I need modification for this Nyquist Plugin - Silence Marker. Seems like when the labels are exported using the “Export Labels”, the content of the label.txt file only contains the location of the silence label in the audio file and not the duration of the silence. Can you please change the plug-in so that the labels contain the start and end of the silence and also the duration of the silence ?
Current Sample of Labels.txt file
1.010068 1.010068 S
Expected Sample of Labels.txt:
1.010068 1.020068 0.01 S
If you do that, then the labels created by the plug-in will be in the wrong format and will not be accepted by Audacity as valid labels. Labels have only three parameters - start time, stop time and label text.
If you can explain what you want and why you want it, there may be some other approach that will work.
I want it to detect audio hole in the audio file recorded. I am recording a continous 1kHz tone from a source for 10seconds. If the source is good there should not be any audio hole or silence detected throughout the duration of the 10 seconds.
If the silence is detected, I want to be able to know where it started and how long is the duration of the silence.
Seems like the label exported contains only 2 numbers ( which I believe denotes the start of the silence) and the “S” label
I was hoping the plug-in could be modified to include more information on the labels like the example I sent earlier.
A couple of things to avoid confusion in our readers:
“SilenceMarker.ny” is the file name of the “Silence Finder” effect.
“Silence Finder” is only accurate to within a few milliseconds, not to the nearest sample.
This may require the latest version of Audacity 1.3 to work correctly.
If you want to export a list of start times and stop times for the silence you can do it like this:
The silence finder places markers based on the end of the silence. Set it to place markers at 0.00 seconds before the end of the silence.
Set the other settings as required and run Silence Finder.
Now Reverse the track (Effect > Reverse).
Add a new label track from the Tracks menu.
Drag the new label track so that it is directly under the audio track.
Run Silence Finder again with the same settings.
Check that “Link tracks” is ON (ling button depressed) and select ONLY the audio track and Reverse it. The label track that is directly below the audio track is linked, so it will also reverse.
Your audio is now the right way round again and you have markers at the start points in one label track and end points of any silences in the other label track.
Select all (Ctrl+A) and Export the labels. The two label tracks will be merged in the Exported file.
Hey! I solved it!
I modified the SilenceMarker so, that he marks both:
begin of silence - as end of previous track
end of silence - as begin of next track
Labels are not only “S”, but “Track 01” etc. and “End Of Track 01” etc.
Use: Save the attached file to Audacity Plug-Ins folder. Or save the code as a new plain-text file “SilenceTrackMarker.ny”.copy the code to new You should
You should have only 1 long track loaded form MC or LP
Then you should only run:
Run: Analyze > Track Finder By Silences
Export all to MP3’s: File > Export multiple
manualy delete the “End Of Track*.mp3” files
That’s all!
I attache the file, but here’s also the code:
;nyquist plug-in
;version 1
;type analyze
;name "Track Finder By Silence..."
;action "Finding silence and mark cutting points for each track ..."
;info "JMA (http://tuzka.cz/jma) 2009 Based on: Silence finder written by Alex S. Brown, PMP (http://www.alexsbrown.com)nVersion 1.0 released Apr 3 2005 under the GPL licensen(http://www.opensource.org/licenses/gpl-license.php)n
;control sil-lev "Silence level" real "dB" 26 0 100
;control sil-dur "Minimum silence duration" real "seconds" 1.5 0.1 5.0
;control labelbeforedur "Place label" real "seconds before silence ends" 0.3 0.0 1.0
;Create a function to make the sum the two channels if they are stereo
(defun mono-s (s-in) (if (arrayp s-in) (snd-add (aref s-in 0) (aref s-in 1))
s-in))
;Create a function to reduce the sample rate and prepare the signal for
;analysis. RMS is good to monitor volume the way humans hear it, but is not
;available in Audacity. Used a peak-calculating function instead.
;NOTE: this is the place to add any processing to improve the quality of the
;signal. Noise filters could improve the quality of matches for noisy signals.
