You have added a line of code that creates a “sound” that is “GAP” seconds of silence, but have done nothing with it. It is not added to the sound “S”, in fact it is not used at all by the code.
Also, Nyquist can only return one result, and your plug-in is currently returning a label track. A Nyquist plug-in cannot return both a label track and a sound at the same time - one or the other.
I don’t actually need the label track so I’ve commented out the (defun add-label…) and the two lines that called it.
The Silence Generator by Steve Daulton is really only two lines of code, and I did add both lines initially… I don’t know exactly how the code works but it does insode his plug-in and like I say, as far as I can tell it’s only two lines.
I think the main code creating the “gap” is this :
(stretch-abs gap (force-srate sound-srate (s-rest 1)))
I placed that line in the place (loop) where each label would’ve been added - but now, instead of a label, I want to add say 3 seconds silence at each “silent” point.
Now that I’ve removed the label making stuff - maybe gap making stuff will work?
I’ll try it and report back…
Sorry if I sound really ignorant - it’s because I am
;nyquist plug-in
;version 1
;type process
;name "Silence Generator Effect..."
;action "Generating silence..."
;info "Silence generator effect by Steve DaultonnnReplaces selection with set length of silencenTo 'Insert' silence, place the cursor at the requiredninsert position then hold the SHIFT key down andntap the cursor left or right key to create a tiny selection.nnThis effect can be used with 'Ctrl+R' provided thatnat least a tiny part of a track is selected."
;control gap "Inserted silence length" real "seconds" 5 0 10
(stretch-abs gap (force-srate *sound-srate* (s-rest 1)))
Probably best to first look at what this is doing, and how.
The first part is the plug-in “header” that tells Audacity that this file is a Nyquist plug-in, that it is a “process” type plug-in called “Silence Generator Effect…” and gives some text to be displayed at the top of the plug-in interface. The Nyquist plug-in header is described here: Missing features - Audacity Support
An important thing in the header is “;type process”.
There are currently three types of Nyquist plug-in; analyze, process and generate.
Usually a plug-in that generates audio (including silence) would be a “generate” type plug-in. This plug-in is a bit unusual in that it generates audio (silence) but it is defined as a “process” type effect. The reason for this is because of the original purpose for the plug-in: https://forum.audacityteam.org/t/repeated-command/14416/1
Some key differences between the different types of plug-in:
process:
Appear in the Effect menu.
Usually for processing (modifying) audio from a track.
Usually returns a “sound”. Can be used in Chains (Audacity Manual). Can be repeated using the keyboard short-cut Ctrl+R. (Audacity Manual)
Can access the selected audio.
Uses local time.
Requires that there is a Selection.
analyze:
Appear in the Analyze menu.
Usually for analyzing the audio in a track.
Usually returns a text message or labels.
Not supported by Chains.
Can access the selected audio.
Uses local time.
Requires a Selection.
generate:
Appear in the Generate menu.
Usually for generating audio.
Usually returns a “sound”.
Not supported by Chains.
Cannot access the selected audio.
Uses “global” time.
Does not require a Selection (will generate a new audio track if no track is selected).
The final point requires some explanation.
“Local” time for a Nyquist plug-in uses the duration of the selection as “one unit” of time.
“Global” time is “real” time - “one unit” of time is one second.
Thus, in a process or analyze type plug-in, the command (S-REST 1) will produce “one unit” of silence, which is the same duration as the selection, whereas in a generate type plug-in, the same command will generate one second of silence.
If the plug-in was written as a generate type plug-in (which would be normal because it generates silence) then the code would have been more simple:
;control gap "Inserted silence length" real "seconds" 5 0 10
(s-rest gap)
The first line tells Audacity to create a slider control.
The slider control sets the value of “gap” (which is a variable)
The command (S-REST GAP) generates silence of duration “GAP” - so if “GAP = 5”, then it will generate 5 seconds of silence.
In a process type plug-in, (S-REST GAP) would probably not produce the expected amount of silence - if “GAP = 5” then (S-REST GAP) will produce silence that is 5 times longer than the Selection. You can demonstrate this by entering the command (S-REST 5) in the Nyquist Prompt effect.
