Dude, amazing work, I didn’t expect to see it being updated. I used in the past ERA bundle and their tools for audacity were terrible, they didn’t reduced room reverb like it was promised but they distorted voices as hell. Gonna use yours for much longer since my podcasts are around 1h-1:30h. I had to use it bit by bit in portions of 10-15 minutes. Amazing work.
I know that it’s a bit late with answer but.
I had around 700gb, 16 gb of ram, it happend to me with some plugins in the past like era bundle, but they had issues with audacity and many users were aware of that. Like creator explained, it was due to his code. Appreciate your highly detailed response. New updated version of de-reverb is working like a charm.
Weird but after a while dereverb stopped working, tried to re-add a plugin but it’s just doesn’t work for me and I haven’t did any audacity update.
I am going to try this plugin. Hope it will work for me.
Hello sanjaykumar12, welcome to the forum!
Does the plugin work for you as expected?
Hey jozefh! Just wanted to say thanks for making the plug-in–it’s working great.
I’m not sure if it’s because of my audio type (I’m splitting a conversation so there are many gaps in my mono track), but the progress bar always get stuck in the middle before continuing with a longer estimated time. Small UI thing, mostly wanted to say thanks
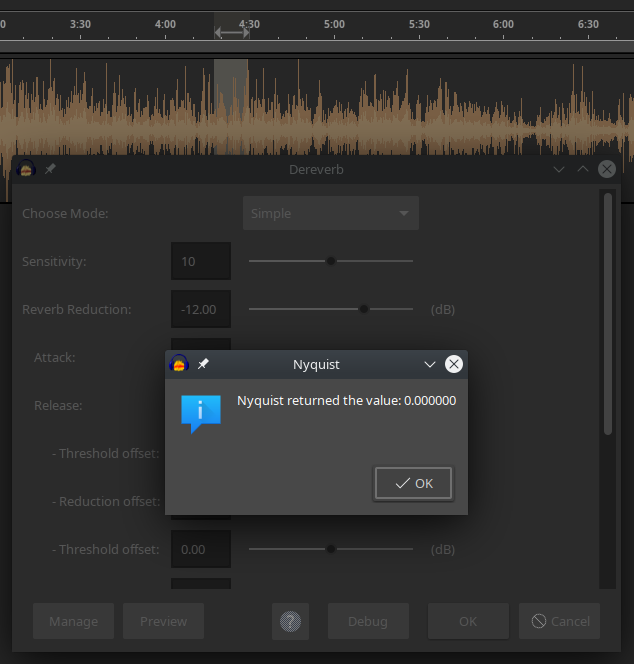
The plug-in is not working for me at all. I select the audio (~28+) and run the latest dereverb.ny I could find (at the beginning of this post) but when I select Dereverb in Effects using the default settings or with the settings modified to “Sensitivity: 12” and “Reverb: -15 db” and everything else the same, I get nothing. The plug-in doesn’t run. “Edit>Undo” doesn’t give me anything to Undo. When I press “Debug” I get:
error: bad argument type - #(#<Sound: #0000016C8AEC32E8> #<Sound: #0000016C8AEC3518>)
Function: #<Subr-SND-AVG: #0000016C8B2162E0>
Arguments:
#(#<Sound: #0000016C8AEC32E8> #<Sound: #0000016C8AEC3518>)
9016
9016
1
Function: #<FSubr-SETF: #0000016C8B20E8A0>
Arguments:
MS
(SND-AVG (MULT (FILTER *TRACK* HPASS LPASS) (FILTER *TRACK* HPASS LPASS)) STEP STEP OP-AVERAGE)