;PERFORMANCE vs. ACCURACY
;Reducing the samples per second should improve the performance and decrease
;the accuracy of the labels. Increasing the samples per second will do the
;opposite. The more samples checked, the longer it takes. The more samples
;checked, the more precisely the program can place the silence labels.
;my-srate-ratio determines the number of samples in my-s. Set the number after (snd-srate s)
;higher to increase the number of samples.
(defun my-s (s-in)
(setq my-srate-ratio (truncate (/ (snd-srate (mono-s s-in)) 100)))
(snd-avg (mono-s s-in) my-srate-ratio my-srate-ratio OP-PEAK)
)
;Set the silence threshold level (convert it to a linear form)
(setq thres (db-to-linear (* -1 sil-lev)))
;Store the sample rate of the sound
(setq s1-srate (snd-srate (my-s s)))
;Initialize the variable that will hold the length of the sound.
;Do not calculate it now with snd-length, because it would waste memory.
;We will calculate it later.
(setq s1-length 0)
;Initialize the silence counter and the labels variable
(setq sil-c 0)
(setq l NIL)
;Convert the silence duration in seconds to a length in samples
(setq sil-length (* sil-dur s1-srate))
;Define a function to add new items to the list of labels
(defun add-label (l-time l-text)
(setq l (cons (list l-time l-text) l))
)
;JMA: Initialize the track counter
(setq track-c 0)
;JMA: Get the track number as string with leading zeros
(defun int-to-string (iint iplaces)
(strcat
(if (> iplaces (length (format nil "~A" iint)))
(subseq "00000000" 0 (+ 0 (- iplaces (length (format nil "~A" iint)))))
""
)
(format nil "~A" iint)
)
)
;The main working part of the program, it counts
;the number of sequential samples with volume under
;the threshold. It adds to a list of markers ever time
;there is a longer period of silence than the silence
;duration amount.
;It runs through a loop, adding to the list of markers (l)
;each time it finds silence.
(let (s1) ;Define s1 as a local variable to allow efficient memory use
; Get the sample into s1, then free s to save memory
(setq s1 (my-s s))
(setq s nil)
;Capture the result of this "do" loop, because we need the sountd's legnth
;in samples.
(setq s1-length
;Keep repeating, incrementing the counter and getting another sample
;each time through the loop.
(do ((n 1 (+ n 1)) (v (snd-fetch s1) (setq v (snd-fetch s1))))
;Exit when we run out of samples (v is nil) and return the number of
;samples processed (n)
((not v) n)
;Start the execution part of the do loop
;if found silence, increment the silence counter
(if (< v thres) (setq sil-c (+ sil-c 1)))
;If this sample is NOT silent and the previous samples were silent
;then mark the passage.
(when (and (> v thres) (> sil-c sil-length))
;JMA: mark BEGIN of silent passage as end of previous Track
;JMA: Mark the user-set number of seconds AFTER first silence sample
(add-label (+ (/ (- n sil-c) s1-srate) labelbeforedur) (strcat "End Of Track " (int-to-string track-c 2)) )
;JMA: increment Track number
(setq track-c (+ track-c 1))
;Mark the user-set number of seconds BEFORE this point to avoid clipping the start
;of the material.
(add-label (- (/ n s1-srate) labelbeforedur) (strcat "Track " (int-to-string track-c 2)) )
)
;If this sample is NOT silent, then reset the silence counter
(if (> v thres) (setq sil-c 0) )
)
)
)
;Check for a long period of silence at the end
;of the sample. If so, then mark it.
(if (> sil-c sil-length)
;If found, add a label
;Label time is the time the silence began plus the silence duration target
;amount. We calculate the time the silence began as the end-time minus the
;final value of the silence counter
(add-label (+ (/ (- s1-length sil-c) s1-srate) sil-dur) (strcat "End Of Track " (int-to-string track-c 2)))
)
;If no silence markers were found, return a message
(if (null l)
(setq l "No silence found, no passages marked")
)
l
Having seen your other posts regarding your modified plug-in, I think it is necessary to point out that for the usual “Export Multiple” method of splitting tracks (as described here: http://wiki.audacityteam.org/index.php?title=Splitting_recordings_into_separate_tracks ) the original silence finder plug-in should be used as your modified version will cause too many files to be exported. The tracks will be exported (as required) but there will be an equal number of short silent tracks also exported.
