If this is the wrong place for this request or you are unwilling to help please ignore this post. Ty.
Hi there. I have been investigating those weird subliminal channels on youtube for a while (by following their interactions in comments, connections with businesses, etc) and have managed to get quite a lot of information.
However, I have hit a snag. I need to remove hidden text from one of these files, but I have no idea how to do it.
I really want to see what is in these so I can finally prove that the authors are fraudulent.
If you could tell me how I could do it, or even better show me an example of one that has been decoded, I would be very grateful. Thank you.
There are several subliminal methods and some are not reversible. Probably most aren’t reversable. So you’d have to know the technique and then you can investigate how to reverse it.
My favorite* technique is to mask (drowning-out) the subliminal sound my mixing it with a louder sound. I like that method precisely because you can invert the louder masking-sound, mix it with the subliminal mix to subtract it out, leaving only the subliminal which you can then amplify if necessary. And that proves that the subliminal hidden information actually exists with this technique. (It doesn’t prove that subliminals “work”.)
But, you have to be in control of the whole process so you can keep that exact-original louder masking sound so you can make a perfect inverted copy so it will subtract perfectly. The whole process has to be done under “laboratory conditions”.
Or an even simpler method is to just lower the volume to the point just-below where you can’t hear it, or the point to where you can barely hear it without being able to understand what’s being said.
Note that lossy compression like MP3, or whatever YouTube is using, works by trying to throw-away little details that you can’t hear so the subliminal information probably won’t be preserved.
I need to remove hidden text from one of these files,
[u]Text[/u]? Written words? Usually, the only text in an audio file is metadata and that can be removed with a metadata editor (I use MP3tag, which works on most formats not just MP3).
If there is non-standard text information in the file Audacity will ignore it (or Audacity will fail to open the file) so simply opening in Audacity and re-exporting it should remove it.
\
I don’t really have a favorite method, I’m a total skeptic… If you can’t hear it you can’t hear it and it never gets into your memory.
Just as an example not involving subliminals - If you weren’t paying attention and you didn’t notice what color shoes your wife or mother was wearing this morning, that information is not in your brain and you can NEVER “remember” it.
Sorry, by text I just meant spoken words. A failure of my vocabulary.
Thank you for the information!!!
I have a .wav version of one of the files.
Do you think that if I could post it somewhere you could perhaps figure out what was done to it?
It is just under 3 mins long and just under 8mb, iirc.
I have a .wav version of one of the files.
Do you think that if I could post it somewhere you could perhaps figure out what was done to it?
Not me… Maybe someone else could help but most discussions I’ve seen here on the forum are just questions by subliminal beginners… I don’t think there are many subliminal experts here, if any.
I don’t understand most of the methods, and I don’t really care! I’m only interested in stuff I can hear! Some methods seem like they scramble/corrupt the audio or use some modulation technique to the point that it’s no-longer sound. But that’s sort-of the whole idea… You’re not supposed to consciously hear or understand the message.
And I can’t test for my “favorite technique” because I don’t have the unmolested (and unmixed) original. And I forgot to mention. The mix has to be unmolested too. It has to be a “clean mix” of the two files with no editing or processing… not even a volume change.
I can understand your disinterest, for sure.
I am not even sure why I myself take such interest in digging through this stuff. Surely there are better things to spend one’s time on, right? And yet … here I am lol.
Thanks for the help/information
A lot of commonly seen “Silent Subliminals” use either “amplitude modulation” (“AM”) or (much less commonly) “frequency modulation” (“FM”) to encode the “message” in a very high frequency range (often around 16 - 17000 Hz). Although people that have excellent hearing may hear the encoded sound as a high pitched whistle, most people, and particularly adults, will not hear the sound at all because it is so high pitched.
The well known (amongst silent subliminal enthusiasts) “Lowerey” method (patented by O.M. Lowerey) uses amplitude modulation, which is akin to how AM radio works, except that the carrier frequency is a high frequency audio signal (typically around 16- 17 kHz) rather than radio frequency. Despite claims to the contrary, Lowerey O.M. Lowerey’s work was not in the slightest bit “scientific” as it completely lacked any testable hypothesis concerning a mechanism that would allow a person to “subconsciously hear” sounds above their hearing range, let alone how they could subconsciously decode an amplitude modulated signal. Nevertheless, it is still possible to detect and decode audio frequency AM encoded messages, if we know what to look for and have the technology (such as “Audacity”) to decode it.
The way to create audio frequency AM modulation is described in this post: Silent Subliminals [solved?]
