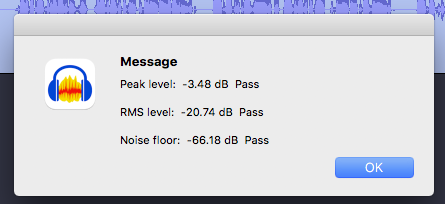
Hi all, this is my first post here.
I’m producing a podcast that is all spoken word with short intro and outro music.
I’m editing my spoken tracks.
I’ve studied http://manual.audacityteam.org/man/index_of_effects_generators_and_analyzers.html and have read many blog posts and watched many videos on editing, but I’m struggling to understand the necessary Effects for spoken word podcast editing.
I don’t want to overproduce this, and many of the effects appear to damage more than help.
Most guidance out there might tell me what to do based on one person’s opinion, but not the why, when and where to do it (and often the advice is conflicting). Much of the advice doesn’t distinguish if one tool is good for spoken word, or if it’s only wise for music, and most lacks appropriate context to help me understand what’s right for me.
I just want my voice to sound its best for podcast listeners.
Everyone seems to agree Noise Reduction is a no-brainer best practice for spoken word podcasts, so I’m doing that. I"ve got the uhms, ahs and pregnant pauses managed, so that’s handled.
But what about Compression or Equalization?
I’ve read Compression helps listeners crank up the volume in noisier environments without distortion (is that true?). But do I lose anything I don’t want to lose?
I’ve experimented with various equalization settings but all seem to make what otherwise sounds like solid audio either sound muffled and underwater (with bass boost) or tinny without base boost. Do you recommend equalization for spoken word?
What about Amplify? Is that a best practice, or is that redundant with Compress?
I’d be curious to learn which effects the experts here consider a best practice to clean up or improve what’s already an otherwise solid recording, and in what order do you apply them in your workflow?
Thanks, all.