A small modification to your code could improve the behaviour for using Export Multiple.
Rather than creating separate labels for the start and end of tracks, you could create region labels (not available in Audacity 1.2.x).
To specify a region label you need to create a list of lists (as you do now), but instead of the label being specified as (time text) it needs to be specified as (t0 t1 text) where t0 is the start time and t1 is the end time of the label.
Slightly off-topic: I appreciate triola’s script and have modified it to use stevethefiddle’s region label suggestion. For my own uses, I needed the ability to specify a minimum track length and have added that ability to the script. If you would like, it is available on my website:
I like the idea of “minimum track length”, a useful addition.
A couple of points:
Since you are splitting the track but not removing any silence between tracks, you do not need to use region labels. Simply using “point” labels before the start of the sound will do the same job. This would have the (minor) advantage that it could be made to be compatible with Audacity 1.2.x
The “integer to string” function can be simplified.
Current code:
; Create a track number as a string, with leading zeros
(defun int-to-string (iint iplaces)
(strcat
(if (> iplaces (length (format nil "~A" iint)))
(subseq "00000000" 0 (+ 0 (- iplaces (length (format nil "~A" iint)))))
""
)
(format nil "~A" iint)
)
)
The “(+ 0” is superfluous. Cutting it out (and collapsing the end parentheses) gives:
Adding a “minimum track length” (minimum sound length) option to the “Silence Finder” effect that is included with Audacity would provide the same functionality. You might like to suggest that on the “Adding Features” section of the forum. http://forum.audacityteam.org/viewforum.php?f=20
Thanks! This was my first dabble in a Lisp-based language, and consequently my first attempt at an Audacity plugin. I’m afraid that it shows. You are right that I had modified the original intent of the code on this thread. Now that I understand the syntax, I may even be able to provide a patch for the SilenceMarker.ny script (such lofty dreams ).
I’d be happy to commit a change that added a field to SilenceMarker.ny taking into account “length of the sound”. Would it be better if the default was zero, which means “off”? SilenceMarker.ny is heavily used by novices using Audacity for the first time to digitize tapes and LPs. So the fewer settings for them to have to figure, the better.
I suggest the wording of the field shouldn’t include either “track” or “sound” (the latter would be confusing given we’re detecting “silence”). How about “Minimum label length [seconds]” or maybe better, “Don’t create labels shorter than [seconds]”?
SoundFinder.ny (Sound Finder in the Audacity Beta menu) already uses region labels, so is similar to your plug-in except for having no minimum length option. I suggest we can add the same option to Sound Finder too.
Given that Silence Finder uses “point labels” rather than “region labels” I think any reference to “label length” would also be confusing. How about something like “Minimum label spacing”?
+1
Does anyone use the option: “Add a label at the end of the track [N0=0, Yes=1]” ?
If not, could that control be removed?
After any such changes are decided and implemented it may be worth having a note in the documentation to indicate that if a user wants to simply “split” a track at silences, rather than removing any of the silence, they should use the “Silence Finder” rather than the “Sound Finder”.
I guess the fields really need to be different for Silence Finder and Sound Finder. I somewhat prefer the “Don’t create labels…” wording given the main usership, so for Silence Finder, something like “Don’t create labels further apart than this distance [seconds]” . But if we want to be more formal, then maybe “Minimum distance between labels [seconds]”.
I think that control in Sound Finder could probably be dispensed with. It isn’t helpful to produce a dead file at the end of export multiple. The author had a specific text transcription use case for writing this plug-in though, so maybe an end label is useful. I’ll ask him.
