Starting a new topic about possible noise removal improvements (not bug fixes). Maybe this should instead go in the “new features” thread?
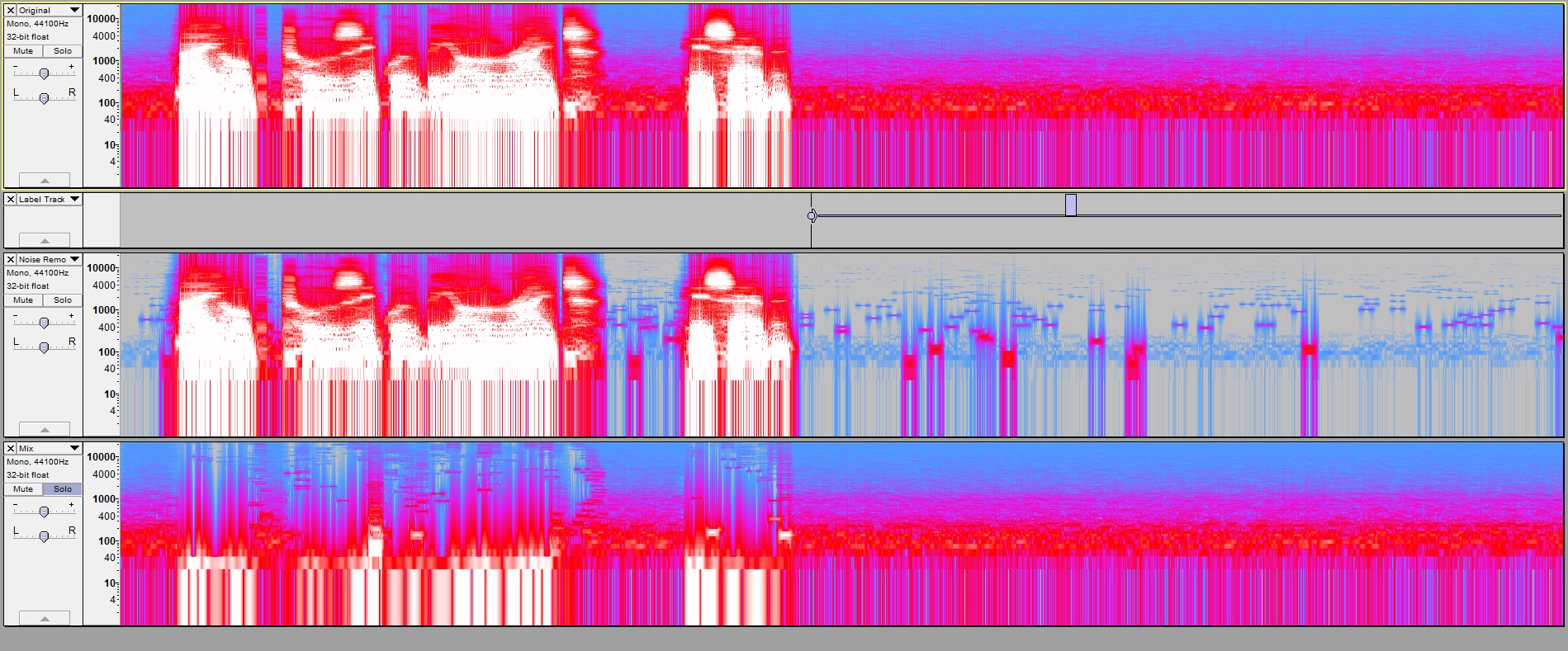
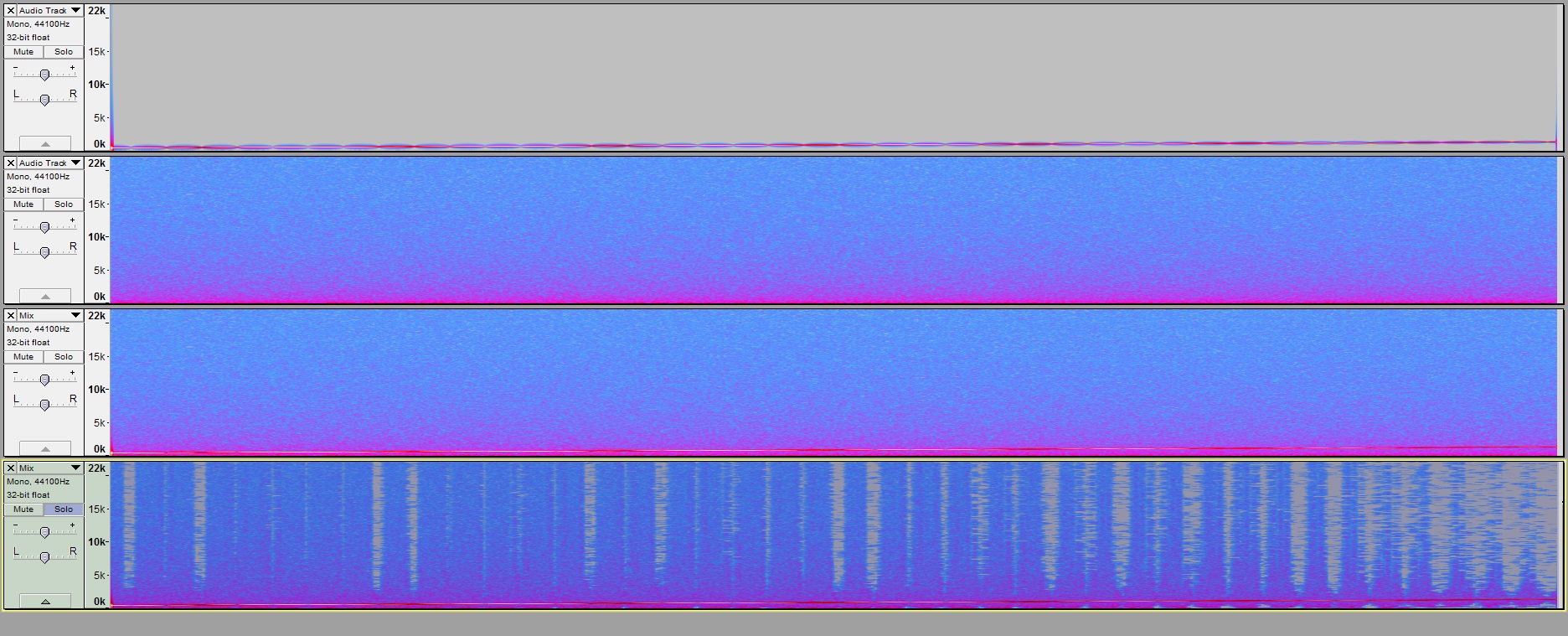
Here are tinkle-bells made visible! Please pardon the big images.
Depicted here: Views are all Spectrogram log f to emphasize lower frequencies. Spectrogram settings are Rectangular and 2048 (because that is what noise removal “sees” too). Also Gain was set to 60, range 80 so that -60 and above is white, -80 is red, -100 is magenta, -120 is pale blue, -140 fades to gray.
First track is a bit of speech followed by some room tone. (I did some highpass filtering first.)
Second track is the result of Noise Removal (in 2.0.5) applied to the first track. The labelled portion was used as profile. The noise removal settings were (besides Sensitivity) extreme, at 48, 0.00, 0, 0.00.
Third track is the result of mixing the second and the inversion of the first for the difference of waveforms (what Isolate is supposed to do?).
Some soft “tinkebells” are seen in the pauses in the second. The are apparently at about -80 at most.
The third view makes evident the distortions in the words that are audible in the second track. These are the serious tinklebells! Many are above 1000 Hz where perceived loudness is much greater than for equal amplitudes at lower frequencies.