There are several ways that we can force a process type plug-in to generate a specified number of seconds (rather than a length that is proportional to the length of the selection). The shortest way is to use “ABS_ENV”. Thus in the Nyquist Prompt effect we can generate 5 seconds of silence with:
(abs-env
(s-rest 5))
The other way (as used in the plug-in) is to stretch “one unit” of sound to the desired duration using STRETCH-ABS.
The other command FORCE_SRATE) specifies that the silence should be generated with a sample rate that is the same as the track sample rate, which is given to Nyquist by Audacity in the variable sound-srate. Audacity plug-ins have got a bit smarter over the years and this part is not required if using Audacity 2.x
So, for your proposed plug-in, you should change the header to specify the plug-in as a “generate” type plug-in rather than an “analyze” type plug-in, then you don’t need to use STRETCH-ABS or FORCE-SRATE.
That should now show up in the Generate menu.
However, thinking about this, for your plug-in, you are not “purely” generating sound. You also need to access and return the original track sound, with periods of silence added in particular places, so really your plug-in needs to be a “process” type plug-in. If this plug-in is defined as a “generate” type, then the original track audio cannot be accessed and will be overwritten, which is not what you want, so it’s back to: ;type process
This does make setting durations a little tricky, but there are a few techniques that can resolve this:
The above will evaluate the “code.goes.here” in the “default environment”, which means that “real” (global) time is used.
Also the function GET-DURATION will convert from local time to global time, so the following code will tell us how long the Selection is (1 “unit” of time) in “real time” (seconds).
(get-duration 1)
Yes.
What we need to do is to extract each section of the original sound between the silences, and put some more silence between each section.
Let’s see how this would work - we’ll do some experiments using the Nyquist Prompt, but remember that the Nyquist Prompt is an “Effect” (“process” type) so times are relative to the selection length and not “real” time (not “global time” in seconds).
;extract a short section of the audio selection
(extract 0.5 0.8 s)
;extract two short sections
(let ((s1 (snd-copy s)))
(seq
(extract 0 0.2 s1)
(extract 0.8 1.0 s1)))
;split in half and add some space between sections
(let ((s1 (snd-copy s)))
(sim
(extract 0 0.5 s1)
(at 1.0 (extract 0.5 1.0 s1))))
;split into three sections and insert space between sections
(let ((s1 (snd-copy s)))
(sim
(extract 0 0.3 s1)
(at 1.0 (extract 0.3 0.8 s1))
(at 2.5 (extract 0.8 1.0 s1))))
Now a slightly more complex example that uses “real time”:
;split into three sections at 3 second intervals
; and insert one second space between sections
; The selection should be a mono track that is
; at least 9 seconds long.
(abs-env
(let* ((gap 1.0) ; required 1 second gap
(s-dur 3.0) ; duration of each section
(section1 (extract 0 (* 1 s-dur) s))
(section2 (extract (* 1 s-dur) (* 2 s-dur) s))
(section3 (extract (* 2 s-dur) (get-duration 1) s)))
(sim
section1 ; default time is zero
(at (+ s-dur gap)
(cue section2))
(at (* 2 (+ s-dur gap))
(cue section2)))))
How are we doing so far? Does this make sense?
There can be some tricky traps when dealing with time events, but try some examples of your own and feel free to ask if there’s bits that you don’t understand.
Would there be any “demand” or value for “Truncate Silence” to be able to “expand” (repeat) silence as an extra feature? What is the use case - to give someone learning a language sufficient space to record their pronunciation underneath?
Would repeating be better than generating absolute silence in this proposed effect (or should it be an option)? This might sound more natural if the background was a little noisy.
I think it is quite “doable”, but for me it is a question of priority.
If I have time I’ll “hack something up” for you, but as Gale asked, is there a demand for such a feature to be properly developed?
I presume that you are aware that you can pause and resume playback by pressing the P key (which could be configured to a different key if you prefer)? Is it much better to insert silences rather than just pausing playback?
Some time ago, I’ve written some code that could be interesting for you.
I’ve tested it with your example and it works quite well.
However, it expands the pauses by a percentage and not a fixed amount.
Additionally, all pauses can be removed with a Parameter of -100.
The second control sets the pauses that are to small to be regarded, i.e. all pauses less than x s are skipped.
For example: a value of 0.01 s and 8000 % seperates the syllables themselves.
But the greater pauses are of course also stretched proportionally - that’s why a negative Expansion is worthwhile to apply Prior to this.
