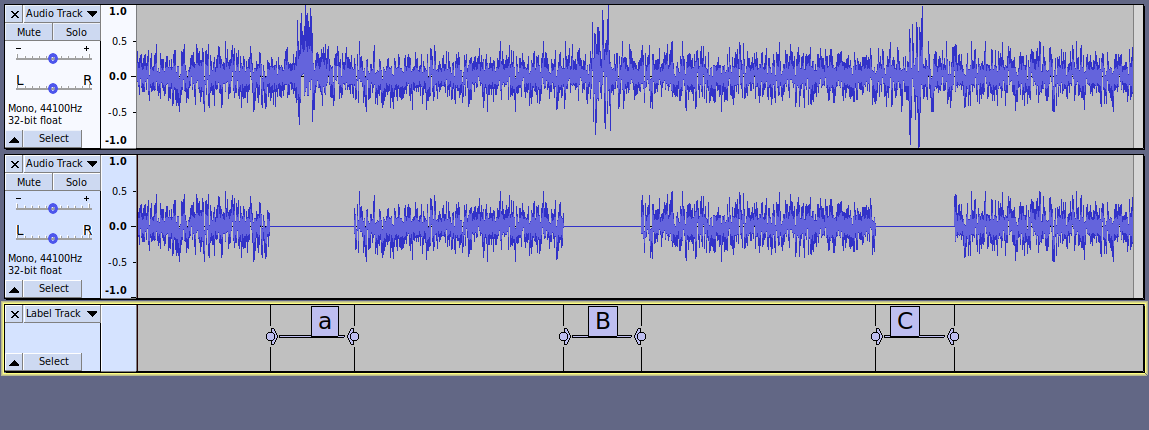
Despite some research and leveraging on codes for similar tasks, I’m still not able to solve the following.
Given:
- a sound selection;
- a numerical threshold (e.g. 0.9); and
- a (time-based) parameter named ‘radius’,
the code should: - map selection samples exceeding the threshold;
- at each of those mapped points, should replace the interval (centered at the mapped point, length = 2*radius) in the original selection by a silenced interval of same length.
In other words, outcome should be:
A sound of same length as the input one, with silenced intervals replacing the corresponding intervals in the original sound selection.
Each interval being centered at an offending sampled point (i.e. above the threshold), having a length of twice the ‘radius’.
I provide the latest (failed) attempt:
; set threshold
(setq threshold 0.9)
; silence radius around a given offender (in seconds)
(setq radius 0.005)
; duration of sound signal
(setq duration (get-duration 1))
; silence interval same length as original
(setf silenced (abs-env (s-rest duration)))
; initialize "output" as selected sound
(setf output s)
;start loop
(do
(
;initialize and increment variables
(count 0 (+ count 1))
(timepoint 0 (/ count *sound-srate*))
(lbound 0 (- timepoint radius))
(ubound 0 (+ timepoint radius))
(val (snd-fetch s)(snd-fetch s))
)
(
;loop until run out of samples
(not val output)
)
;Loop body. Run code if offender. (This is where code will probably get most of changes in order to work as intended.)
(if (> (abs val) threshold)
(abs-env
(setf output
(sim (
(at-abs 0 (cue (extract-abs 0 lbound output)))
(at-abs lbound (cue (extract-abs lbound ubound silenced)))
(at-abs ubound (cue (extract-abs ubound duration output)))
)
)
)
)
)
)
I’ve tried other things such as SEQ, MULT… Failure probably stems from inadequate use of behaviours, sounds, samples etc. Still could not get my head around all those different concepts and their corresponding treatments.
Also, I’m sure there’s a much better way to approach it other than looping; any code that would get the job done would be much appreciated.
Thanks for any help in advance.