How did those tinkles above 1000 Hz get there when my noise sample is below -100 dB for that frequency range and the words are much louder there? I think I know the answer and a possible remedy in code, but there are tradeoffs.
if (mSpectrums[i][j] < min)
min = mSpectrums[i][j];
to this:
if (mSpectrums[i][j] > min)
min = mSpectrums[i][j];
A one-character change! (Though min should then be called max.) I am doing the opposite of what Dominic put there in version 5979.
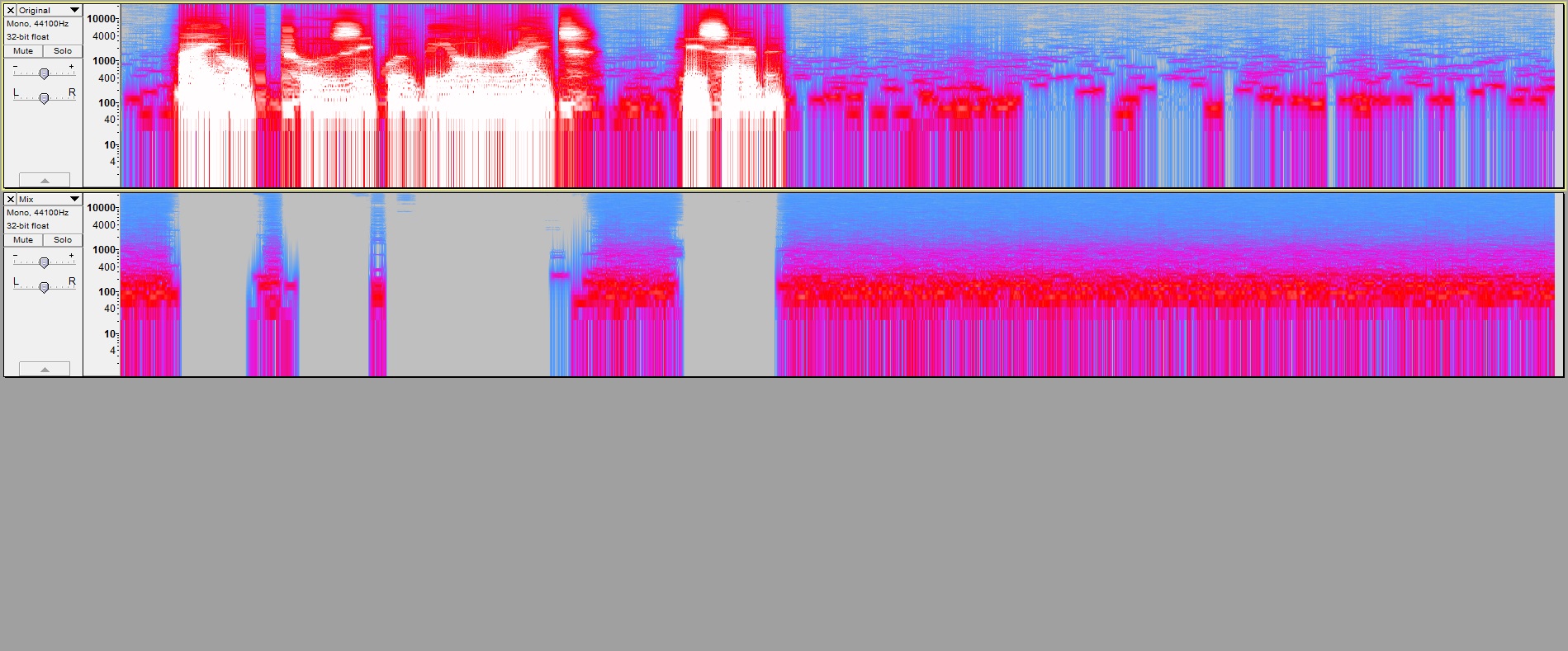
Repeat the experiment, and now look at the second and third tracks. The pauses are worse, but I think the words are improved more than the pauses are worsened, AND, this is the right change in algorithm that would let you increase the Sensitivity setting without bringing the tinkles back into the words. I don’t yet have a demonstration of Sensitivity, but I was keeping all other settings equal to show the effect of this one change.