Basically, there are two steps:
Filter the “message” audio so that it has a frequency range that is no more than the range between “half the sample rate” and the carrier frequency.
Example, if the track sample rate is 44100 Hz, then half the sample rate (also known as the “Nyquist Frequency”) is 22050 Hz. If the carrier wave has a frequency of 17000 Hz (17 kHz), then the range between the carrier frequency and the Nyquist frequency is:
22050 - 17000 = 5050
So the “message” audio must be filtered to remove frequencies above 5050 Hz.
Modulate (multiply) the filtered message by a sine wave at the carrier frequency.
This does the actual “modulation”.
An optional third step is to filter out the carrier frequency and / or frequencies below the carrier frequency.
The modulated signal is essentially symmetrical around the carrier frequency, so by removing the lower half (which is much easier to hear because it is not such high frequencies) the modulated signal can be made less audible.
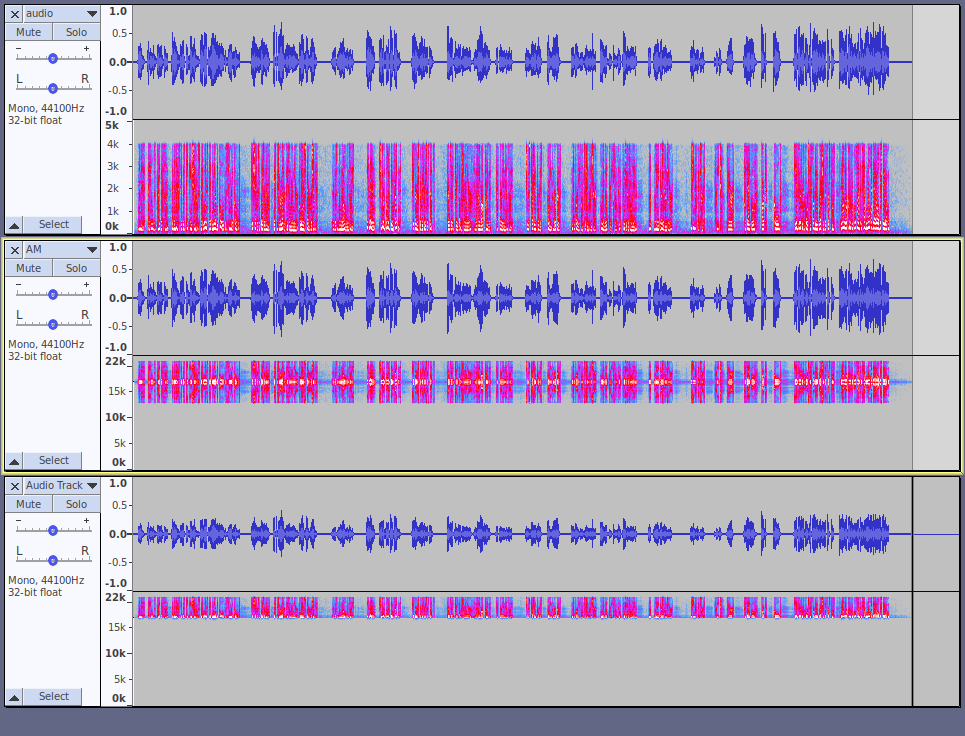
The three tracks shown below illustrate what each step looks like as both waveforms and spectrograms (frequency plots).
The top track shows a voice recording that has been filtered with a very steep filter at 4000 Hz.
The middle track shows the audio after it has been modulated by a 17000 Hz carrier. Note that the lower half below 17000 Hz is a mirror reflection of the half above 17000 Hz.
The third track is after the track has been filtered again to remove the carrier and all lower frequencies.
If an audio file contains an AM encoded message, you will see a high frequency waveform within the spectrogram that looks similar to either the second of third tracks above.
Once detected, it can be decoded back to the original audio by “de-modulation”. For AM, this is quite easy (with the appropriate tools, such as Audacity) and is similar to encoding. There are again 2 steps:
Multiply the AM signal by the carrier frequency.
This will create two new waveforms with frequencies in the ranges as shown below. The lower range is the actual audio, and the upper range is a kind of reflection.
Filter out the reflection with a very steep low-pass filter.