I’ve combined the description of the two effects in the Manual to try and make the differences clearer. Some users tell me they find Sound Finder more intuitive because they find it easier to understand the labels as “mark ins” and “mark outs” and can still leave some silence in with this tool.
Jeremy was exporting sequences of label.txt files and using the end label to tell him where to start from in the timeline when importing the latest label file. I think we can remove that. It’s easy enough to hit END and CTRL + B.
I’ve moved this thread to our new “Nyquist” board.
I’ve added “Minimum distance between labels [seconds]” to “SilenceFinder.ny”
I’ve changed the name to “Silence Finder ML…” to make it easy to test without overwriting the standard Silence Finder.
If anyone would like to test it, download, extract into your Audacity plug-ins folder and restart Audacity. It will be listed in the Analyze menu as “Silence Finder ML…”
I mainly tested this with a 16 seconds DTMF sequence (duty cycle 55%).
If the silence level or duration are sufficiently long that it can’t find any silences, it says “did not return audio” instead of giving the “no silences found” message.
Should it always produce a label before the last silence? For example, if I set a 6 seconds minimum distance, I get labels at about 2.0s, 8.5s and 14.75s, and still get the label at 14.75s if the minimum distance exceeds the track length. I can see that behaviour makes sense from one viewpoint, given audio before the first label is also less than 6s. But a result where we had a label (or not, depending on taste) at zero and then just one at 6.3s makes more sense to me if the aim is produce tracks of a “minimum length”. In that case, we may have to explicitly call “minimum distance” something like “minimum length” after all.
As regards having a label at zero, do we get people using Silence Finder complaining they didn’t get the first track exported because “Include audio before first label” is necessarily off when Export Multiple initialises? I appreciate if we had a label at zero and they “included audio before first label”, there would be a redundant first export.
I took your suggestion of “Minimum distance between labels” which is exactly what it does.
If we had said “minimum track length” or some such, then I agree that the first label should only be allowed if the distance from the start of the track to the first label is equal or greater than the set “minimum track length”.
Looking at the rationale* behind the minimum length feature, I think it is reasonable to allow the first label even if the distance from the start to the first label is less than the “minimum length between labels”
*Suppose that the speaker interacts with someone from the audience for a couple of minutes. Most silence-finding plugins would result in several dozen tracks during this relatively short exchange. In order to rectify the situation, we need the ability to define a minimum track length to go along with all of the other options.Changes in Beliefs | The Wanderer's Journal | Epic Voyage
Given the above scenario, it is likely that the first part of the recording will be duff (while the audience is chatting before the speaker begins) and the user is probably going to want that first label, so I think “Minimum distance between labels” is a good idea. If the user does not want the first label, it is very easy for them to delete it.
I did notice that the original Silence Finder left the cursor in the first label, whereas the modified version left the cursor in the final label. Given the above it is probably better for the cursor to end up in the first label, so I have also changed that back to the original behaviour.
I’ve not seen any complaints about that. Possibly one of the reasons being that often the section before the first label is not wanted. For example, if recording a cassette, there is likely to be a section of silence before the first song. The user is probably not going to want that silence exported. This holds with the idea of allowing the first label even if the distance from the start to the first label is short.
Even if the handling of the first label is not exactly what the user wants in a particular situation, they shouldn’t be surprised as long as it does what it says on the tin.
Which I think is a good reason not to do that. Not having a label at zero gives the user the choice to export the first bit or not. Putting a label at zero removed that choice. SilenceMarker-ML.ny.zip (2.29 KB)
I didn’t initially want to use the term “track length” exactly in case we had a solution like we have now. But now I can see a working example and other possible rationales, I’m really unconvinced by what happens now, especially as to the last label.
Equally I’m a bit concerned now that “minimum distance” could still be misinterpreted as relating to “implied labels” at the start and end of the track (in other words, the fact that some exported regions are determined by where the labels are in relation to the track start and end).