Function: #<FSubr-LET: #0000016C8B20EB88>
Arguments:
((HPASS (NTH 0 PARAMS)) (LPASS (NTH 1 PARAMS)))
(SETF STEP (BEST-STEP-SIZE LN))
(SETF MS (SND-AVG (MULT (FILTER *TRACK* HPASS LPASS) (FILTER *TRACK* HPASS LPASS)) STEP STEP OP-AVERAGE))
(WHEN (> (SND-LENGTH MS 2) 1) (SETF STEP (SND-LENGTH MS NY:ALL)) (SETF MS (SND-AVG MS STEP STEP OP-AVERAGE)))
(LINEAR-TO-DB (SQRT (SND-FETCH MS)))
Function: #<Closure-GET-RMS: #0000016C8B19CBB0>
Arguments:
(NIL 400 0 0)
81290117
Function: #<FSubr-LET: #0000016C8B20EB88>
Arguments:
((FILTERED_SOUND (FILTER *TRACK* (NTH 0 PARAMS) (NTH 1 PARAMS))) (REDUCE (DB-TO-LINEAR (+ REDUCTION (NTH 2 PARAMS)))) (THRESHOLD (DB-TO-LINEAR (+ (GET-RMS PARAMS LN) SENSITIVITY (NTH 3 PARAMS)))))
(SETF OUTPUT (SUM OUTPUT (MULT FILTERED_SOUND (DIFF (CLIP (NOISEGATE FILTERED_SOUND LOOK ATTACK RELEASE REDUCE THRESHOLD) 1) 0))))
Function: #<FSubr-DOLIST: #0000016C8B214EE8>
Arguments:
(PARAMS PARAM_LIST OUTPUT)
(LET ((FILTERED_SOUND (FILTER *TRACK* (NTH 0 PARAMS) (NTH 1 PARAMS))) (REDUCE (DB-TO-LINEAR (+ REDUCTION (NTH 2 PARAMS)))) (THRESHOLD (DB-TO-LINEAR (+ (GET-RMS PARAMS LN) SENSITIVITY (NTH 3 PARAMS))))) (SETF OUTPUT (SUM OUTPUT (MULT FILTERED_SOUND (DIFF (CLIP (NOISEGATE FILTERED_SOUND LOOK ATTACK RELEASE REDUCE THRESHOLD) 1) 0)))))
Function: #<FSubr-LET: #0000016C8B20EB88>
Arguments:
((LN (TRUNCATE LEN)) (OUTPUT 0))
(DOLIST (PARAMS PARAM_LIST OUTPUT) (LET ((FILTERED_SOUND (FILTER *TRACK* (NTH 0 PARAMS) (NTH 1 PARAMS))) (REDUCE (DB-TO-LINEAR (+ REDUCTION (NTH 2 PARAMS)))) (THRESHOLD (DB-TO-LINEAR (+ (GET-RMS PARAMS LN) SENSITIVITY (NTH 3 PARAMS))))) (SETF OUTPUT (SUM OUTPUT (MULT FILTERED_SOUND (DIFF (CLIP (NOISEGATE FILTERED_SOUND LOOK ATTACK RELEASE REDUCE THRESHOLD) 1) 0))))))
Function: #<Closure-MAIN_PROCESS: #0000016C8B19B380>
Arguments:
((NIL 400 0 0) (450 1500 0 0) (1330 4000 0 0) (4000 NIL 0 0))
Function: #<FSubr-CATCH: #0000016C8B210DD8>
Arguments:
(QUOTE ERR)
(MAIN_PROCESS (LIST (LIST NIL 400 1_BAND_R_OFFSET 1_BAND_T_OFFSET) (LIST 450 1500 2_BAND_R_OFFSET 2_BAND_T_OFFSET) (LIST 1330 4000 3_BAND_R_OFFSET 3_BAND_T_OFFSET) (LIST 4000 NIL 4_BAND_R_OFFSET 4_BAND_T_OFFSET)))
1>
Help I don’t speak this language!!
