I’ve taken on the project of editing and mixing an interview-format podcast. Interviews are conducted over the phone, recorded with Instant Teleseminar. In the one I’m working on, the phone connection was dropped midway, and they reconnected to continue the interview, so I have 2 separate (MP3) files to work with. I suspect that the interviewee changed phones, because the tone of her voice is considerably different – in the first part her voice sounds bass-y and a little muffled; in the second part it sounds like a normal recorded telephone voice. When I join the two, the change in tone is jarring. It sounds like a different person. Since the interviewer’s voice doesn’t change, I can’t just do a global EQ on it.
My only solution right now is to include a snippet of the dropped-call-reconnect process so the listener will have a reference for the change in tone. But I’m hoping someone here will have a better idea for balancing the tone of the interviewee’s voice.
I’ve attached 2 short snips – both have interviewer first, interviewee second. Thanks for any light you can shed.
When I join the two, the change in tone is jarring.
Almost like one is a cellphone and the other is a landline?
You have no choice but to find the least-worst custom equalization by experiment and apply it in the largest phrase chunks you can, individually, one after the other. You’ll need to balance volume as well. Do they like to interrupt each other? You’ll be at this a while. When do you have to present the finished show?
I have some production thoughts.
— The Producer needs to know to catch those. There has to be a feedback pathway between your editing problems and the live production, otherwise they’ll just keep happening again and again and again… This is the person when, during a live interview the guest st…nd…r…bu…a… pulls the plug and says “we seem to have lost Joe Smith.”
— You are about to experience the reason we recommend very strongly not to do production in MP3. MP3 has its own talking-in-a-wine-glass sound distortion and it gets worse as you do more and more effects. You can’t stop it. That’s what happens whenever an editor program has to do surgery on an MP3 (or any compressed) sound file.
This is MP3 hosing you in addition to the actual show damage.
— I bet you’d give a limb to be able to split the two people talking into their own sound files. I have never done this, but I know people who capture telephone conversations via Skype cross-connect (paid service, last I checked) and use Pamela Professional or Pamela Business software to capture the sound. Both of those paid packages have an option to split Near and Far onto Left and Right of a stereo show (independent tracks) to make editing easier. They will do it in high quality WAV sound format, too.
I tried a first pass to equalize the muffled one into a crisper sound, but it just got honky on me. It’s going to take more study.
Thanks for your reply, Koz. some great thoughts there.
The producer/host of the show has no experience with podcasting, microphones, audio editing, or – apparently – basic conversation. She interrupts, talks over, hems and haws, uses the whole range of filler noises (“and um” “soooooo” “y’know”), her sentences trail off, etc, etc. Some of this is easy to edit; some not so much.
I appreciate your thoughts on production. I am subcontracted and have no direct contact with her, and no control over the type of files I get to work with. I’m aware of the lossy compression of MP3 (the JPEG of audio…). I would dearly love to split the voices into separate files but don’t have the option. I have passed on to her suggestions for production values, speaking habits and sound quality, etc. She has improved slightly over the 20 or so programs I’ve edited for her.
What I was really hoping was that there was a tool I didn’t know about that would do for tone what a compressor does for volume – just level it all out. You’ve relieved me of that fantasy, so I’ll just get to work on whatever compromise I decide on. I’ve got a week or so before it gets published. Frustrating, but I like a challenge…
Ah. So you’re the audio Philosopher’s Stone, tasked with turning base dialogs into gold.
Some of this is easy to edit; some not so much.
I worked on The McLaughlin Group, apparently still on the air. Camera was challenging because you never knew which of the four guests was going to yell louder and needed coverage—from the three total cameras for five people.
John McLaughlin has no sense of metre, rhythm and timing. Zero. The countdown at the beginning of the show is entirely for everybody else’s benefit because if you give John “Four, Three, Two…” he will have no idea where or when “One” is. This makes cutting simple promotional announcements a complex nightmare. They all have to be cut in formal editing. There’s no such thing as counting down and pressing crash record like we do with everybody else.