It would be great if the phrases could be repeated as proposed by Gayle - but this Needs some more elaborated algorithm since the phrases must match the gaps.
I can post a beta Version (currently mono) during this Weekend, if you want.
I’m still interested to know if you think there is likely to be demand for such a feature (other than your one user case), but here’s a plug-in that you can try: StretchPause.ny (3 KB)
I see, no Need for my Version.
Little side-remark:
The plug-in does actually not “Stretch” the pauses. This implies in my mind a Stretch factor i.e. a Ratio similar to the truncate silence plug-in (of which the Name is also unluckily Chosen).
For exammple: you have the pauses 2.3 and 4.2 s respectively,
an Expansion by 2 (s) gives 4.3/6.2 s, whereas stretching by 2 (factor) gives 4.6/8.4 s.
The latter behaviour could be implemented in the truncate silence plug-in if fractional ratios were allowed.
Thus a Ratio of 1:0.5 would Stretch the pauses to their doubled length.
That’s perhaps a considerable Feature for the future, along with a Name Change (something like silence compression/Expansion).
True, but it’s easy enough to change the name.
Any ideas for a better name (more accurate and still short)?
@ JH2013
If you want to change the name of the plug-in, just change line 5. For example if you want to call it “Eric”
;nyquist plug-in
;version 3
;type process
;categories "http://lv2plug.in/ns/lv2core/#DelayPlugin"
;name "Eric..."
;action "Finding silence then inserting more..."
;info "by Steve Daulton (www.easyspacepro.com).nReleased under GPL v2.n"
The three dots (ellipsis) after the name are not essential, but the convention is to use them for effects that have an interface before the effect is applied.
The idea is not to have to press play, pause, play, pause, etc… the file should have the spaces so that you could for instance be playing it in a car as you drive along without being distracted - simply play it on loop and practice.
There is no need to repeat (duplicate) the actual spoken phrases within the file - just allow enough space for the listener to repeat the last phrase and then continue to the next phrase, and so on. The repetition comes with playing the file over and over. The person who uses this proposed plugin would decide how long the practice segments should be, as needed.
The actual silence should be real silence - no background noise or effect is needed because for instance in a car, or home, there is already enough noise - or at home, soft music could be playing somewhere in the house anyway. So, the file should be clean in that sense. I’m saying this because the spoken files I’m using are well recorded and very clean. But I take your point, if it was a dirty recording, then pure silence might sound weird… in that case, the quality of the recording (in my opinion) is probably not worth using anyway. I can’t stand listening to badly recorded stuff - vocal or otherwise
I experimented with the length of silence and found 3 seconds to be a fair compromise if the length of silence must be a fixed length - but another way of doing it is to make the silence a variable length based on the length of the vocal phrase, multiplied by a comfort factor (CF) that could be set by slider control, say between x1 to x5. So, for instance, if the phrase was 3 seconds long, and the CF (for the whole file) was set to x2 - then the inserted silence would be 6 seconds i.e. 3 seconds x2. If the CF was set to x1.5 then it would of course create a 4.5 second gap.
Language translation and languages in general is a huge thing these days… Google and Microsoft are both into it big time. I find it hard to believe that this software (or plugin) doesn’t yet exist. I would be using it non-stop. All I can tell you is that the numbers of people who would use this (if they knew it was available) is vast and covers the whole world.
Steve,
I don’t think you have to Change the Name.
As I said, it is only a Little side note and I don’t want to appear finicky (although I am sometimes ).
Mathematics and sciences are very exacting when it Comes to Definitions, language in General is quite vague but we mostly know what is meant.
Otherwise, you wouldn’t understand my postings at all, since I am no native Speaker.
Mathematically expressed, the Expansion of the pauses would be defined as:
y = mx + b
x is the original length, b is the constant that is added by your plug-in and m is the factor that my Approach works with. We call m the slope and b the y-intercept.
regrettably, this brings us not a hair’s breadth nearer to a new Name.
From a Musical point of view, the pauses are Held or sustained for a fixed amount of time, but I guess that “Pause Hold” doesn’t describe the effect in any way better.
I would normally prefer a Name that uses a word of the “expand”-Family because it makes sense to say “I am expanding the pauses by 2 seconds”.
