Thank you for your time.
This is my current results:
A) ASCII only (all good!)
C:\tmp>python pipe_test.py
pipe-test.py, running on windows
Write to "\\.\pipe\ToSrvPipe"
Read from "\\.\pipe\FromSrvPipe"
-- Both pipes exist. Good.
-- File to write to has been opened
-- File to read from has now been opened too
Send: >>>
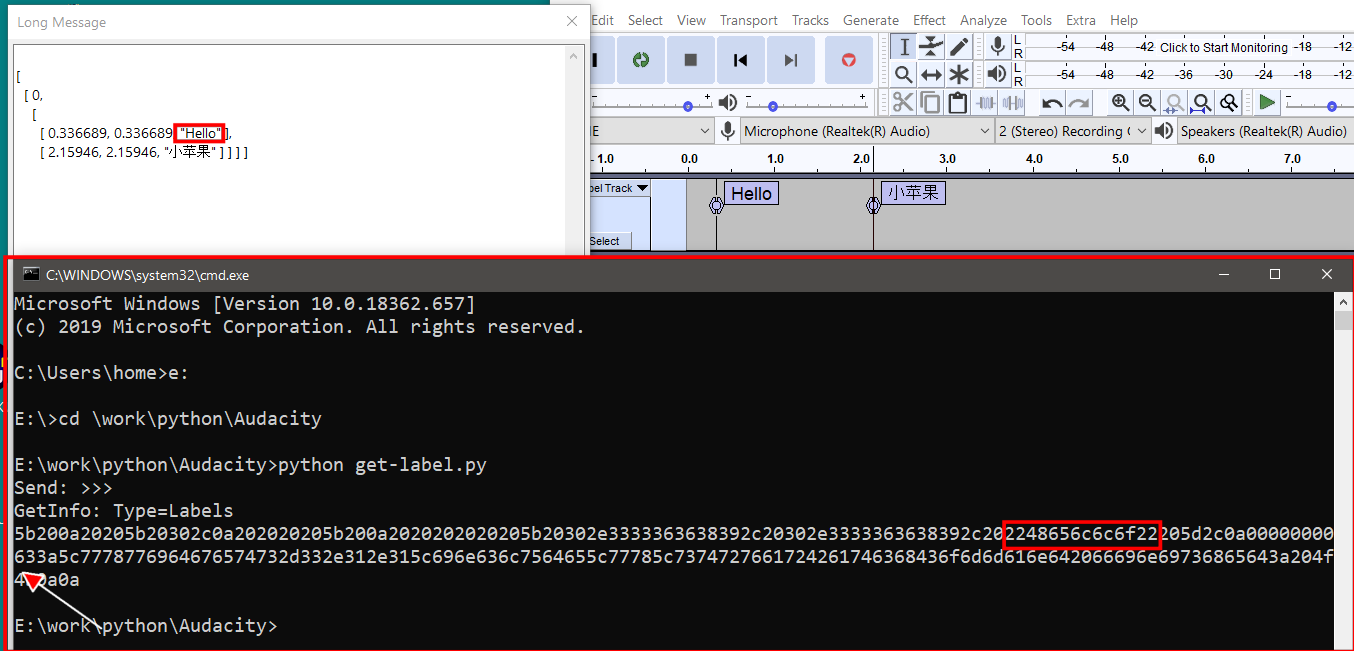
GetInfo: Type=Labels Format=JSON
Rcvd: <<<
[
[ 0,
[
[ 1.52091, 2.31039, "hello" ],
[ 3.47138, 3.47138, "world" ] ] ] ]
BatchCommand finished: OK
The scripts provided by Audacity assume that data is plain ASCII, and will not work with multi-byte Unicode characters. With Python3 you will probably see errors like:
"UnicodeDecodeError: 'utf-8' codec can't decode bytes in position x-y: invalid continuation byte
I should have said that “I think it should be possible to get …”
The “GetInfo: Type=Labels” can definitely handle multi-byte Unicode characters
(try it from Audacity’s “Extra menu > Scriptables II > Get Info”).
I “assume” that Python3 is capable of accessing that data, but you would need to write your own Unicode compatible functions to read and write Unicode data to/from Audacity.
It took a while until I found where to activate the Extra-menu
Yes, that works. I can write a Python script to read the JSON output. But how do I pipe that output to my script?
With my limited Python skill and Google’s help , I tested the UTF-8 read/write:
import io
encoding = 'utf8'
with io.open('utf-8.txt', 'r', encoding=encoding, newline='\n') as fin:
text= fin.read()
print( text)
with io.open('utf-8_out.txt', 'w', encoding=encoding, newline='\n') as fout:
fout.write(text)
then I modified the pipe_test.py:
FROMFILE = io.open( FROMNAME,'r', encoding='utf8', newline='\n')
*snip*
while line != '\n':
result += line
line = FROMFILE.readline()
print(" I read line:["+line+"]")
return result
I guess I can leave TOFILE as it is.
This is my output:
GetInfo: Type=Labels Format=JSON"
I read line:[[
]
I read line:[ [ 0,
]
I read line:[ [
]
I read line:[ [ 0, 0, "Hello" ],
]
I read line:[ c:\wxwidgets-3.1.1\include\wx\strvararg.BatchCommand finished: OK
]
I read line:[
]
Rcvd: <<<
[
[ 0,
[
[ 0, 0, "Hello" ],
c:\wxwidgets-3.1.1\include\wx\strvararg.BatchCommand finished: OK
Is Audacity writing an UTF-8 pipe?
mod-script-pipe is a DLL. I couldn’t look into it.
On Linux, with Python 3, this will read the return message and print as hex values. You may notice that with two labels containing “小苹果”, the printed data is a mix of UTF-8 and non-UTF-8 (UTF-8 and “latin 1” characters perhaps?).
import os
import sys
PIPE_BASE = '/tmp/audacity_script_pipe.'
WRITE_NAME = PIPE_BASE + 'to.' + str(os.getuid())
READ_NAME = PIPE_BASE + 'from.' + str(os.getuid())
EOL = '\n'
write_pipe = open(WRITE_NAME, 'w')
read_pipe = open(READ_NAME, 'rb')
def send_command(command):
"""Send a single command."""
print("Send: >>> \n"+command)
write_pipe.write(command + EOL)
write_pipe.flush()
def get_response():
"""Return the command response."""
result = ''
line = ''
last = ''
while (last != b'\n' or line != b'\n'):
#result += line
last = line
line = read_pipe.read(1)
print(line.hex(), end=' ')
send_command("GetInfo: Type=Labels")
get_response()
I modified the code and write the output to a binary file:
write_json = open('labels.json', 'wb')
*snip*
while (last != b'\n' or line != b'\n'):
last = line
line = read_pipe.read(1)
print(line.hex(), end=' ')
write_json.write( line)
You’re getting less on Windows than I do on Linux. Your version appears to be completely choking on the Unicode characters.
For the current version of Audacity, it appears that the script pipe module does not support Unicode at all on Windows. I’ve written to the developers about this, but I’m not hopeful of Unicode support being added any time soon, unless the problem was just an oversight that can be easily fixed.
I’ll write back if I get more information. Sorry I couldn’t be more help.