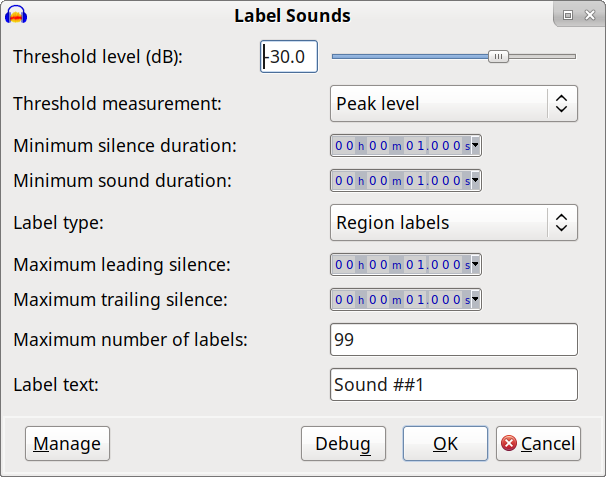
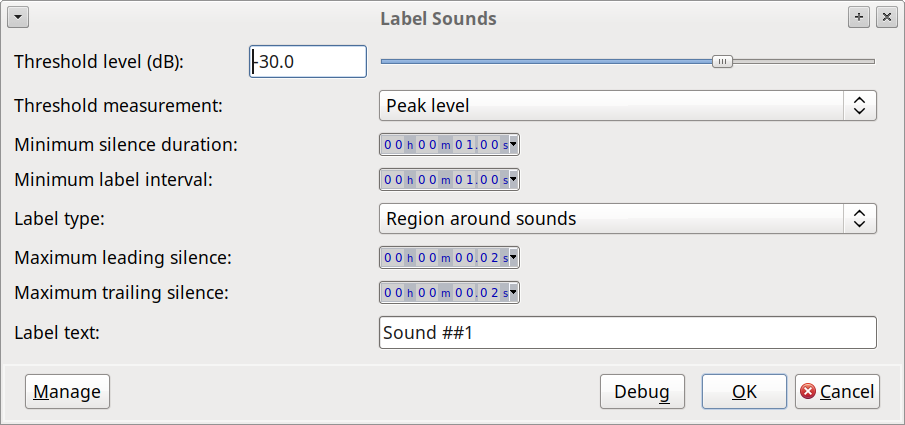
In Audacity 2.4.0 (due to be released next month), the “Silence Finder” has been updated, but functionally remains almost unchanged from previous versions. The only differences are:
Bug fix: The level for stereo tracks is now measured correctly
The “Treat audio below this level as silence (dB)” control now has a range of -100 dB to 0 dB (default -30dB) whereas the old version had a range of 0 to 100 (default 26) with units of “-dB”
The “Debug” button has been removed (this is a release version).
Square brackets in the GUI have been replaced by parentheses (consistent with other effects).
Although it would have been possible to merge the “Silence Finder” and “Sound Finder” into one effect, I resisted doing that for reasons that Gale Andrews frequently cited:
“Silence Finder” is a relatively simple effect, suitable for use by even the most novice users.
There’s a lot of old documentation that refers to using Silence Finder.
Given that the “simple” Silence Finder has been retained, I think it would be good to add a bit more functionality to “Sound Finder” as a more “advanced” option. It is too late to change Sound Finder in Audacity 2.4.0, but this delay provides an opportunity to fully test, and tweak if necessary, an updated effect for a future Audacity release. To this end, I propose…
Label Sounds…
The name, as recommended by Apple’s ‘Human Interface Guidelines’, uses the action verb “label”, and is descriptive of what the effect does - it labels sounds.
The interface:
Controls:
Threshold level (dB): [-100 to 0 dB] (default -30)
When audio is below this level, it is considered to be ‘silence’.
Peak level: The threshold level is measured as the peak level
Average level: The threshold is measured as the absolute average level for each 100 ms. This setting may help
avoid labelling clicks in vinyl recording. Note that the average level will usually be lower than the peak level.
RMS level: The threshold is measured as RMS level. Like the ‘Average level’ measurement, this is less likely to
label clicks. RMS level may be measured with the ‘Measure RMS’ or ‘Contrast’ effects.
Minimum silence duration: [0.01 seconds to 1 hour] (default 1 second)
When ‘silence’ of this duration (or longer)
is found, preceding sound and following sound are considered to be separate sounds, provided that the previous
sound is at least the ‘Minimum sound duration’.