I get it. The main contractor doesn’t know how to handle it, so you’re the one who will fix it for him…
There are some tools that might help. They contain a spectral analyzer, allowing export of the spectral data, to be used to guide the EQ.
It will take a lot of experimenting the first time, but will speed up the work later on. I’ve never used them for something like this, but it’s worth looking into and there is a demo available for download.
This last one is a maybe. It’s really a denoiser, but it could be worth your time trying the demo as it is a good and flexible denoiser and it comes with a standalone application.
I also don’t know if all of these work with Audacity.
Thanks much, Koz, Cyrano and Gale. I guess I have some experimenting to do. Glad I have time to give to it. My big impediment here is that I’m not a studio/recording sound guy. I spent 30+ years owning and operating my own sound systems for my acoustic bands and others playing live, so my ear is good, I know what I want, and I can coax it out of almost any board (though Mackie is my fav). Editing files that are given to me is relatively new. I seem to be doing OK as she is happy with the work I’m doing – so much so that I suspect she now believes that she can send me anything and I will work magic on it. Ah, the travails of genius…
By the way, if anyone can direct me to a tutorial on how to use the forum itself, I’d be much obliged. All I can find is “How to post a question”, but no instructions on how to use the “Quote” button, for instance. (I can’t get it to work in any practical way.)
I tried a “by eye” version of that earlier, and even though mine was terrible, I think you can do it, too. But you still have to select each dialog fragment by hand and fake the ones that overlap. What fun.
Koz – That might be my best bet. I’d only need to EQ the first file, matching it up as well as possible to the second which has a more normal sound. Once I got the EQ set I should be able to get through it in reasonable time.
This is a juggling act between Analyze > Plot Spectrum and Effect > Equalization.
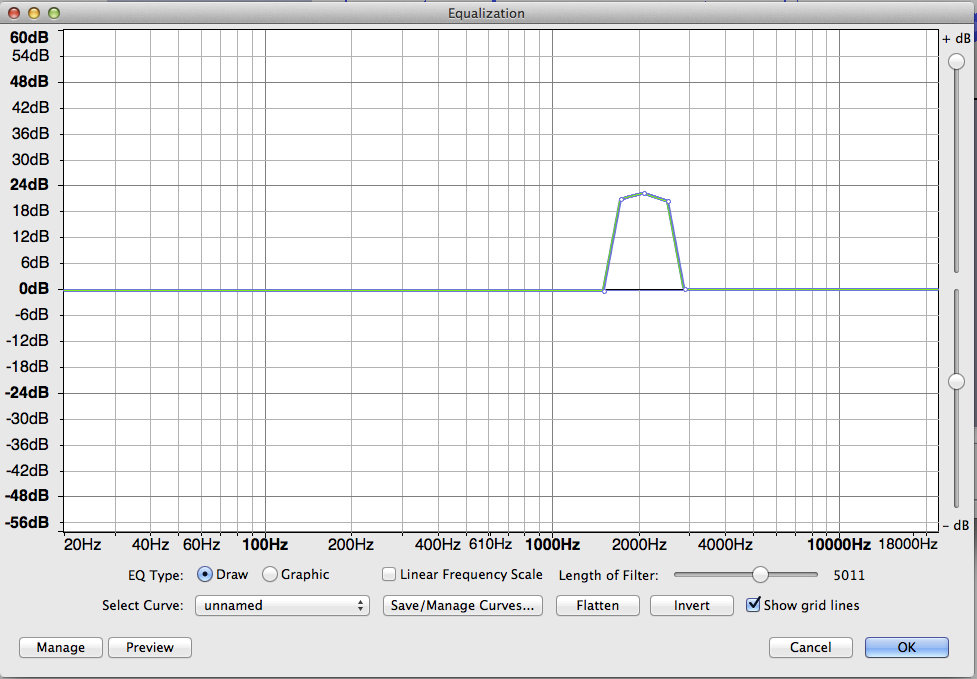
Plot Spectrum is a readout of what you did and Equalization is the action tool. Both tools get clearer and more detailed as you grab one corner and pull larger. They both feature pitch tone along the bottom and loudness along the left. Thunder, rumble, large trucks and metrobuses at the left and Hummingbird conversation, bat echo location, and crisp, crinkling paper to the right.
