(UPDATE 2018-11-04: A consolidated posting of the effects of all the interchange on this post can be found in this post Voice improvement - consolidated effects.)
I know this is a tough one, might be impossible. Looking for the best that can be done.
There are 9 hours of this, with thousands of edits onto video, so the best answer - rerecording it and making it better - would generate hundreds of hours and is impractical.
I have done what I know with Audacity, in particular using Ozone Imager as suggested, and it is a lot better. However, the one comment I still get is that it is not “engaging” enough. Any ideas to help make it a bit less boring, more exciting, more “engaging”?
I’m nitpicking now …
The breath sounds give-away that noise-reduction has been used.
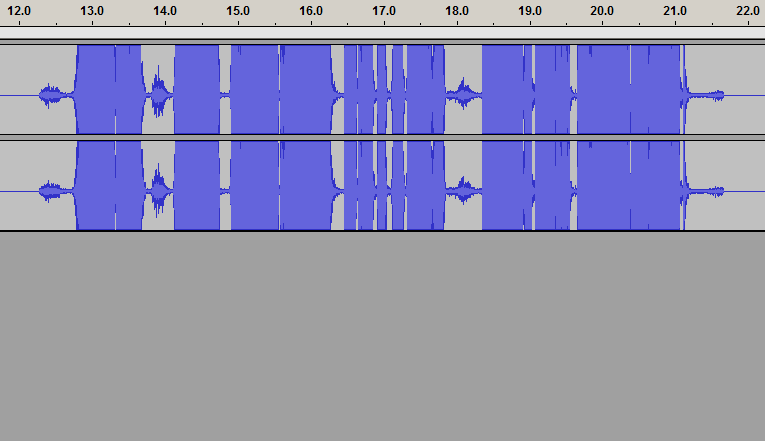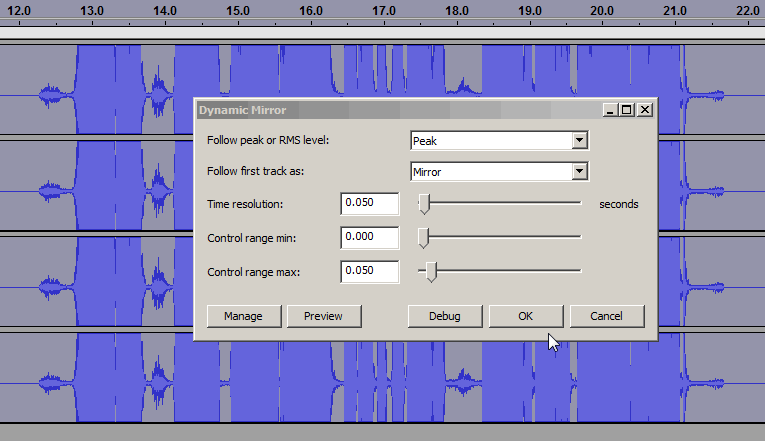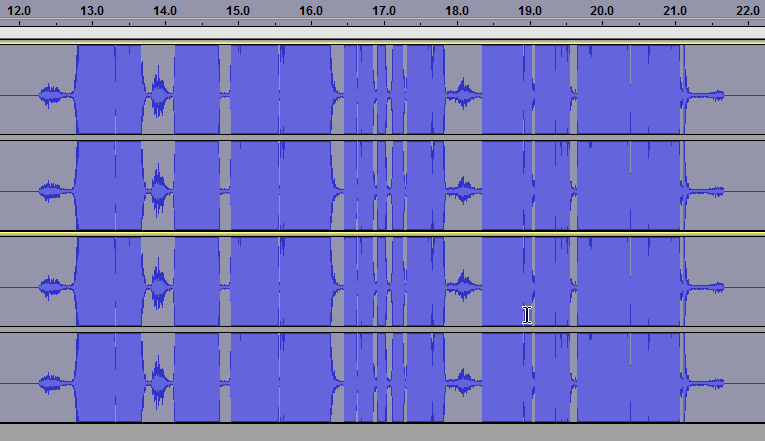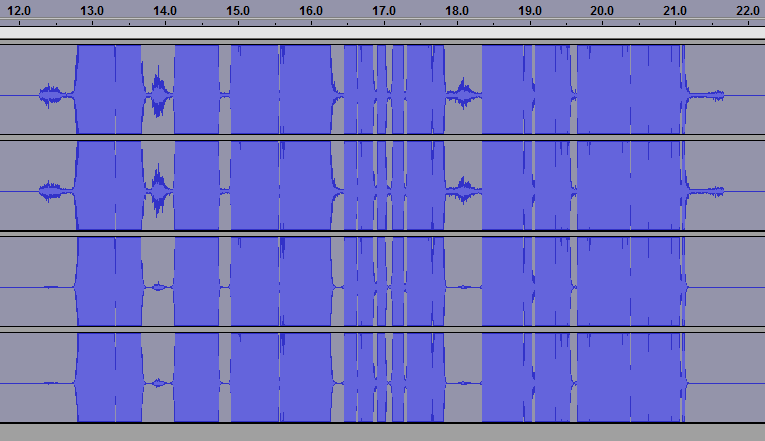
The low-level breaths can be attenuated* using Steve’s dynamic-mirror plugin as an expander …
[* usually best not to remove breaths completely, as their total absence is unnatural & makes speech jarring ].
My opinion is a bit more basic. You sound like you’re talking into a wine glass. Did you do extensive noise reduction? Conference Call/Cellphone Voice.
The next thing I did was speed it up 8% and took some of the air out of the speech pattern.
And maybe that’s not even enough. That “every word is a gem” thing is deadly in instructional work.
Behold SciShow. Hank is done with the show and home eating dinner by the time you finish the first chapter.
Wow, that’s extreme. I had to stop listening before 2 minutes because it was too annoying, particularly the lack of spaces between sentences.
Nevertheless, I think you make a valid point - a compromise between the two would be nice, but too late for this project.
On the other hand, pace is not everything - David Attenborough is well known for making highly engaging documentaries, but narrates at a very steady (slow) pace. In my opinion, it is the way that his genuine passion for the subject shines through that makes his narration so good. Being a really good narrator is not an easy skill - it takes a lot of practice. Theatrical “acting” experience can help.