I’d like to see Daga’s input here, but I’m fine too that the first label (meaning after time zero) should appear even if the distance from the start to the first label is less than the “minimum distance” setting. I’d be reasonably happy with that even if the tin said “minimum track length”, because the default is not to export before the first label.
As to rationales, there could be alternative ones, much closer to what Analyze > Regular Interval Labels does. Note that does place a label at time zero, but on balance I’m fine that Silence Finder doesn’t.
Specifics: If I create that 16 seconds DTMF at 55% duty cycle, and generate 1 second of silence in front of it, then all is fine if “minimum distance” is off (I have label placement set to zero to make it less complex, and mimimum silence duration set to 0.18s to be less than the approximately one second silences).
But if minimum distance is set to 6 seconds, I get labels at 3s, 9.5s and just before 16s. Firstly, I don’t see a rationale for the first label at 3s instead of 1s. Second, I can see that final exported file of very much less than the “minimum length” being very irritating to some people. What I would have expected is a label at 1s, a label at 7.3s, and then like Regular Interval Labels, a choice (off by default) to produce the last label (13.7s) or not. That still gives us strictly what is on the tin (minimum distance between labels) and could (if we felt it less confusing) still let us reasonably call the control “minimum track length” or similar (if a last label default were off).
If you look at the case where the the minimum distance is set to exceed the 17s track length, maybe you should regard it as user error, but putting one label at just before 16s makes no sense at all to me. Either there should be an error, or the label should actually be placed at the distance they set, and they can export one file with audio in it if they “include audio before first label”
Yes I noticed too, and don’t feel strongly, but +1. I think it’s better it does the same as the original Silence Finder.
To take your test example - Whichever way you do it, dividing a 16 second track with a lot of evenly spaced silences into 6 second sections is going to leave an odd few seconds left over. The question, and this is a choice, is where do you want those odd few seconds to be? They can go at the beginning, at the end, or somewhere in the middle. My choice was to place the odd seconds at the beginning.
The main reason for my choice is as follows:
If there is a long section of audio, then a load of short sections, then another long section; is it better that the short sections get tagged onto the end of the first long section, or onto the beginning of the next long section? My thoughts are that usually the user would prefer the short sections to be tagged onto the end of a long section.
As an example, imagine a live orchestral recording - there will be a long section of music, then, (after any applause) there will probably be some shuffling in seats (which could produce a load of short audio clips separated by silences), then the next piece of music, then a bit more shuffling …
A) If we start from the first period of silence and work forward, when we get to the silences, there will be a marker after the piece has finished, then if the shuffling does not end on a “minimum track length”/“minimum distance between labels” point, there will be shuffling and silences tagged onto the beginning of the next piece of music.
B) If on the other hand, we count backward from the final marker, there will be a marker placed just before the beginning of the second piece of music, which will probably be preferable when it is burned to CD. (any extra shuffling and silences will be on the end of the previous track.
Another consideration is:
Is it likely that the user would; stop the recording at the end of the record/lecture, and/or trim the end of the recording before splitting into CD “tracks”. This would make the last section “correct”. In determining the split points where the audio sections are short it would be better to “count backward” from the next split point.
Is it likely that the user would; start the recording during a long audio section, and/or trim the beginning of the recording before splitting into CD “tracks”. This would make the initial section “correct”. In determining the split points where the audio sections were short it would be better to “count forward” from the previous split point.
I can see that logically it would be better to start from the first silence and work forward. In your test example this would give markers at something like, 1 second, 7 seconds and 13 seconds. However, I’m not sure that would be the most useful for real world situations.
