Hi. That was me. I’m not on discord very often, and I find discord pretty bad for coherent discussion, whereas on this forum you get your own topic thread to discuss your topic without interruption.
The forum is also much better for displaying code. Use the “</>” button to enter “code tags” that look like this:
[code][/code]
then enter the code between the [code] and [/code] tags so that it looks like this:
[code]
Code goes here.
Line indentation works inside a code block.
[/code]
and it is displayed on the forum like this:
Code goes here.
Line indentation works inside a code block.
OK, I think that can be done, but we need to frame the specification more precisely before we start.
If you zoom in a long way on an audio track, you will see the waveform, like this:

Notice that the waveform is going up and down, passing through zero thousands of times per second.
Obviously you don’t want your high/ mid/ low tones to be switching thousands of times per second.
Zooming out a bit, we see something like this.
The picture below shows a female voice saying the words “expecting her mother to be somewhere near”:

We can now see the “shape” of the audio, which is what I think you want to track.
To get the “shape”, we need to be looking at some kind of “average” level, by stepping through the waveform in small blocks.
I would guess that we would need blocks of about 1/10th of a second, so we are tracking the average level in 0.1 second steps.
A common way to measure an “average” level of a waveform is to measure the “RMS” level. This is a good way to measure the average level as it takes care of the fact that the audio has positive amplitude (above the central “0.0” line in the track) and negative amplitude (below the central line).
“RMS” stands for “Root Mean Square” - if you’re not good at maths, then it’s probably sufficient to just think of it as a special kind of “average”.
For our initial tests, we will run commands in the Nyquist Prompt.
In modern Nyquist, selected audio can be accessed from the symbol TRACK (Nyquist is a “case insensitive” programming language, so TRACK may also be written as track).
Nyquist also has a command for calculating RMS: Nyquist Functions
So let’s try that, using TRACK as the audio (a selection in a mono audio track) and 10 as the RATE (measuring the selected audio in blocks of 1/10th of a second - that is, 10 blocks per second):
(rms *track* 10)
When I apply this code (via the Nyquist Prompt) to the audio shown above, the result is this:

 It’s gone!
It’s gone!
Well actually, no. It’s still there but it is now much shorter.
The RMS function with RATE set to 10, takes blocks of 1/10th of a second, calculates the RMS (“average”) for that block, and returns one sample for that block. Each 1/10 second is now represented as a single sample.
Let’s zoom in really close:

Now we can see that the waveform is following the “shape” of the audio. Perhaps not enough detail, so let’s try increasing the RATE (smaller blocks).
(rms *track* 1000)
This will measure 1000 blocks per second, with each block being 1/1000th second (1 ms):
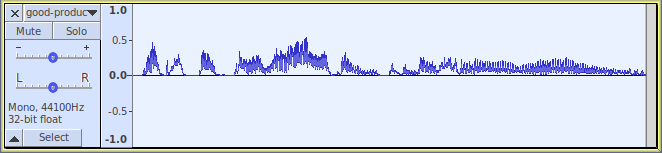
Hmm, perhaps the block size is a bit too small now - you probably don’t want it to be as wiggly as that.
Have a play with this code, and work out a suitable value for RATE.
Once we’ve decided on that, the next thing will be to decide exactly what we mean by “high” and “low”.
