hi there is there any way we can implement this: https://sourceforge.net/p/gnaural/feature-requests/28/ ? by converting the affirmations into binaural beats? can we write a plugin for this? any answers how to do it?
this is how we do it. we calculate the frequency’s the words are used by frequency, then we have a constant signal generated. that’s how it’s is to be done. and we need some controls to triangle, sine, and pulse wave form can some buddy write a script for me?
can some body write me a script for this?
Spoken words do not usually have a discernible “frequency”. When there is a discernible frequency it is usually called “singing”.
This graph shows the frequencies present when I say the word “Audacity”:
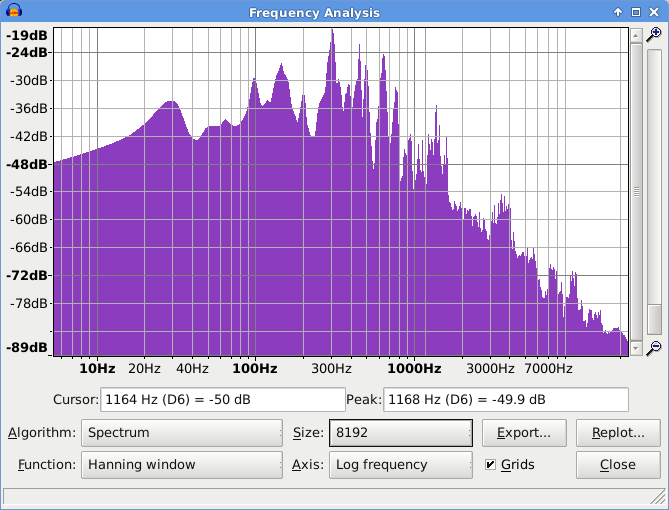
Each peak in that graph represents a different frequency, and note that between the peaks there are other frequencies that are at a lower level than the peaks.
Choosing one frequency from the word to represent that word is almost an arbitrary choice.
“Binaural beats” are created by generating two constant tones that have slightly different frequencies. I don’t see how you intend to extract even one constant tone from speech in any meaningful way.
can the frequencies be converted from instantaneously from the pitch or by musical notes to multiple frequencies at once?
i think that’s how binaural beats work.
This explains how binaural beats work: Beat (acoustics) - Wikipedia
you can do binaural beats by musical note and also we have constant signal filter effect already we can use that code. i used pitch detector for detecting musical notes code and modifying this code. but thing is pitch detector has have the audio affirmation sampled at 96000 Hz per a sample rate. so that it can detect note from 20 - 100 and 100 - 10000 surely we can use this code as well. i used the harmonica generator for this I’ve tried it this way this works. we can also use surf beats too. we can implement midi notes for this. and surely we can use the code called state variable filter just modify that code to convert affirmations to binaural beats as well surf beats.
steve can you please modify those effect and filters and write the codes that i’ve said?
Sorry yugioh47 but I can’t make sense of what you are asking for. My understanding of binaural beats is that they are created by playing 2 continuous tones, one into one ear and one into the other, where the frequencies of the two tones differ by a few Hz. The difference between the two frequencies produces the “beat” effect. That concept of binaural beats appears to me to be incompatible with the concept of a rapidly changing complex sound, such as speech.
As I understand it, the idea of adding binaural beats to spoken affirmations is done by generating binaural beats in a standard way (such as using one of the “binaural beat” plug-ins), and overlaying the spoken words on another track. See here for how to combine a music (or binaural beat) track with a spoken word track: http://manual.audacityteam.org/o/man/tutorial_mixing_a_narration_with_background_music.html
There is a binaural beats plugin for Audacity … http://wiki.audacityteam.org/wiki/Nyquist_Generate_Plugins#Binaural_Tones_with_Surf_2 , but it’s not capable of speech sounds.
i’ve found this called silent subliminal messaging: https://forum.audacityteam.org/t/silent-subliminal-function/18148/1 . is there any where we can put this silent subliminal messaging into to a plugin?
ty steve. that’s what i was looking for subliminal messaging.
umm i found and example to “convert” affirmations that’s similar to subliminal messaging. here is the reference:
example
This example is about the simplest way to create a sound with Nyquist. The osc function generates a sound using a table-lookup oscillator. There are a number of optional parameters, but the default is to compute a sinusoid with an amplitude of 1.0. The parameter 60 designates a pitch of middle C. (Pitch specification will be described in greater detail later.) The result of the osc function is a sound. To hear a sound, you must use the play command, which plays the file through the machine’s D/A converters. It also writes a soundfile in case the computation cannot keep up with real time. You can then (re)play the file by typing:
exec r()
This (r) function is a general way to “replay” the last thing written by play.
Note: when Nyquist plays a sound, it scales the signal by 2^(15)-1 and (by default) converts to a 16-bit integer format. A signal like (osc 60), which ranges from +1 to -1, will play as a full-scale 16-bit audio signal.
i found this at: Nyquist Reference Manual
is there anyway we can use this example for converting affirmations into binaural beats?
use universal knowledge. ![]()
binaural beats are in the range ~0.1Hz to ~20Hz , the bare-minimum to reproduce speech is the range 200Hz - 4000Hz. i.e. it is impossible to convey speech with the limited frequency range possible with binaural-beats.
Modulating ultrasound with speech is possible , but only dogs & bats, (not humans), could possibly hear it properly.
oh i see. ok. thank you for the info.
Trebor i can hear the binaural beat in 17khz. that’s because i’m indigo crystalline. my hearing is much more then i thought. can you share the plugin with me?
Some of the content of that 17kHz recording I posted is a low as 13kHz, which is audible by most people. [ Telephone-quality voice has 4kHz bandwidth ].
Steve has posted several bits of code on how to produce so-called “silent subliminal” messages in Audacity ,
e.g. … https://forum.audacityteam.org/t/silent-subliminal-function/18148/5
Bear-in-mind there is no evidence that such messages can be understood. Truly-ultrasonic ones, (+20kHz), are inaudible to humans , (i.e. silent). Using a lower frequency shift , like my 17kHz version (above), is audible but incomprehensible.
As I wrote sveral posts ago, the same thing is available as a plug-in here:
can you name one of them? and give me a link to one of them so i can see that please?