These pictures also reflect another bug fix in my build, which affects only the lowest frequency bin of the results. The next lowest bin is centered at 21.533 Hz (though the display aligns that with the bottom of the stripe instead of the middle).
My interests are with narration as you know. What does this do to your favorite musical examples?
UPDATE: loaded another version of the picture. There seems to be a bug that mislabels the vertical scale of Spectrogram Log F, unless you zoom out to the maximum.
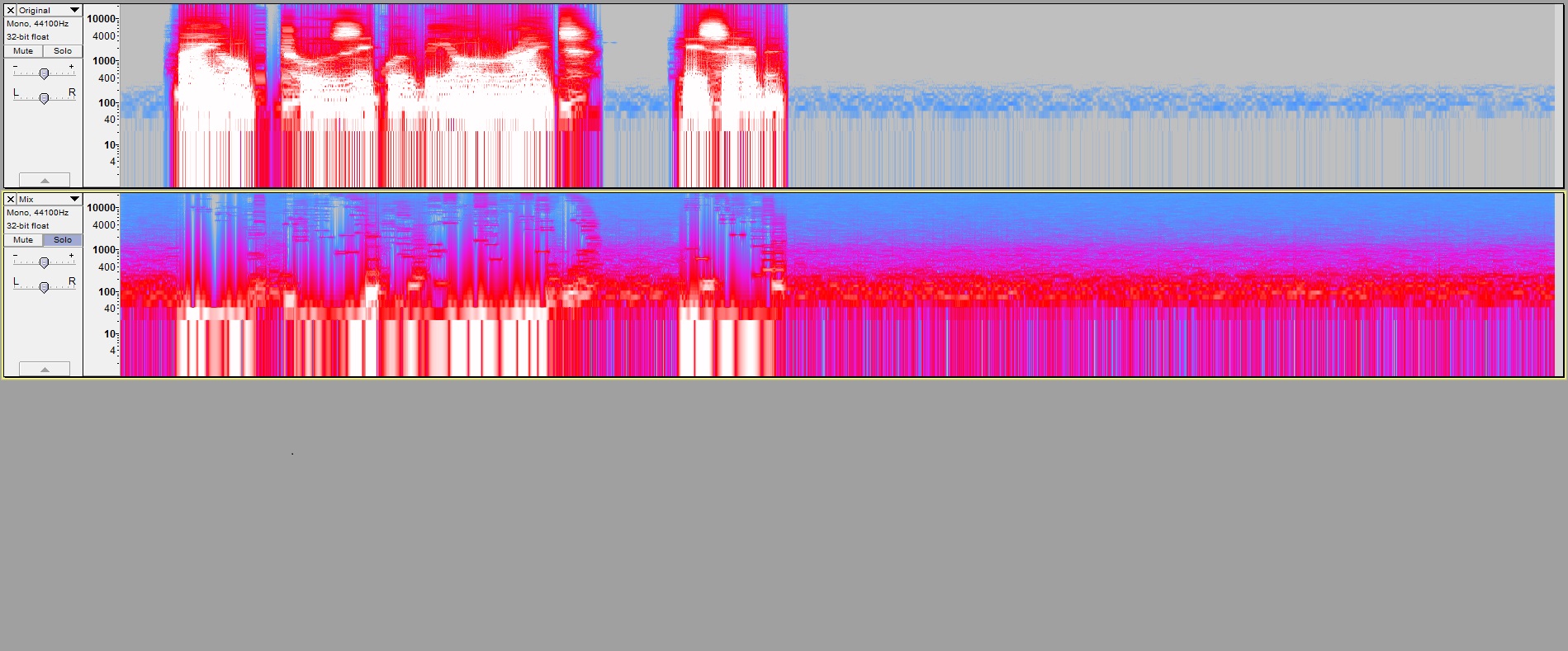
Tried it again with the bug fix, increasing sensitivity 1 dB at a time until I saw no tinkles in the pause. That happened at 6 dB. Then repeat the procedure and look at the differences.
float min = mSpectrums[start][j];
for (i = start+1; i < finish; i++) {
if (mSpectrums[i][j] < min)
min = mSpectrums[i][j];
}
to:
float min = mSpectrums[center][j];
The main problem being that with either, in my initial test, the remaining noise becomes a lot more tinkly.
