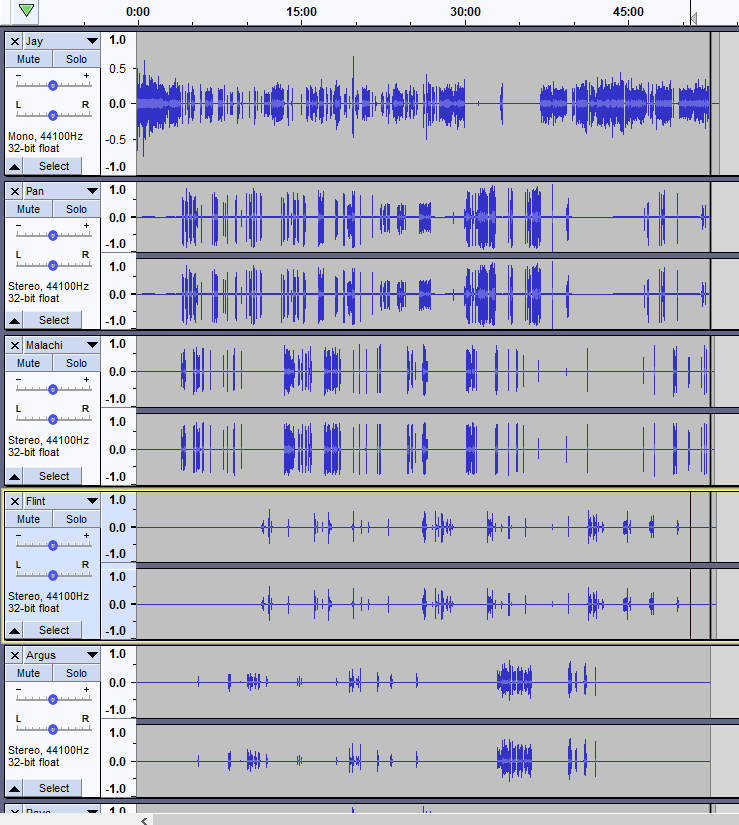
I think I recognize the recommendation that multi-point podcast recordings should be done at each location instead of trying to do it after transmission. It gives you “clean” voice tracks assuming everyone did a reasonable job of recording.
It does give you one oddball problem that live recording doesn’t. The start times will be wonky.
Did you manage a click, clap, or other sync signal or sound?
==============
If someone had a gun and forced me to mix this:
– Make two independent protection copies of everything.
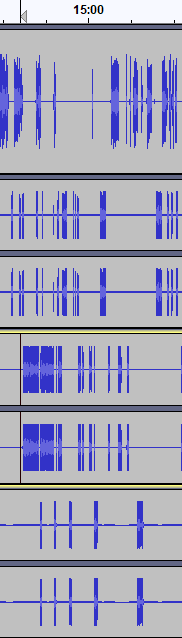
– I see from the illustration that these are all “really” mono tracks. Mix everybody down to mono. Much easier to perceive single mono tracks than a screen full of redundant information.
– Find a terrifically high quality speaker or headphone system. Nobody is going to mix this on laptop speakers.
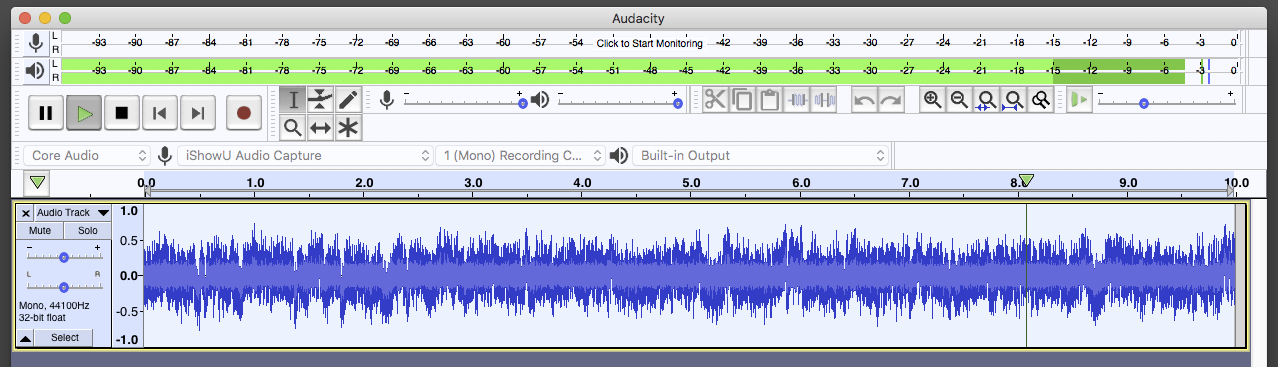
– Play the show and watch the bouncing sound meter. I Expand the meter display so it goes across the whole Audacity window and increase the meter range to 96dB. That will measure the total show signal no matter what the blue waves are doing.
– Critically listen to the presentation and play it. This might be the time to Time Shift each actor so the show times line up.
– As each actor speaks listen and judge the loudness with one eye on the sound meter. Volumes can be adjusted up or down with the (-) -----0----- (+) adjuster to the left of the track. Note this doesn’t change the blue waves, only the playback volume. Listen through multiple passes until the overall volume is pleasant to listen to and the sound meter never hits maximum.
This will be interesting if someone cracks a good joke and everybody in the known universe laughs at the same time. Those may have to be individually adjusted.
– I’m unsure what happens to an Audacity Project after these adjustments, but Save a Lossless Project (the most stable kind) and Export a WAV (Microsoft) 16-bit sound file. The WAV is your Edit Master. We should be crystal clear, this master sounds perfect and doesn’t overload.
– Make two independent copies of the Edit Master WAV. A word about that. Be able to point to two different places for the two copies. Internal drive is one. Thumb drives work. External hard drives work and cloud storage works. Two folders on your internal drive does not work.
– Open up the WAV in Audacity. Apply the first step in Audiobook Mastering: Effect > Filter Curve: Low Rolloff for Speech > OK.
– Adjust to the loudness specification (LUFS, etc) of your choice.
– Export whatever format you wish (probably MP3). Note you can’t edit an MP3 without causing sound damage, so don’t lose that Edit Master WAV.
It’s not at all unusual for editing to take five or more times the length of the show—and that’s for an experienced editor.
I don’t know of a one-button-push way to do this.
Good luck.
Koz