Thanks for any help,
RQRPD
Hi I tried to use your plugin (in Audacity 3.1.3), but it does not seem to do anything. It gives me the following debugging output:
error: bad argument type - #(#<Sound: #0x564db7667900> #<Sound: #0x564db7667988>)
Function: #<Subr-SND-AVG: #0x564db799b658>
Arguments:
#(#<Sound: #0x564db7667900> #<Sound: #0x564db7667988>)
163961
163961
1
Function: #<FSubr-SETF: #0x564db7993be0>
Arguments:
MS
(SND-AVG (MULT (FILTER *TRACK* HPASS LPASS) (FILTER *TRACK* HPASS LPASS)) STEP STEP OP-AVERAGE)
Function: #<FSubr-LET: #0x564db7993ec8>
Arguments:
((HPASS (NTH 0 PARAMS)) (LPASS (NTH 1 PARAMS)))
(SETF STEP (BEST-STEP-SIZE LN))
(SETF MS (SND-AVG (MULT (FILTER *TRACK* HPASS LPASS) (FILTER *TRACK* HPASS LPASS)) STEP STEP OP-AVERAGE))
(WHEN (> (SND-LENGTH MS 2) 1) (SETF STEP (SND-LENGTH MS NY:ALL)) (SETF MS (SND-AVG MS STEP STEP OP-AVERAGE)))
(LINEAR-TO-DB (SQRT (SND-FETCH MS)))
Function: #<Closure-GET-RMS: #0x564db78c3d68>
Arguments:
(NIL 400 0 0)
163961
Function: #<FSubr-LET: #0x564db7993ec8>
Arguments:
((FILTERED_SOUND (FILTER *TRACK* (NTH 0 PARAMS) (NTH 1 PARAMS))) (REDUCE (DB-TO-LINEAR (+ REDUCTION (NTH 2 PARAMS)))) (THRESHOLD (DB-TO-LINEAR (+ (GET-RMS PARAMS LN) SENSITIVITY (NTH 3 PARAMS)))))
(SETF OUTPUT (SUM OUTPUT (MULT FILTERED_SOUND (DIFF (CLIP (NOISEGATE FILTERED_SOUND LOOK ATTACK RELEASE REDUCE THRESHOLD) 1) 0))))
Function: #<FSubr-DOLIST: #0x564db799a260>
Arguments:
(PARAMS PARAM_LIST OUTPUT)
(LET ((FILTERED_SOUND (FILTER *TRACK* (NTH 0 PARAMS) (NTH 1 PARAMS))) (REDUCE (DB-TO-LINEAR (+ REDUCTION (NTH 2 PARAMS)))) (THRESHOLD (DB-TO-LINEAR (+ (GET-RMS PARAMS LN) SENSITIVITY (NTH 3 PARAMS))))) (SETF OUTPUT (SUM OUTPUT (MULT FILTERED_SOUND (DIFF (CLIP (NOISEGATE FILTERED_SOUND LOOK ATTACK RELEASE REDUCE THRESHOLD) 1) 0)))))
Function: #<FSubr-LET: #0x564db7993ec8>
Arguments:
((LN (TRUNCATE LEN)) (OUTPUT 0))
(DOLIST (PARAMS PARAM_LIST OUTPUT) (LET ((FILTERED_SOUND (FILTER *TRACK* (NTH 0 PARAMS) (NTH 1 PARAMS))) (REDUCE (DB-TO-LINEAR (+ REDUCTION (NTH 2 PARAMS)))) (THRESHOLD (DB-TO-LINEAR (+ (GET-RMS PARAMS LN) SENSITIVITY (NTH 3 PARAMS))))) (SETF OUTPUT (SUM OUTPUT (MULT FILTERED_SOUND (DIFF (CLIP (NOISEGATE FILTERED_SOUND LOOK ATTACK RELEASE REDUCE THRESHOLD) 1) 0))))))
Function: #<Closure-MAIN_PROCESS: #0x564db78becd8>
Arguments:
((NIL 400 0 0) (450 1500 0 0) (1330 4000 0 0) (4000 NIL 0 0))
Function: #<FSubr-CATCH: #0x564db7996118>
Arguments:
(QUOTE ERR)
(MAIN_PROCESS (LIST (LIST NIL 400 1_BAND_R_OFFSET 1_BAND_T_OFFSET) (LIST 450 1500 2_BAND_R_OFFSET 2_BAND_T_OFFSET) (LIST 1330 4000 3_BAND_R_OFFSET 3_BAND_T_OFFSET) (LIST 4000 NIL 4_BAND_R_OFFSET 4_BAND_T_OFFSET)))
1>
Can you confirm that your audio is mono?
Also created the account to say a big thank you! I’m helping my wife with her videos (pro bono) and so the recording conditions are not always perfect (to say the least). This has been a life saver !!!
