your pauses, and lots of little labels. Things to work on. The criteria it applies go by where the median or other percentile of the power spectrum falls, and so it’s independent of loudness and might label stuff in pauses. You can eliminate little labels by raising the first parameter.
I hardly mean to do general “speech recognition” but reliably distinguishing m, n, ng from vowels (even if not from each other), and also picking out the sibilants, could be a useful preliminary to developing useful speech-cleanup effects. I find there are different things that I often do to those different kinds of sounds for polished results, and I would love it if I could automate some of this.
Could this be the base code for a killer De-Esser? Right now, Audacity has to go to outside products for De-Essing. There is no internal or home product.
“Essing” is what happens when you have normal speech recorded with a rising frequency characteristic. Sooner or later, the performer is going to produce an S sound that overloads or sails outside of the characteristics of the radio channel carrying it. People frequently want to rescue these performances into a more theatrically pleasing form.
Each “Sister Suzy” sound carries the characteristics of fried eggs and simply drooping the high frequencies will not correct it. But I bet this could make a serious dent in the problem.
Play with it, kozikowski, and see first if my simplistic sorts of criteria can be good enough to demarcate sibilants.
My toy is still very green but as described I think I can isolate m, n, ng pretty well, at least for my own adult male voice: the right frequency to use may depend on the speaker of course. My preliminary tests suggested 90% below 1500 Hz was good for separating voiced from voiceless sounds, then 90% below 750 was good for separating the voiced stops from the vowels.
I don’t profess to know much about the science of speech acoustics. This was just some tinkering.
If you look at spectrograms often, you learn what different speech sounds look like (the broad classes of sibilants, vowels, voiced stops, voiceless stops), and that’s a basis for guessing some numbers to feed this little machine.
I could make it more complicated with combinations of criteria, but let that wait.
Certainly I should program some zero-crossing refinement of the endpoints. To do.
Hm, I have a little test sample of my own voice in a certain register, containing only vowels and voiced stops, for which the indicated numbers worked to isolate voiced stops. A proof of concept.
But the correct frequency wouldn’t be fixed… I picked out some other less contrived recorded text and found the word “beginning.” Again I could find a 90% level for which the tool nicely bracketed the b, g, nn, ng, but is was more like 400 Hz, and 750 bracketed too much. But that level also seems to pick out p, w, and some pauses.
I didn’t think it would be easy. I think “there exists” a 90% level that works well for a given voice (and as a fiction narrator, I have many voices…) but that varies. Now deducing that level from a voice sample would be another thing. But it seems if I know the level, the rest follows.
Still I might hope that voiceless sibilants might be different and more speaker independent?
Needs work! What did you expect for just a few days?
It’s great as a proof of concept - excellent progress.
Perhaps the algorithm can be made to discriminate better by giving it some “context” rather than only a % level. For example, the samples that I posted show lots of false positives, a lot of which could probably be eliminated by looking at the frequency content immediately before and after - in speech detection, it would not be expected to find “bbbbbbbbb”, so if a long period of a detected “b” sound is found, then the detection level is probably set too sensitive and the threshold needs to rise (preferably automatically).
What did you say? I’m not that good at reading waveforms!
As I said, the right threshold for separating the voiced stops should indeed be context dependent but I hope sibilants might be easier.
Here’s a few results I’ve seen with a few little examples with lengthened sibilant sounds, perhaps these may be robust:
75% above 4000 picks out f, th, s, sh sounds.
75% above 6000 picks out f, th, s.
75% above 8000 picks out f, th.
I yet don’t know how to distinguish f from th, or how to separate the velar fricative (German “ch”) from vowels. I haven’t played with voiced sibilants.