David Attenborough doesn’t sound like he’s talking to a kid (having an orchestra back there helps). I didn’t write that in the opinion, but that’s part of the “every word a gem” thing. I wish there was an easy way to shorten those dragged out emphasis words.
Hank Green.
I can’t watch most instructional videos. They’re all running at 33-1/3 in a 78 world. Am I dating myself yet? I have an Edison Cylinder (but I didn’t buy it new).
I found a new one. Chelsea from The Financial Diet. She’s a New Yorker, but still. Tight, rapid, clear presenting and fun (in my opinion) to listen to even though I wasn’t searching for financial advice. Some might say “Engaging.”
In a relatively recent series of videos, she did partnership videos with (drum roll) Hank Green.
9 Hours
I started paying attention. Almost none of the instructional stuff I like to watch is over 20 minutes per episode. If they need to go longer, it’s two or more episodes. That means they Must cover material concisely and clearly. I didn’t write it down, but an “adventure” series I like introduces a new idea or direction about every XX seconds. Occasionally, for theatrical shock, they violate that rule and drag something out. You don’t realize the inertia you built up until you hit one of those segments.
Then there’s the “Editor” thing. Very few people can imagine, write, announce, edit and publish successful works by themselves. It’s too easy to go off the rails and there’s nobody to bring them back.
As a psycho-acoustic experiment, listen to the speeded-up version a couple of times and then go back and listen to the original.
To bring this back to the top, I don’t think any of those problems is going to be solved by an effect or filter. It might be solved by leaving the video the way it is and re-record the voice parts. The reference here is the first time audiobook reader who re-records the first few chapters based on the experience and skill they got from reading the rest of the book. Depending on picture/sound integration, that may not be possible.
Missed one. Remember the original complaint? If you need tons of Noise Reduction, find out why and fix it. Record in a better environment or create a tiny quiet environment to record in.