1 Like
I am novice here and tried the plugins n.6 & n.7 of Jozefh under Audacity 3.5.1, however I was uncertain about the setting of those threshold and reduction, I tried different settings both simple and expert, and some settings from your suggestion was unable to apply
- Gate threshold for Low band = -17 dB
- Gate threshold for Low-mid band = -25 dB
- Gate threshold for High-mid band = -33 dB
- Gate threshold for High band = -40 dB
therefore I am trying to inquire here if you have any comment or guidance in this latest version of application 3.5.1, whether those plugins are still applicable and how should I configure in order to remove/surpress those echo/reverb from my meeting clip.
Thank you very much for your assistance!
j’a dore
Hello all! Thank you for all messages that I’ve received about this Nyquist plugin. I am glad that it is/was useful.
When I developed it, I was learning Nyquist language and this was one of my exercise projects. I have/had multiple ideas on how to improve Dereverb further, but then Adobe Enhance Speech (AES) and few other open-source projects for speech enhancing by AI (or machine learning techniques, ML) came. I believe this is the future for speech enhancing, like when we want to reduce a room reverb from the recording. AI systems are getting smarter rapidly and for a basic dereverbation (like my tool does), the AI systems do already well today. Especially, if you considered there are free AI options as well.
Of course, the most sophisticated solutions today would be a combination of AI and smart conventional pre- and post-processing. But this will also fade away in next years and AI will be sufficient for 90% of typical enhancing.
As you can see, my motivation to update and to keep the tool running is significantly lowered. But please let’s talk. Tell me if you still see a value in maintaining Dereverb Nyquist plugin. Is there a common scenario when you would use it over ML free tools like AES, Auphonic, VoiceFixer, Resemble and maybe others (list is still growing)?
If there would be a reasonable reason to not give up on this tool, I can update it. As you notice, the expert settings are not easily understandable if you do not know how the math of audio processing works. But this was a first generation, where I was focusing on Nyquist functionality. The goal was to make it work with default settings well, but when dividing into expert mode, I see it is tricky.
Please let me know what do you think?
1 Like
Hello all
First, I would like to thank jozefh for this plug-in, very helpfull to me.
I’m novice in this matter but installed it and try to use it in the simplest possible way…
Audacity release: 3.6.4
Dereverb release: the newest one available at the top of this topic: 7
The file I try to process is a mono 1h30 audio recording
The problem is that the process stop after a short ~30 to 40 s… It pop up says “Process completed”.
When using the debug, I get the following:

In particular, it says “The maximum number of sample blocks has been reached, so audio computation must be terminated. Probably, your program should not be retaining so many samples in memory. You can get and set the maximum using SND-SET-MAX-AUDIO-MEM. error: audio memory exhausted”
Could you help?
Many thanks
Please select a shorter piece of audio. If the audio you want to process is 1,5 hour, consider to split into 3 parts with 30 minutes duration.
Many thank for your quick answer.
Yes, doing this way, it works! ![]()
Thanks again
THANK YOU, @jozefh! This plug-in is simple to use and super-effective. I can easily explain my setup issues by saying “stairwell!”
Does anyone know of something this simple & effective that will work in realtime on MacOS? I’ve looked at a couple of options, but they seem to introduce more artifacts that this gem does not!
1 Like
I’ve tried this plugin in on Audacity 3.1.3 and 3.7.3 (current release) and the plugins doesn’t work. It doesn’t have any effect on my audio when I try to apply it and I get a debug button that shows the following below.
