I’m very interested in using subliminal messages to improve myself, but I don’t always enjoy music, especially when sleeping. This was recommend on YouTube (but I don’t understand what it does to the audio file):
;nyquist plug-in
;version 1
;type process
;name "Subliminal..."
;action "Subliminal..."
;control carrier "Carrier" real "Hz" 17500 14000 20000
(setf *nyquist-srate* (/ *sound-srate* 2.0))
(setf carrier (max 14000 (min carrier (- *nyquist-srate* 3000))))
;; We have two Nyquist frequencies, carrier/2 and *sound-srate*/2.
;; The CUTOFF is the maximum allowed frequency in the modulator.
;; It must not be greater than carrier/2, but also not greater than
;; the difference between the carrier and *sound-srate*/2, because
;; otherwise the modulated carrier aliases.
(setf cutoff (min (/ carrier 2.0) (- *nyquist-srate* carrier)))
(defun cut (function sound frequency)
(dotimes (ignore 10 sound)
(setf sound (funcall function sound frequency))))
(defun subliminal (sound)
(let ((result (mult 2 (cut #'lowpass8 (hp sound 80) cutoff)
(hzosc carrier))))
(cut #'highpass8 result carrier)))
(if (< *sound-srate* 44100)
;; (princ "The track sample frequency must be minimum 44100Hz.")
(princ "Die Samplefrequenz der Tonspur muss mindestens 44100Hz sein.")
(multichan-expand #'subliminal s))
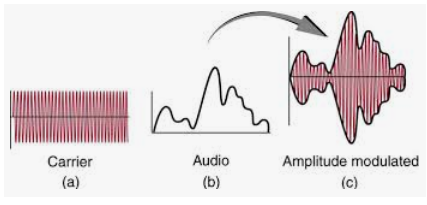
Basically it’s like how medium wave (AM) radio stations superimpose audio onto radio waves, but rather than superimposing onto a “carrier” radio wave, it superimposes the audio onto a “carrier” very high frequency audio wave. Because adult humans are generally only able to hear sounds up to around 16000 Hz (depending on how good your hearing is and how much damage has been done by exposure to loud noise), very high frequencies (in the region of 17000 Hz) are inaudible to most people.
There’s a crazy idea that people can somehow subconsciously hear the very high frequency carrier wave (even if their hearing is so badly damaged that there is zero response from the cochlea, and somehow “demodulate” the signal (even though the person may have no idea what “demodulation” is), and that the decoded speech will “reprogram” them in some way. There is zero verifiable evidence to support this crazy idea.
It seems to create a little radio station only instead of broadcasting a powerful signal from a tall tower, it does it with an ultra-sonic tone (dogs and bats can hear it).
One problem with most tools like this is testing. There are many tools to test if an audio system is working and if it’s not, what’s wrong with it. No such tools for subliminal listening. The user just has to take it all on blind faith.
Another more serious problem is physical. Most headphones and speaker systems won’t reproduce ultrasonic tones, so that snaps you back to: How do you know it’s working?
The program notes have you using 44100 digital sampling rate minimum, and I agree, I would be more likely to use 48000, the video sampling frequency, or higher. If you go higher, then the playback system has to be able to play the show. Whatever you do has to make it through your soundcard.
This at least seems to correspond somehow to what I’ve gathered when searching how silent subliminal messages are made. This is what I’ve understood silent subliminal messages to be:
Removing the sound of the waves
Slightly changing the Alpha wave frequency
High pitched sounds that are out of the conscious hearing range of humans
Same waveform as a normal song has
“The audible statements are then modulated using EQ, so that the voice can no longer be heard within the range of human hearing.”
No. It can’t do that. If it does, there’s no message. What it does is translate the sound of the waves to a domain only the subconscious can understand.
Slightly changing the Alpha wave frequency
That’s another speaker or headphone problem—getting them to respond to Alpha waves at all. And you can’t change the frequency a lot or they stop being Alpha waves. Did they discuss what happens when your Alpha waves and the message Alpha waves collide? Like when your head is trying to go into REM sleep? Without dreams, your body stops repairing itself.
Same waveform as a normal song has
Before you convert it, yes. After you convert it, it will look like standard AM or radio waves.
High pitched sounds that are out of the conscious hearing range of humans
Right. That one’s correct. The problem is how to pull all those tricks together into one environment or application—remembering there’s no tests for this.
What’s the goal? Do you want it to give you six-pack abs while you sleep? That would be my goal.
That would be my choice for “How Not To Produce A Video” video. I gave up watching it and just used the code as supplied. The presenter used a text to speech converter rather than recording their own voice. And then it failed. Then they said it was going to fail.
That’s impressive. I think they made all the teaching production errors.
I think the presenter made a not-obvious error. You can’t go on for several sentences in subliminal. That won’t stick. The message has to be very short and repeated.