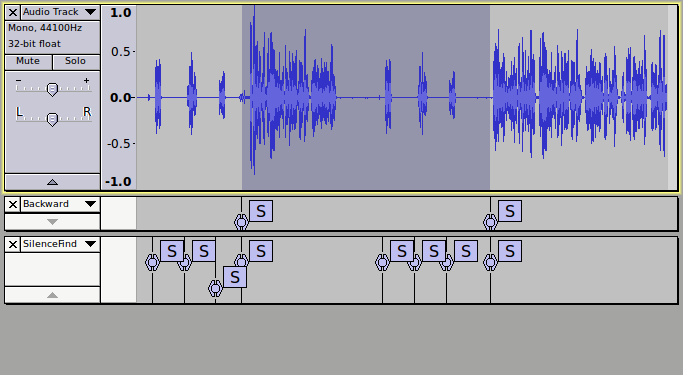
Here’s a comparison - this is the effect as it currently is. The first label track shows the effect of “minimum distance between labels”. The second label tracks shows the normal silence finder.
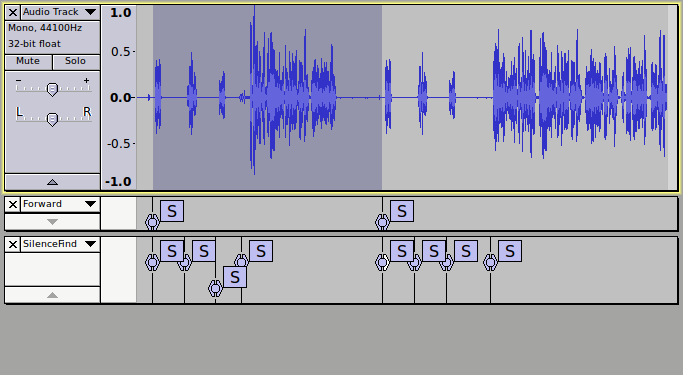
And now here’s the effect if we take the “logical” approach. The first label track shows the effect of “minimum distance between labels”. The second label tracks shows the normal silence finder.
We could go a lot more complex with this and have “target” of “don’t split shorter than [seconds]”. The idea here being to first mark sections that are longer than the target minimum length, then group shorter audio clips together. This is quite a bit more complex to implement, and I’m not sure that it is worth it. Also, how would such a strategy cope with your test? Would there be just one marker before the end of the first silence? Would there be no markers? Would it be split into “target” length sections? If split into target length sections, where do the odd couple of seconds go - at the beginning, the end, or in the middle?
Thanks for thinking so hard about this and possible scenarios. I wonder a bit if we should KISS (keep it simple, stupid) and KIL (Keep it logical) …
Can we make all those assumptions you were making? Personally I actually like a bit of shuffling and final silences penetrated by final coughs before a live track starts. It sets the scene, builds expectation and gives me time to start concentrating. I think more than a minority of live tracks will not go “straight in”.
The test case is obviously artificial but it’s not totally unlike a pop album with a starting “silence” then a number of equal length tracks divided by equal length silences. Counting backwards means the user won’t export the first track on the album unless they “include audio before first label”. The behaviour is also hard to understand if directly compared with what happens when the “minimum distance” is off. Also, how about Sound Finder? We want “minimum length” there too - does counting backwards make sense there?
I agree if I make my test case a bit more like an album capture by adding silence at the end, I then get the last label after the end of the last “track”. However we might be dealing with a pre-existing file where the end silence has already been removed. Even if we aren’t, I still think an option to not produce the last label would be useful and intuitive (rather than have an exportable region that could be much shorter than the minimum).
In sum, if we need to count backwards, I think there has to be an option to count forwards. And we’re then going to need a help screen/file to explain the cases where one behaviour would be better than the other.
I think that could be a reason not to pursue this level of complexity. A power user might find other ways to handle this such as with selective use of Truncate Silence.
I assume this control could either replace the minimum distance control or be a second method of grouping by length? As the only “length” control it could be hard to get across what it does. As a second length control, we could intimidate the new user with too many hard-to-grasp options, which is a real concern with this effect.
Having said all that, I still feel a bit tempted by this idea if this was the only distance choice. For my test case, I would assume that although logically it should either produce no markers or do a normal split as if the control was off, the most sensible thing would be for it to split into “target” length sections, “odd” seconds at the end (and possibly with an option to not produce that end label).