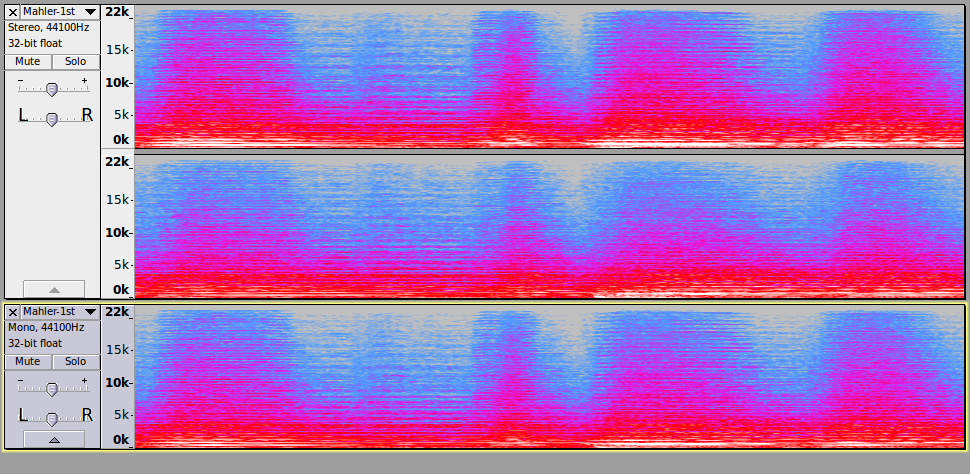
After combining two stereo channels to mono, I used noticing a reduced level of the upper part of the original audio spectrum. For instance, this occurs when using other audio editors as well.
Let us suppose the stereo file is of *.wav type. It seems, so I may be wrong, the process of combining is to take the average of every two samples having the same timing and saving it as one sample to form the new mono channel. Actually, the original file length (excluding the wav header) will be reduced to half.
Speaking logic, less samples implies less information. So, perhaps, this could explain the loss, to some extent, of the higher frequencies when using this intuitive algorithm.
In my free time, I will try, by writing a small exe program, to combine the two stereo tracks by interleaving their samples to form one mono track which will have the original length. But, in this case, the bit rate, in the header, should be doubled to preserve the original audio spectrum (besides specifying there is one channel only).
From what you presented here there is no doubt that the audio spectrum is indeed preserved.
The difference I mentioned earlier is based on comparing the ‘hearing’ of the mono track and its original stereo channels.
I am 69 and I have one active ear only. This is why I have needed lately listening to hi-fi mono instead of stereo.
Now, I wonder if the difference I used noticing (with hi-fi music) will disappear if I will restore the global 6 dB loss.
In my free time, I will try, by writing a small exe program, to combine the two stereo tracks by interleaving their samples to form one mono track
Somehow… I don’t think that’s valid because an amplitude difference between the channels becomes a “sudden” (high frequency) difference as you alternate between channels.
But, in this case, the bit rate, in the header,
The sample rate. WAV files are already interleaved so you can just change the sample rate & number of channels.
Would you please hear the two attached sounds?
“S_RoadToHell_ChrisRea1.wav” is selected from the original stereo channels
“M_RoadToHell_ChrisRea1.wav” is selected from the generated mono channel.
To my right ear in the least, the treble signal is not as clear in mono as it is in stereo.
In the stereo version, the sound has been processed in a way cause a very wide stereo spread, except for the bass frequencies which are essentially centre panned mono. Of course, in the mono version, the entire sound is centre panned mono. I think it’s that difference that you are hearing.
by steve » Fri Feb 01, 2019 1:14 pm
In the stereo version, the sound has been processed in a way cause a very wide stereo spread, except for the bass frequencies which are essentially centre panned mono. Of course, in the mono version, the entire sound is centre panned mono. I think it’s that difference that you are hearing.
Do you mean you didn’t hear the difference (using the right or left side of a headphone)?
On my side, I was expecting hearing all instrument’s sounds combined in one track and without noticeable loss.
And I agree with DVDdoug that reading the stereo interleaved samples as of one mono track is not a good idea, even if the two stereo tracks are not very different.
This led me to think about another algorithm
Let us suppose L1, L2, L3… Ln the stereo samples of the left track (wav), and R1, R2, R3… Rn of the right one.
We may generate the samples Mx for mono as:
I mean that the “frequency content” (the frequency spectrum) of the mono track, is almost identical to the frequency content of the stereo track. But in the stereo track, there is a wide stereo spread of the higher frequencies, but as that is a stereo effect, it is only present in the stereo version.
I expect what they have done is to apply a stereo delay effect to the high frequency sounds.
To hear that the frequency content is actually unchanged, split the stereo track into two mono tracks (see: Splitting and Joining Stereo Tracks - Audacity Manual), and then compare these two mono tracks with your “mixed to mono” track.
