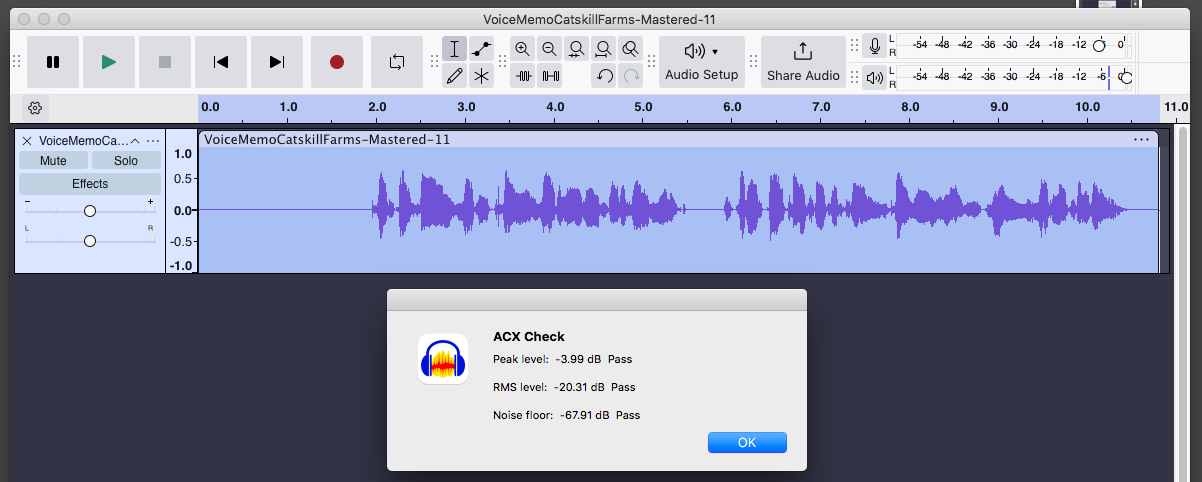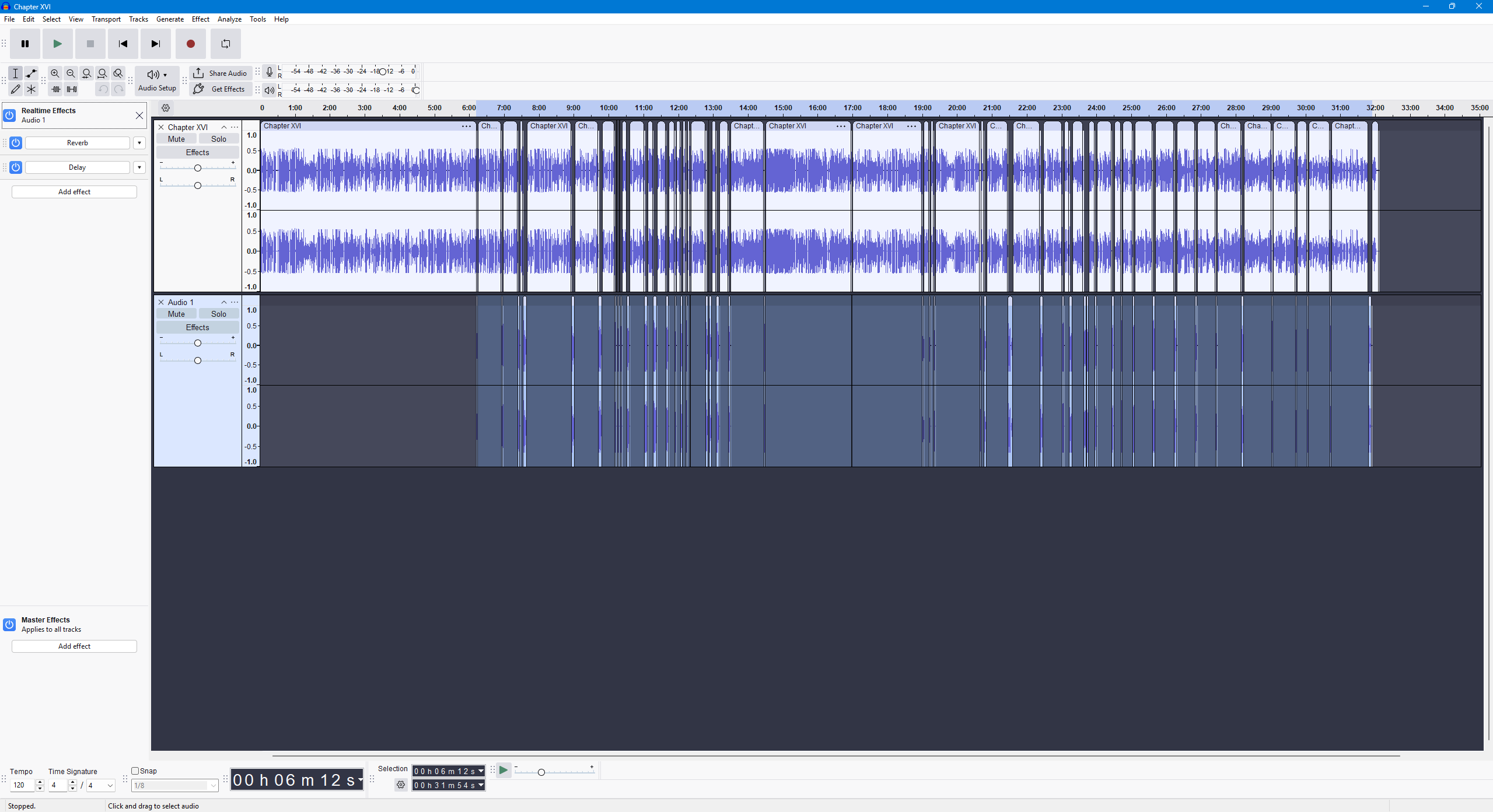
I’m working on an audiobook, where the bottom track is a char who speaks in telepathy. I added the effects on the right to add an effect akin to mental speaking. Currently using acx check, the top one passes. The bottom track also passes, but together ACX shows that the peaks are at 0 and need to be adjusted.
I can’t seem to shift peaks with amplification without messing up RMS (too loud), using a limiter messes up both, and if peaks passes, rms fails and vice versa. I’ve gone through each number from -3–(-4.9) on peaks, and from -18-(-23) on RMS and neither are playing well.
It SOUNDS fine, no issues with peaking, silence, buzzing, or the like, but the automatic checking doesn’t like the complete file. I’m at a loss for what to do because this plagues all chapters with this character. I don’t wanna reverse the effect, as it’s integral to the story, but DAMN is this frustrating when I’m so close to publishing.
I even re-recorded each line in the bottom track, ran the macro on each line to make sure all of them passed acx check, and with both tracks passing (below) it still has 0db peaks when uploading it to ACXlab (document attached). I’m losing my mind and am in the final stages of editing and this plagues at least 12 chapters.
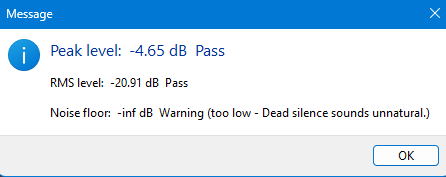
ACXLAB output for whole file

Track 1
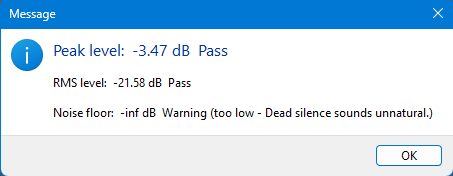
Track 2
Macro Settings

I could use some help.