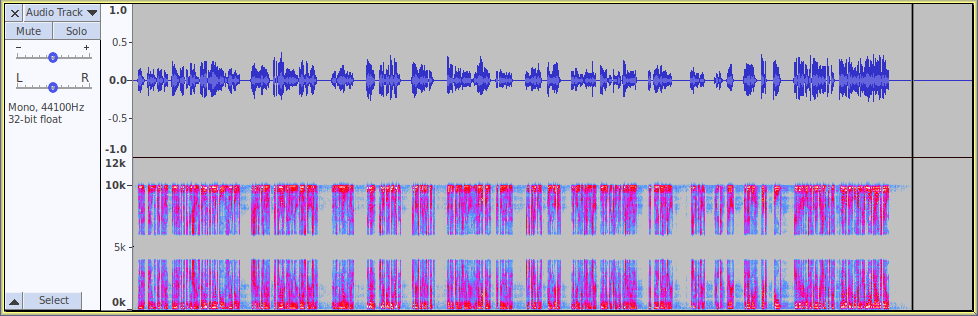
This final image shows the AM signal from the first test after it has been demodulated (but not filtered).
Notice there are two frequency bands: 0 to 4000 Hz (the same range as the original audio), and around 6000 to 10000 Hz (the “reflection”).
If the final low-pass filter is not applied, the result will still be audible, but it will sound a bit weird because of the reflection.
so…
the steps to determine if there is a “message”, encoded according to O.M. Lowerey’s patented method, and to hear what the “message” is:
Look for an AM signal.
Guess as closely as possible what the carrier frequency is (usually above 15000 Hz and below 18000 Hz)
Multiply the track by the carrier frequency (see below)
Optional, filter out the “reflection”
To “multiply” the waveform by a sine wave of a specific frequency, use the Nyquist Prompt effect, and enter code similar to this:
(mult *track* (hzosc 17000))
Change the number “17000” if necessary to match the carrier frequency that you determined from the waveform.
I hope that you find the above interesting and useful, but so as not to mislead you or others, I feel that I should include a disclaimer:
Disclaimer:
While I find the mechanics of audio frequency AM modulation / demodulation interesting, I find the idea that people can somehow “magically” capture sounds that are beyond their hearing range and subconsciously apply the necessary demodulation techniques (as described above) to decode the message, to be