For music, the effectiveness on “silence” is often more important than on higher amplitude sound because, as long as the noise is reasonably low level to start with, it is largely masked by the (much louder) sound of the music.
As you anticipated, this is substantially mitigated by increasing the “Sensitivity” control, so that would need to be recalibrated.
By contrast, unmodified 2.0.5 only required 4 dB sensitivity to make all the tinkles in the final pause go away (and really there was just one left at 3). But then, look at the distorting effect in the words.
Making “min” (rename it!) the maximum of the power over at least two successive windows is exactly what I need to fix the problem of foreground noise distortion as I understand the cause of it. I predict you will still have that problem with this change.
I just had another thought. The need to increase sensitivity would be lessened if the noise profile were examined more thoroughly.
I said noise removal “sees” the spectrogram with rectangular windows of 2048, but it steps by half a window so it really sees only every 1024th column of colors. That may be adequate for good noise removal but when examining the profile, we can afford to take smaller steps. Profile is supposed to find for each bin the 50 ms period in which the least amplitude is greater than in other periods and make that the theshold. Testing more than two amplitudes in each 50 ms would raise the threhold. A higher threshold means more gets recognized as noise. Tinkles in the background happen when too little is recognized as noise. (Distortions happen in foreground when to much is recognized.)
I think you just answered a different question from what I asked.
When doing noise removal, not accumulating the profile, I believe it is hazardous to take just one window and compare it to the profile. Look closely at the spectrogram of sound with rectangular window of 2048. Many bands appear to fluctuate rapidly in magnitude from sample to sample, even within a note or a vowel. Now remember that the algorithm only sees every 1024th value in any one of those bands. If you get an unlucky choice, one of these might dip below the noise threshold for that band, causing the naive algorithm to drop out that band for a whole window of 2048.
But take just one other window, and take maximum, and you reduce the probability of these artifacts. The algorithm becomes “insensitive” where it should be. But then it also becomes insensitive where it shouldn’t, in the pauses, and so we need other compensations like sensitivity.
Now it needn’t be maximum of two, it might be average of two, or midmost of three… those others might work to prevent artifacts in foreground sound, but something must be done that considers one or more neighboring windows, not just considering the center window alone.
Minimum of two – what existed before – makes the algorithm TOO “sensitive” and perhaps spreads the artifact over TWO windows of foreground sound (overlapping for 3/2 times 2048 samples).
If the comments in the Wiki about the noise removal algorithm were by Dominic – and part of it replicates his comments from code – then it seems he was anxious about the tinkles in the quiet parts, which is well, but his solution introduced these other artifacts in the foreground.
Version 5979 by Dominic in 2007 made major changes introducing the algorithm we now have. Something rather different existed before which did appear to do averaging within each band in GetProfile. Some other algorithm with the comment
/* try to eliminate tinkle bells */
was doing frequency smoothing too by some other means in RemoveNoise.
There was no attack/decay, but a sort of time smoothing that was an exponential decay only forward in time. There was no queue of buffers. One window, only, was compared with the profile values.
There was no attenuation factor – instead gain of 1 was assigned to non-noise, 0 to noise, for true removal, not reduction (though with smoothings). There was one slider controlling “level” which was more like a “sensitivity” affecting the criterion for deciding that a bin of a window is noise or not-noise.
The big change in 5979 introduced attack/decay time, the reduction factor, and the frequency smoothing, but eliminated level.