error: bad argument type - #(#<Sound: #00000298CC810238> #<Sound: #00000298CC810468>)
Function: #<Subr-SND-AVG: #00000298CCAC93A0>
Arguments:
#(#<Sound: #00000298CC810238> #<Sound: #00000298CC810468>)
2028
2028
1
Function: #<FSubr-SETF: #00000298CCAC1960>
Arguments:
MS
(SND-AVG (MULT (FILTER TRACK HPASS LPASS) (FILTER TRACK HPASS LPASS)) STEP STEP OP-AVERAGE)
Function: #<FSubr-LET: #00000298CCAC1C48>
Arguments:
((HPASS (NTH 0 PARAMS)) (LPASS (NTH 1 PARAMS)))
(SETF STEP (BEST-STEP-SIZE LN))
(SETF MS (SND-AVG (MULT (FILTER TRACK HPASS LPASS) (FILTER TRACK HPASS LPASS)) STEP STEP OP-AVERAGE))
(WHEN (> (SND-LENGTH MS 2) 1) (SETF STEP (SND-LENGTH MS NY:ALL)) (SETF MS (SND-AVG MS STEP STEP OP-AVERAGE)))
(LINEAR-TO-DB (SQRT (SND-FETCH MS)))
Function: #<Closure-GET-RMS: #00000298CCAB7EC0>
Arguments:
(NIL 400 0 0)
4113985
Function: #<FSubr-LET: #00000298CCAC1C48>
Arguments:
((FILTERED_SOUND (FILTER TRACK (NTH 0 PARAMS) (NTH 1 PARAMS))) (REDUCE (DB-TO-LINEAR (+ REDUCTION (NTH 2 PARAMS)))) (THRESHOLD (DB-TO-LINEAR (+ (GET-RMS PARAMS LN) SENSITIVITY (NTH 3 PARAMS)))))
(SETF OUTPUT (SUM OUTPUT (MULT FILTERED_SOUND (DIFF (CLIP (NOISEGATE FILTERED_SOUND LOOK ATTACK RELEASE REDUCE THRESHOLD) 1) 0))))
Function: #<FSubr-DOLIST: #00000298CCAC7FA8>
Arguments:
(PARAMS PARAM_LIST OUTPUT)
(LET ((FILTERED_SOUND (FILTER TRACK (NTH 0 PARAMS) (NTH 1 PARAMS))) (REDUCE (DB-TO-LINEAR (+ REDUCTION (NTH 2 PARAMS)))) (THRESHOLD (DB-TO-LINEAR (+ (GET-RMS PARAMS LN) SENSITIVITY (NTH 3 PARAMS))))) (SETF OUTPUT (SUM OUTPUT (MULT FILTERED_SOUND (DIFF (CLIP (NOISEGATE FILTERED_SOUND LOOK ATTACK RELEASE REDUCE THRESHOLD) 1) 0)))))
Function: #<FSubr-LET: #00000298CCAC1C48>
Arguments:
((LN (TRUNCATE LEN)) (OUTPUT 0))
(DOLIST (PARAMS PARAM_LIST OUTPUT) (LET ((FILTERED_SOUND (FILTER TRACK (NTH 0 PARAMS) (NTH 1 PARAMS))) (REDUCE (DB-TO-LINEAR (+ REDUCTION (NTH 2 PARAMS)))) (THRESHOLD (DB-TO-LINEAR (+ (GET-RMS PARAMS LN) SENSITIVITY (NTH 3 PARAMS))))) (SETF OUTPUT (SUM OUTPUT (MULT FILTERED_SOUND (DIFF (CLIP (NOISEGATE FILTERED_SOUND LOOK ATTACK RELEASE REDUCE THRESHOLD) 1) 0))))))
Function: #<Closure-MAIN_PROCESS: #00000298CCAB6690>
Arguments:
((NIL 400 0 0) (450 1500 0 0) (1330 4000 0 0) (4000 NIL 0 0))
Function: #<FSubr-CATCH: #00000298CCAC3E98>
Arguments:
(QUOTE ERR)
(MAIN_PROCESS (LIST (LIST NIL 400 1_BAND_R_OFFSET 1_BAND_T_OFFSET) (LIST 450 1500 2_BAND_R_OFFSET 2_BAND_T_OFFSET) (LIST 1330 4000 3_BAND_R_OFFSET 3_BAND_T_OFFSET) (LIST 4000 NIL 4_BAND_R_OFFSET 4_BAND_T_OFFSET)))
1>
If anyone could help me with this it would be greatly appreciated. There aren’t many free non-AI dereverb tools avaliable so a plugin like this would be invaluable, really appreciate the work that’s been done on it so far!
Plugin works with mono sound, not stereo. You can easily split stereo track into two mono tracks. If this is speech, probably the information in both mono channels is the same, so you can delete one of the channel and continue with editing of mono tracks.
1 Like
Awesome, converted it to audio and was immediately able to get an output! Thank you for the help, appreciate your efforts once again!
1 Like