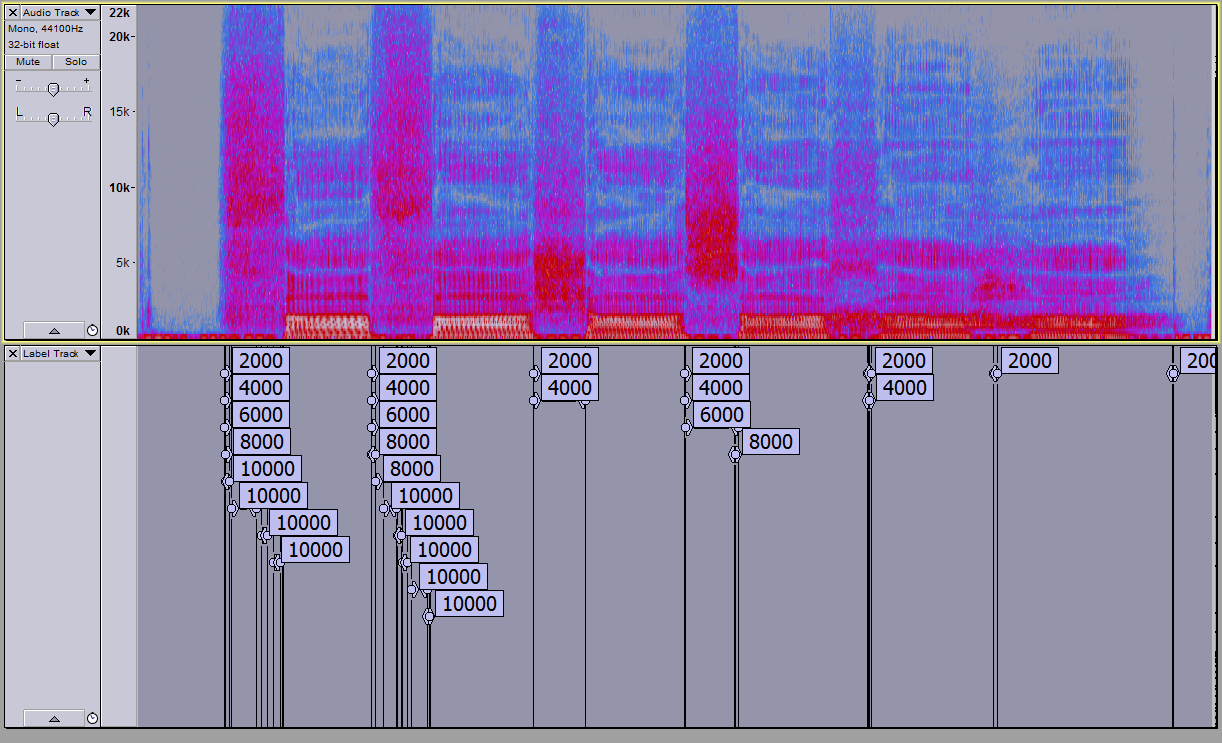
Here’s a more elaborate version of the tool, that lets you fix the “percentile” parameter and see varying results for different frequencies. And here is me babbling “Tha-fa-sha-sa-kha-ha” in spectrogram, and the results of this version of the tool, default settings. It does a pretty good job of slicing some of the sibilants from the neighboring vowels in a way that corresponds to the evident changes in the spectrogram. You can read right off this chart how different 75th percentile frequency thresholds easily distinguish sh from s, f, th, and s from f, th, at least for this little contrived example of me enunciating sounds slowly.
These settings are not so good to delimit “kh” (not an English sound) and “h” but there are short regions of each that are labelled as unlike the vowel “ah”.
Now, suppose I combine this with zero-crossing refinements, and then some envelope changes or low-pass filtering in the selected pieces… could that be a passable “de-esser” all done in Nyquist? PhonemeFinder.ny (7.9 KB)
Honestly, I did not consider this particular experiment very successful after all, and I moved on to other things. I was still learning about Nyquist and playing with toys. And I was doing things that were frustratingly expensive in computation.
I wrote something that automatically detects and filters out the wet clicky sounds that happen when one speaks closely into a microphone, and I have heard from many audio book narrators who are grateful for this. Also something that eliminates harsh whistling sounds that sometimes occur in sibilant consonants.
Both of these tools also have options just to generate labels rather than modifying the sounds in any way.
If you have the time and inclination, perhaps you could study the sources and adapt them toward another use. I’d like to know if it works.