So it remained until version 10512 in 2010 by Marco Diego Aurelio reintroduced sensitivity.
It looks like the smoothings and the sensitivity all exist to combat the tinkles, but nothing completely satisfactory has been found. I don’t thnk Dominic or Marco could be pressed for comment now?
The treatment of the profile has gone from averaging over the whole profile (of the LOGARITHM of power, just ignoring the zeroes – huh? That’s not RMS?) to the present thing that takes minima in each of many 50 ms windows, then takes maximum of the minima (got that?).
My first trial using the max-of-min algorithm with a finer step size did NOT produce desirable results, for a reason that I should have anticipated. Just as unlucky values make the minimum too small when doing the removal, they can also do that when determining the noise thresholds, and the finer step made that more likely to happen, so my thresholds were too low for many bands and I ended up removing too little noise.
A simple (arithmetic) mean power computation over the whole profile seems NEVER to have been the algorithm, simple as it sounds! Instead the most ancient versions used this unexplained GEOMETRIC mean of power… with the infinities from log of 0 just thrown out of the sum!
The algorithm change in Audacity 1.3.3 (r5979) was, for most material, a considerable improvement over the older algorithm. In particular, it was/is much better for music that has very low level noise as there is insignificant effect on the music while giving a good amount of reduction to the noise during “silences”. However, for some types of material, the old algorithm was demonstrably better. This was particularly noticeable with bass notes over a high level of hiss: with the new algorithm, the hiss could be heard through the notes. The Sensitivity slider was introduced specifically to reintroduce the benefit of the old algorithm into the new version.
Interesting about the different ways that the profile has been calculated over the years. I suspect that the “best” way depends on the type of noise being removed. I’d guess that if the noise is very constant (such as generated white noise), it probably does not matter very much which method is used, other than how much “Removal” and how much “Sensitivity” to use.
Perhaps the profile (or corrective gain) should take into account the equal loudness contour for an assumed listening level?
The level of satisfaction seems to be very dependent on how much the user is expecting of the effect (the main reason why raising expectations with the name Noise “Removal” is a bad idea imo). For reducing gentle hiss from a reasonably good “home studio” recording, I find the current effect very acceptable. For slightly higher levels of noise, or particularly sensitive audio, tweaking the settings for optimal results can be quite fiddly. This seems to be one of the main problems for less experienced users who would welcome a simpler effect (not easy to do without sacrificing quality). For more difficult material (such as more than a little noise), I think the Audacity effect starts to fall behind some of the alternatives.
For the type of material that I generally deal with, tinkly artefacts in foreground sounds are rarely the major problem, so I’ve not done much testing for that. Consequently I don’t feel that I can give an informed opinion at this stage.
There are certainly some bugs that you have identified that are worth fixing, such as the incorrect attack/release times (yes I think it should probably be “release” rather than “decay” as it seems to be much like the “release” of a dynamic processor). If you can make separate patches for each bug I expect that they can be applied quiet soon after the 2.0.6 release.
The most important test - does it sound better?
and I’m not sure that is the major problem.
There is certainly a problem with how low frequencies are handled.
Here’s an example - I don’t know why this happens, but perhaps you can fathom it:
Generate a 10 second “Chirp” from 20 Hz to 200 Hz, 0.8 to 0.1 amplitude.
Generate 10 seconds of silence.
Take the noise profile from the silence and apply it with the default settings.
Ideally, nothing should happen (because we are removing “silence”), but that is not what we see.
Now repeat but this time make the noise profile from 10 seconds of pink noise, amplitude -30 dB (not unreasonable considering some of the audio samples sent in). Why does this happen?
For fun, try mixing your test cases with the inversion of the original chirp. With the pink noise example, there are some curious “chattery” artifacts. For both, there is a slow pulsing. Now look at the original chirp in spectrogram with 2048 rectangular windows, notice what happens in the lowest band, and notice how that relates to the difference waveform as you view it in Waveform dB.
