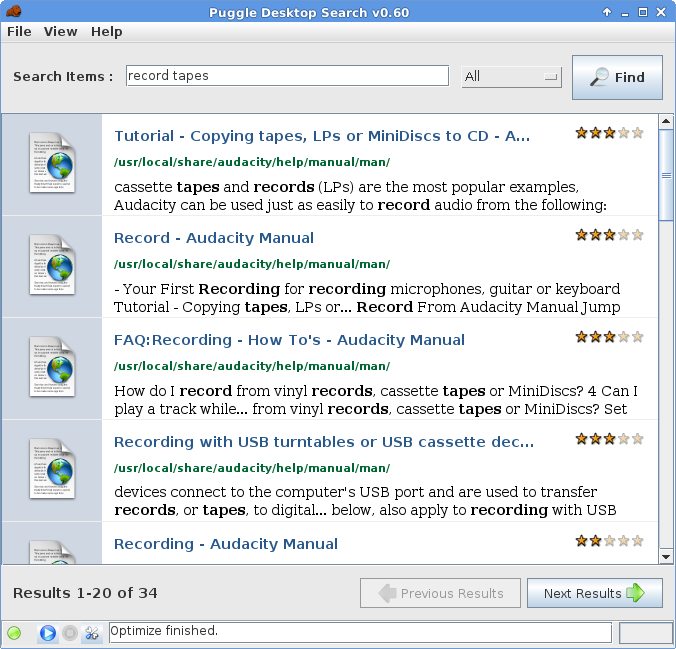
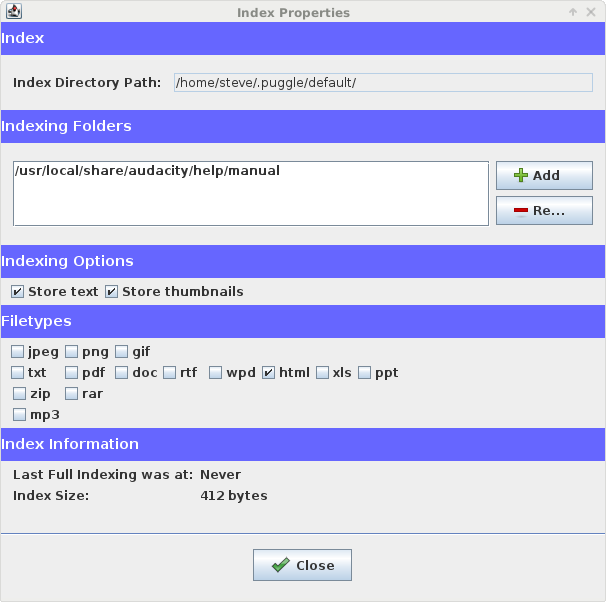
Interesting. I have now Puggle installed with just …help\manual\man indexed.
Puggle gets: AudManSearch gets: (comment)
search string
190 matches 113 matches (Puggle gets 77 extra matches for “settings” - see *below)
settings
17 matches 17 matches
portable
17 matches 10 matches (Puggle’s extra “settings” matches overlapped the other 7 "portable"s)
settings portable
1 match 1 match
“portable settings”
16 matches 9 matches (Both excluded the 1 match of “portable settings”)
portable settings -“portable settings”
0 matches 7 matches (Puggle’s extra “settings” matches overlapped the other 7 "portable"s)
-settings portable
20 matches 103 matches (Puggle: 20 vs 17 without the negation! I don’t get it. There were 190 "settings"s and 17 "portable"s).
settings -portable (Swapping the order of the terms makes no difference, nor does putting them in quotes, nor does using ‘!’ instead of ‘-’.)
1 match 1 match
settings portable “portable settings”
*I found that at least some (I’m guessing ‘all’) of the extra matches Puggle gets to settings and “settings” are because it accepts partial matches. “setting”, for example, is taken as a match to “settings”. Using quotes doesn’t force exact match.
Too bad Help doesn’t work. The subject list suggests the program is much more versatile that what I’m seeing. Or it could be that the missing Help text resides on the developer’s computer as a “to do” list. I don’t understand some of what Puggle is doing.
What’s to like about Puggle?
It shows a sample of the matching text for each match.
It has stars - The number of stars highlighted for each match give some metric of relevance, maybe whether it’s in the title, in a keyword list, or number of occurrences in the text.
It doesn’t have the issue my .bat script has with getting control back after initially starting the HTML viewer (Mozilla).
It’s pretty fast. OTOH, the .bat script only takes a few seconds to scan the whole folder the first time it’s run. If you run it again (or do a new search), Windows has all the files cached anyway and then most searches take a second or less.
The only behavior I can confidently say is a bug (in the Windows version) is the “dog gone” memory leak at termination. If you launch Puggle and exit (not just close the window - Puggle will tell you it’s already running if you try to start another instance) N times, you’re left with N instances in memory taking 90-100 MB each, which you have to remove with Task Manager.