Most microphones can do a respectable job in a quiet, echo-free room, particularly if the show is not a theatrical presentation.
I saw an extended “LONG VERSION!” (warning) technical Q & A video.
It’s 16 minutes.
Given that could be Google or YouTube trying to “help me,” but still. The video is broken up into useful information as well as pointers and references rather than trying to cover everything in one long video.
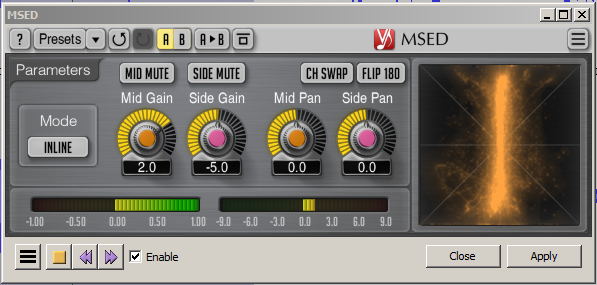
I might just reapply the Ozone Imager. I had used the “all 3’s” approach, width 33, amount 3.3. To reduce the “too much” that you hear, should I reduce the width or amount or both, and if so any suggestions?
The only noise reduction I did was the usual select some quiet time, get the profile, and apply to remove background hum and hiss. I don’t recall hearing any difference in the main audio after that. As above, it might be that too much Ozone Imager pseudo-stereo is the problem. It sounds much better than the flat original, to me like “I’m in a room”, however based on Trebor’s response to the above I will try scaling it back a bit.
The speed up does sound a lot better. I had previously actually sped it up 16%, so you can imagine how slow it was originally. This was based on experience speaking to live classes, holding their eyes, adding emphasis with gestures, making sure they get this useful information. In live classes I get great reviews, honestly! But I think another 8% is appropriate for this online approach. Did you use “Change Tempo” effect to avoid pitch change? And should I worry about any negative effects from too much speed up?
When you say “took some air out of the speech pattern”, was that the speed up you mentioned, or did you apply a different effect?
All: these are 200 odd videos, almost all just a few minutes long, so divided into bite size chunks. So it has that going for it anyway.
Stick with all the threes on Ozone imager, but mix-in less dual-mono (Ozone) with the mono original …
Having the level of the dual-mono (Ozone) track about 12dB lower than the original mono track is about right for a subtle believable simulation of a stereo-mic recording.
Aha, I had missed mixing in the mono track in your original suggestion, now I understand, thanks. After I apply Ozone Imager to the stereo track, can I just select it and the mono track, and then use “Export Selected Audio”? Or do I need to use the Audacity mix functions first?
These are things I am particularly unskilled at, and might just not have the experienced “ear” to play with these settings to find the best ones. Are the settings in your post second from the top above Fri Oct 19, 2018 4:35 pm reasonable settings?
After adjusting the level of the Ozone pseudo-stereo track to taste, (about 12dB quieter than the mono track),
I used mix and render to combine it with the mono track, (not necessary to export it).
Those de-esser settings are extreme, rather than “reasonable” : it will sound muffled after applying them,
the assumption being that a strong treble-boost will be applied afterwards to add presence.
Ok. Since I have so many of these to do, I’m looking to save space and time. If I just select both the Ozone pseudo-stereo track and the mono track, and select Export Selected Audio, will the resulting WAV file be the same as if I did mix and render and then exported that track?
So if I’m going to do a treble-boost afterwards, should I use the de-esser settings from your first post from Fri Oct 19, 2018 4:35, and then use the settings from the Marvel GEQ pic from the same post?
Got it. I still want to apply the change pitch -5%, as it greatly improves my sound. Would the sequence be: de-esser, change pitch, boost presence with EQ?
If so, still same settings for de-esser and boost presence with EQ?
If you’re applying my suggested settings without tweaking them to what sounds good to you,
then the order they are applied doesn’t matter.
Personally I would change pitch, then de-ess, then boost presence with EQ,
as changing pitch will alter the optimum de-sser settings.
If the WAV I attached to my previous post is you pitch-shifted by -5% ,
then you won’t need* to change any suggested settings.
[ * they’re not written in stone though ].