I guessed even before trying these out for myself that you are seeing the effects of that bug that blanks out the DC component before inverse fft.
Try the pink noise with 48 and no attack and no smoothing. Subtract the original and listen to all the weird whispering. You see, I thought something like this is what the messed up Isolate feature ought to be doing, and hearing so much junk in the foreground noise convinced me that something had to be done about it.
I tried all this in 2.0.5 and then in my build. The first example, with silence for profile, does nothing to the sound as expected. The difference of tracks is not exactly 0 but had peak amplitude of -127.6 dB.
For the pink noise example, the differences between the tracks are mostly inaudible, with a little squeak near the end. I don’t know yet how much of that is due to the DC offset fix, and how much else to that replacing of min with max.
Shouldn’t we make it less so then? I think time smoothing, frequency smoothing, and sensitivity exist to you can compensate for threshold setting by profiling that isn’t good enough. For my proposed change to fix foreground sounds, there is then too little sensitivity to background sounds. I would rather seek the smarter profiling algorithm so results are often good with no smoothings or sensitivity.
I was using extreme settings on some voice: 48 dB reduction and no smoothing. I was calculating the difference from the original. I was in short trying to do what Isolate is supposed to do on one interpretation – just pass the pure “noise” part as the program detects noise. Sensitivity affects “what is noise” but smoothings do not. I think that test should do what is expected, and I made a great improvement that takes the foreground parts and makes SILENCE of them. If we fix Isolate to do something like this, silence for the foreground is what I want to hear, or else I won’t trust the effect. At least that was my own experience with Noise Removal in the beginning: I came to mistrust it because Isolate was lying to me. Then I learned to ignore Isolate, then to subtract sound from sound for myself, and still I was not satisfied.
What is the procedure for making and using .patch files? I don’t know it. If I make a sequence of changes to one file that may each get accepted or not, should I make each change based on head and have merge problems, or make my patches cumulative according to some prioritization of these fixes?
As I said, extreme settings to do what Isolate ought to do, not what I would use to treat speech for real with only slight reduction, but yes. There are noticeable distortions in the words with 48 dB reduction, and I know that lesser attenuation or smoothing merely mitigate that, but I am happier knowing I can eliminate them instead.
I have had another idea, that for each band, we find some high quantile of the power for each bin… Of course max is very easy to find but might be too sensitive and would be corrupted by just one click somewhere. So not the 100th percentile. Outlying lows make the present max-of-min procedure work badly when the noise is examined more closely with less step between windows.
Well, didn’t I tell you that in the earlier thread? The DC components always got zeroed and that explains the oscillating envelope for the pink noise profile and the nonzero effects for the silence.
What do you think should happen with pink noise? I think the chirp should be likewise unaffected by removal of pink noise. But instead there are whispery artifacts, which are obvious in 2.0.5 and less so with the change from max to min. I think they could be made zero or close to it by ANOTHER variation in procedure we haven’t discussed yet.
The noise sample, and the profile, are transformed by FFT with rectangular window. A Hann window is used only to blend the overlapping windows together after inverse FFT.
The alternative would use a Hann or other window BEFORE FFT.
This was what Dominic did, until version 2200. The comment for the revision is
Applied Craig DeForest’s fix for the Noise Removal (window after
FFT) and fixed 47.5-second problem (improper overlapping between
blocks)
I have no other explanation why the approach was changed. After this change, Hann windows were NOT applied to the profile. But the noise was forward - fft’d TWICE – the frequency data, to be back-transformed, without the Hann window. But another forward fft, yielding the spectrum used for noise discrimination, WITH the window.
This remained the state of the program until the major revision, and this was the algorithm that you say some thought better for some uses. You said it handled something like a hiss under a cello sound better. I think I can guess why now.
This post is getting too long, I want to think and experiment some more.
I tried all this in 2.0.5 and then in my build. The first example, with silence for profile, does nothing to the sound as expected. The difference of tracks is not exactly 0 but had peak amplitude of -127.6 dB.