But this clashes with the common use of the word for Musical devices such as Compressor/Expander (which should be a De-Compressor).
Those Statements are of course not meant really serious, it is just an philosophical observation on a pointless subject.
English is in fact a very consise language whose words are readily adapted for other languages for this property.
It would be ridiculous to go the other way and use german words for mobile or Laptop:
“What are you doing? right now?”
“I’m going to Play a Little bit with my Beweglich or my Auf-dem-schoss”.
Thus the real Problem is to translate plug-in names into other languages and in most cases the english names do pretty well.
It is only important that the plug-in works properly and that the functionality is described somewhere - if it isn’t obvious already.
So, don’t worry about the Point I’ve raised and thanks for the plug-in.
Thinking of this use case, it seems that that the words or phrases to be spoken by the student could be anything from a second or two to five seconds or even more. So expanding silence by a factor based on the length of audio between the silences would be more useful. Call that method “A”.
For another use case - perhaps someone inserting a commentary between audio clips - insertion of a fixed amount of silence as now may be preferable - method “B”.
If something similar was included in Truncate Silence, I assume the expansion factor would operate on the silence in the way that Robert described, longer silences expanding proportionally to the length of the silence - method “C”. I cannot think of a use case for that at the moment, except possibly in context of a special effect or composing a sequence of some sort.
If we leave this effect at method “B” or allow more than one method, perhaps “PauseEnlarge” might be preferable. “Stretch” and “Expand” seem quite similar to me and both imply enlarging by a factor.
If we leave this effect at method “B” only, then should it be considered for integration into Silence Finder if an when we finally decide the best way of revamping Silence Finder and Sound Finder?
Strangely no-one I am aware of has mentioned John’s idea before as an audio effect. Things like it have been occasionally suggested as a way of automating a “listen - record - re-record - listen to the next phrase” sequence in Audacity ( http://wiki.audacityteam.org/wiki/Proposal_Languages_Ecosystem#Low_Hanging_Fruit ).
I also find that quite surprising. Slowing down “language tutorials” seems like an obvious application, and as JH2013 wrote, such tutorials are quite common these days.
One option is that this effect could be refined specifically for slowing down language tutorials (as described by JH2013), in which case perhaps the name could indicate this use.
Another approach could be a more general tool for “increasing spaces” in a recording, or an even more general tool for “changing the spacing” (longer or shorter).
The thing that we would need to be a bit careful about is creating a “jack of all trades and master of none”. We could end up with an effect that can “Shrink/Expand” spaces (like Change Tempo), “Reduce/Increase” (by truncation/insertion), with choices for % of original silence, % of original (non-silent) sound, seconds, and Expand/Increase options of “absolute silence” or “ambient sound”, but this would probably be too complicated for most uses.
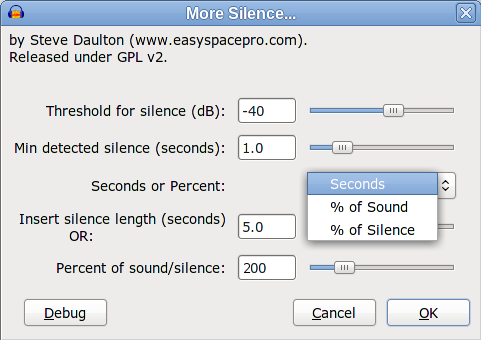
My current inclination is for compromise that is quite flexible, but “specialised” for expanding/extending silence, possibly something like this:
(“Shrinking” the silence could possibly be allowed by text entry)
I think that method C has also some Advantages in certain circumstances.
Imagine you learn a language with a tape or so and the pauses between phrases are already adapted to the previous Audio.
But you have always too rush too squeeze your Version inbetween.
It may help to add 1 s to each pause but this may not be enough for longer sentences. And when you add 4 s, you will most likely learn the short words better - Bonjour bonjour bonjour bonjour …
Another example is a Podcast where your guest litteraly speaks without dot and comma and you want the Overall Timing style match with the Hosts one. Stretching sounds the most naturally in cases where the original Timing is too rushed (Audio books for example). The other methods won’t work for this case.
If this method was integrated into the truncate silence effect, we could still use the Minimum and Maximum controls to positively influence the lengths.
I fancy that an implementation within the silence finder will not work due to the fact that only Labels or Sound can be returned.
Or have I missed something?