There are a couple of notable tones in the middle. Between 3000 and 4000 is baby screaming on a jet and fingernails on blackboard and 300 to 3000 is telephone conversation. That’s why when you analyze your works, they all stop at roughly 3000. The voice system doesn’t generally support any tones above that. They’re not important for intelligence.
In theory, you plot spectrum on a portion of normal voice and save that via screen capture (Audacity will not put two of them on the screen). Then analyze the muffled version and save that. The equalization correction is the difference between them.
Piece of cake!!
Attached is my first pass. The little dots on the green line are click and drag control points. Up is louder. The far left and far right in the haystack are anchor points to keep the whole line from moving and the ones in the middle are the actual correction. Delete a point by dragging it off the graph.
no instructions on how to use the “Quote” button, for instance.
I use some of those controls wrong, but it’s instructive as to how they work. Those decorative controls are all tags and you can type them manually.
This text will be quoted
This text will be bold, this text will be in italics
and this text will be underlined.
You can totally type them all out manually and I sometimes do. The forum automatically “knows” what you want. Normal people drag-select some text and press the control button at the top of the text window which automatically applies the tags. You can apply more than one (the shortcut buttons are recommended). Note “quote” has some spacing rules that will be obvious as you use it.
One other handy tool. I use these so automatically I lose them.
There is a button at the bottom of the text windows called “Preview.” That will show you what the final post is going to look like without showing the whole world. That’s when you find you applied the tags wrong or in the wrong place or order—or oddly, spelled something wrong. Spelling errors don’t appear until you actually post, or seem to. There’s some psychological graphic/optical trick to that.
Koz - - Don’t put any more work into this - - I deeply appreciate what you’re doing, but you’re already well past the effort I’m going to invest until I find out how much time she wants me to put into it. At this point I’m leaning towards my original idea of just incorporating some of the conversation around the dropout and reconnect so the transition isn’t so jarring. I have a feeling she’ll agree to that rather than pay me extra. She’s obviously not that particular, but, dang, I hate putting out a poor quality product no matter the material I’m handed.
You can totally type them all out manually and I sometimes do. The forum automatically “knows” what you want. Normal people drag-select some text and press the control button at the top of the text window which automatically applies the tags. You can apply more than one (the shortcut buttons are recommended). Note “quote” has some spacing rules that will be obvious as you use it.
OK, this makes sense. Copy and paste what you want to quote into a reply box, then manually type in the tags or hit the button at the top. Obvious in retrospect…
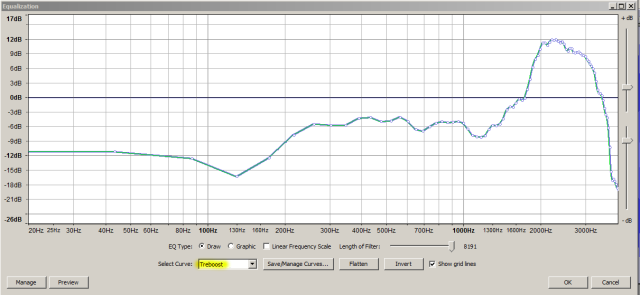
It is possible to match the equalization, but you can still tell the difference because the “sample 1” interviewee phone has more digital-compression-artifacts, (sounds more computery) …
What I did was apply the custom “Treboost” equalization-curve shown below (and XML attached) to the muffled (“sample 1”) interviewee … Treboost.xml (17.9 KB)
Then apply Steve’s “level speech” effect at ~90% …
At this point I’m just going to say thank you all for your thoughtful and detailed replies. I have more info now than I know what to do with, and it’ll take some time to work through it. (You may have missed the part where I admit I’m just a humble live-sound man and not an audio engineer. ) I’ll continue to read every response, but I may not reply to each one.