In other words I get my original samples back with errors only in the sixth decimal place. Maybe that is just the roundoff error of the FFT inversion and nothing more.
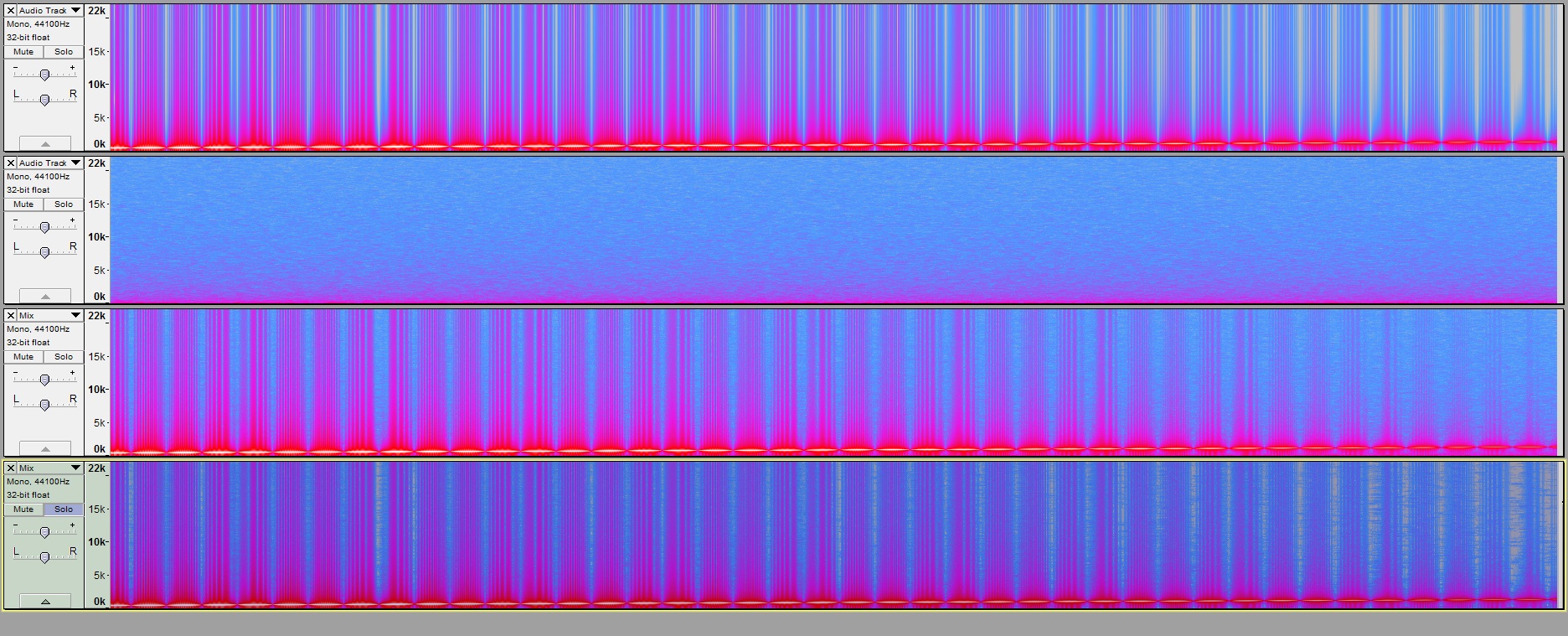
First picture: your chirp, pink noise, the mix of those two, and the result of noise removal (in my build with fixes) with the pink noise as profile, and extreme 48/0/0/0 settings, viewed with 2048 Blackman-Harris windows (and default gain and range settings for the palette). Which are good windows for very low side lobes but a wide central lobe, so frequency bins are not contaminated at “long distance.” Looks like noise removal didn’t work very well!
Second picture: all of the same, but using Rectangular windows.
Do you see how the second picture explains the bad noise removal seen in the first picture?
This is something like the hiss under the cello maybe.