rather far fetched. Although in more recent times, hypotheses have been proposed to explain how it could occur, verifiable experimental evidence to support these new hypotheses is lacking. (I’m also being very loose with the term “hypotheses”, as in a scientific context a hypothesis is based on empirical evidence rather than being devised to explain a belief.)
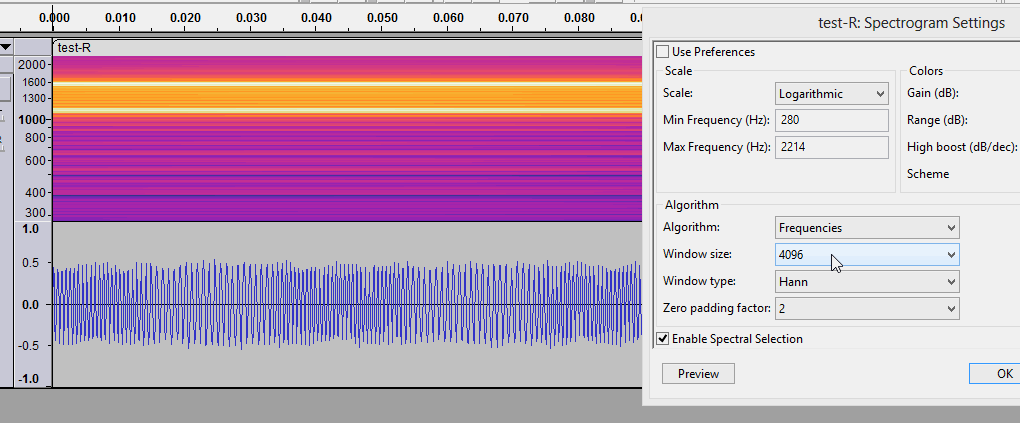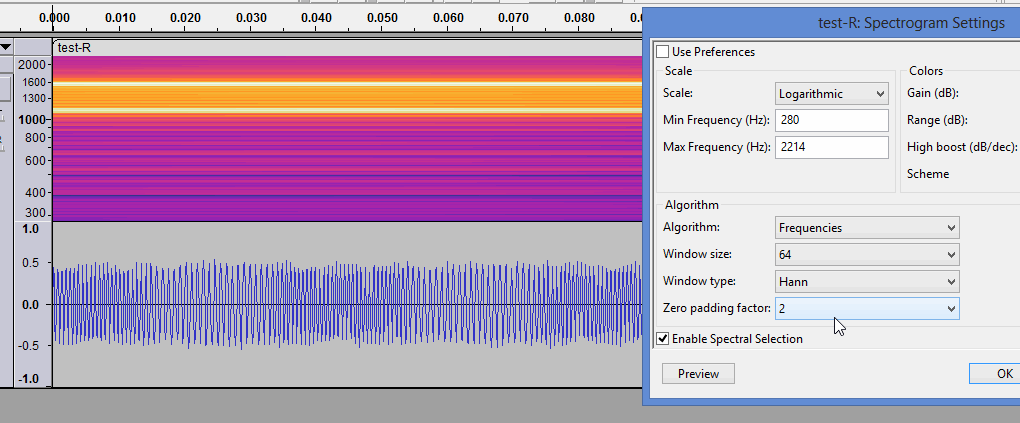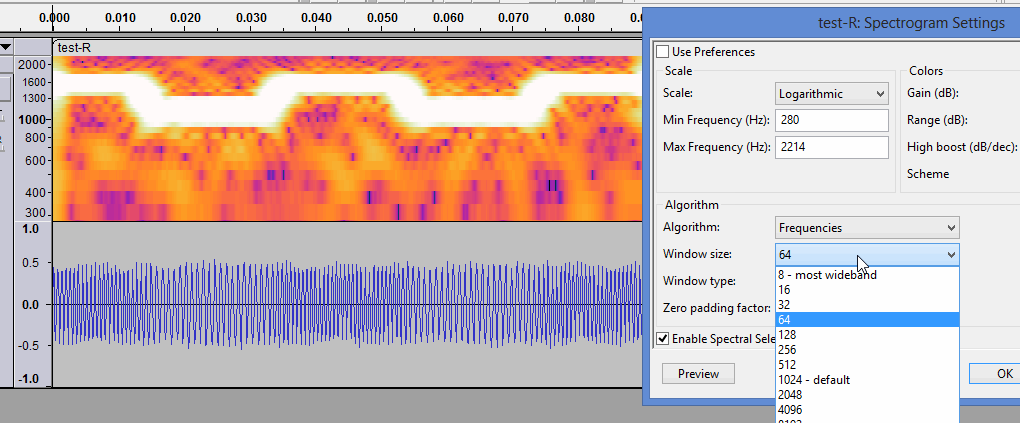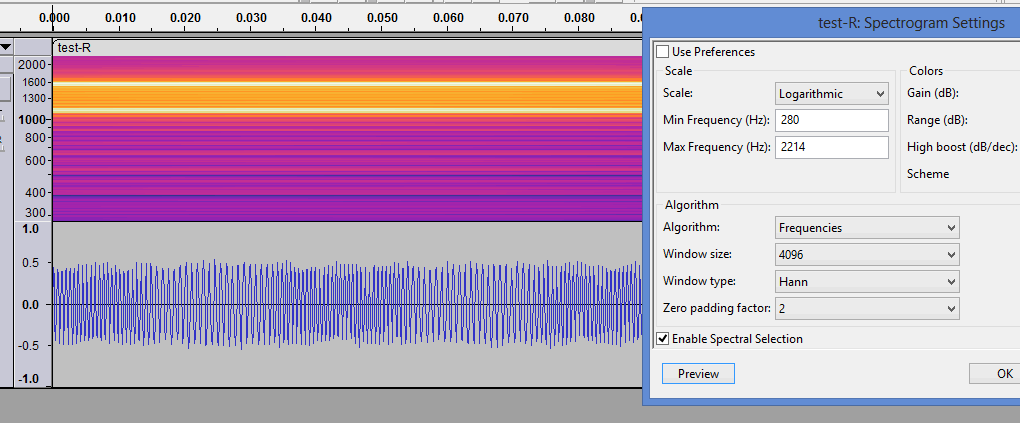
@steve - my apologies for bringing up an old topic however I am searching for a solution to a similar problem - I have the following waveform and spectrogram as shown below. This is one of four channels then when combined produce speech or at least I am fairly certain they do. I have two very obvious loud signals in there. Would you consider this to be a similar situation to the one you described above? Thanks for the very informative and well laid out post it definitely gave me some new information.
Ah sorry Trebor! I am relatively new to all this having only learned audacity over the past few weeks. What a fun and amazing program! However based on the information above I think I have figured it out. When I put it into 8-bit stereo the line appeared in a singular fashion and at 14,700 precisely when I upped the resolution to full. Which is 22050 divided by three. So this was in fact the solution I have been searching for. Working on testing it now. Thanks for the reply!