I’m not clear what the purpose of this is. If it is that you want a mono mix that sounds brighter than a simple mono mix, then you could just mix to mono, then apply the Equalization effect to make it sound brighter.
Note that if you do that, you may need to Normalize and then apply the Limiter effect so as to bring the volume up to match the original (the original has been highly compressed to make it sound as loud as possible )
This will preserve the original audio file length. But, as I hope, it will preserve its contents better.
Lately, I try implementing the algorithm (stereo to mono above) on the stereo sample “S_RoadToHell_ChrisRea1.wav”.
Due to the world’s sanctions against the people I was born among, the last genuine PC complier I was able to buy is the C compiler of the BorlandC 3.1 package.
Using this C compiler for DOS, a simple exe could be created to convert a stereo wav file to mono if the format of the original wav file is well known.
By using the “Free Hex Editor Neo”, I was able copying the raw file, as hex, to “Excel”.
I noticed there are two headers; at the beginning and at the end. So my first step is isolating them from the ‘audio’ data block and searching, as possible, about the meaning of ‘all’ their various parts (I already know some of them).
From the top header, one audio sample is 32 bits (4 bytes). But I wonder if its format is 2’s complement or float.
In Audacity, if you Export as “RAW”, then you get a file containing only the PCM audio data (same format as WAV, but without any headers).
“File > Export > Export Audio > Other uncompressed files”
See: Other uncompressed files Export Options - Audacity Manual
Thank you, Steve, for mentioning the “RAW” option; I used focusing on “WAV” instead.
So, I run Audacity (2.3.0). And I chose ‘Export Audio’ on the ‘Export Menu’. Then, I selected “Other uncompressed files” and "RAW (header-less) which give as ‘Encoding’ “VOX ADPCM”.
Saving as “RAW” format, as expected, worked for the mono file “M_RoadToHell_ChrisRea1.wav”, but not for “S_RoadToHell_ChrisRea1.wav”.
Don’t you agree with me?
Thank you.
Edit:
Sorry, I thought “VOX ADPCM” as ‘Encoding’ is the only choice. So even “S_RoadToHell_ChrisRea1.wav” could be saved without headers as 32-bit float.
So far, while analysing S_RoadToHell_ChrisRea2.wav, I noticed that the length of the top header is 80 bytes (excluding the first 8 bytes).
And the length of the bottom one is 308 (starting with “LIST”).
To simplify a bit my work, I tried removing the latter header and adjust the file length (byte_4 to byte_7) accordingly (decreased by 308). The resulted wav file “S_RoadToHell_ChrisRea2.wav” looks good for Audacity.
Now, I have to also search about the Audacity “fact Chunk” in the top header. Searching the words “fact”, “chunk” and “data” on the ‘html’ help files didn’t help in giving information concerning the fields after the 4-byte word “fact” (in the header).
I wonder if there are other Audacity sources to search this info.
I don’t think you need to manually fiddle with WAV headers. You could just export as RAW PCM, apply your program to the data producing a new RAW (data only) PCM file, then use “Import RAW” to get the data back into Audacity: https://manual.audacityteam.org/man/file_menu_import.html
Note that with “Import RAW” you will probably have to enter the format details manually. In the absence of file headers, it is often not possible for Audacity to guess the format.
32-bit float is very convenient for programming, as it’s just one floating point number per audio sample. It’s also very good for audio processing because it supports extremely high sound quality with a huge amount of “headroom”.
The only really important downside is that sound cards don’t directly support 32-bit float, so it has to be down-sampled to 8, 16 or 24 bit (integer) before it can be played. 16-bit is the most widely supported (as used on audio CDs).
I don’t see how that preserves the original length.
Say you have a stereo track, with a sample rate of 44100 Hz, and a length of 1 second:
There will be 44100 samples in each channel.
For the final (nth) sample, n=44100, 2n=88200
so the mix has 88200 samples, which at a sample rate of 44100 = 2 seconds.
The mix ‘could’ have the same length if you also changed the sample rate to 88200 Hz, but that’s not what you said.
If so, then that would be effectively the same as a normal mix, with intermediate samples placed between each sample of the mix, where the nth intermediate sample is (Ln+1 + Rn) / 2
If that’s what you mean, then the effect would introduce high frequency noise, due to the offset between the intermediate samples and the interpolated value of the “true mix” samples.
So L(1):L(n) and R(1):R(n) are converted to M(1):M(2n). In other words, no change in RAW length. Obviously, the new samples should be read as one channel and at twice the original speed/rate.
About introducing noise, I assumed that the conventional algorithm is simply:
M(x) = ( L(x) + R(x) ) / 2
So please let me know if this is not the case.
On my side I will also try comparing the 32-bit floats of the mono and stereo files to have an idea on how the conversion was done and reduced the stereo data size to half (for mono).
I learn from this that if I export a wav file, that uses 32-bit float, using the 24-bit encoding, there will be no audible loss of any sort if played by the sound card of my lap.