Minimum sound duration: [0.01 seconds to 10 hours] (default 1 second)
If a sound less than this length is interrupted
by silence, the silence will be ignored. This means that labels will be at intervals of this length or more, other than
the final label (which may be shorter).
Label type: [Point labels | Region labels] (default: Region labels)
Sounds are labelled either with a point label before the sound, or a region label around the sound.
Maximum leading silence: [0 seconds or more] (default: 1 second)
A point label, or the start of a region label will be placed before the start of a sound by this amount, if there is room to do so. Labels will not be placed before time=0, and will not overlap previous sounds.
Maximum trailing silence: [0 seconds or more] (default 1 second)
This setting is used by region labels only. The end of a region label will be placed this distance after the end of a sound, provided that there is room to do so before the next sound.
Maximum number of labels: [0 to 10000] (default 99)
The maximum number of labels that will be produced. Note that the maximum number of tracks for a normal audio CD is 99.
Label text: [text] (default “Sound ##1”)
This is the text that will be entered in each label.
The ‘#’ symbol is a special ‘placeholder’ character for adding a counter.
The number of successive ‘#’ symbols determines the number of digits and if followed by an integer number, the starting number is defined.
Example: ###3 will add a three digit counter that counts up: 003, 004, 005… for consecutive labels.
A counter may be placed before, after or withing the label text, but only one counter may be used in a label.
Precision:
The amplitude measurements are made at intervals of 0.01 seconds, thus the label placement may be up to 0.01 seconds before / after a sound.
Tips:
If the ‘Threshold’ is set too low then ‘silences’ may be above the Threshold level, causing the ‘silence’ to be seen as a ‘sound’.
If the ‘Threshold’ is set too high, the beginning or end of sounds may be missed.
If ‘Minimum silence duration’ is too short, there may be more labels than intended due to short gaps being seen as ‘silence’.
If ‘Minimum silence duration’ is too long, gaps between songs may not be seen.
For vinyl recordings, ‘Average’ or ‘RMS’ measurement is recommended so as to reduce the chance of crackles registering as ‘sounds’.
Assuming that what you have posted will eventually become the “documentation”…
“peak level will usually be lower than the peak level” makes no sense to me.
I think that you misspelled “Precision”.
Throughout there are superfluous commas (according to Connie):
“If the ‘Threshold’ is set too low, then ‘silences’ may be above the Threshold level, causing the ‘silence’ to be seen as a ‘sound’.”
If the ‘Threshold’ is set too low ‘silences’ may be above the Threshold level causing the ‘silence’ to be seen as a ‘sound’.
Note also that Connie says that the “American” standard would probably suggest:
“then ‘silences’ may”
then “silences” may
Sorry, though I like the GUI, I have not yet tried the effect .
Thanks for the comments Edgar. I’ve made some corrections to the text. Of course official documentation will be proof read before the manual is released - clearly something I didn’t bother doing in a forum post
I have used the Label Sounds plug-in (new version) many times and really like it.
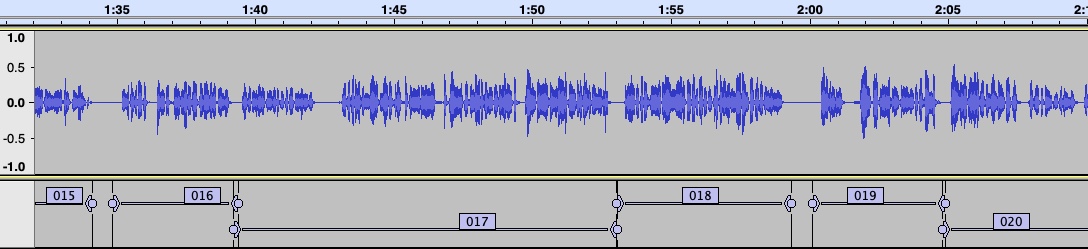
The only thing I don’t like is that it lacks a “Maximum sound duration” setting. For that reason, I keep finding sounds that are longer than I want. For example, if I could set the maximum sound duration at 10s, the 13s sound labeled “017” in the example below could be avoided.
I’ve tried playing around with all the other settings (adjusting threshold, minimum sound duration have been the most useful) with different files and keep running into the same problem. Is there a way around this I’m not seeing? I’ve also tried using Sound Finder, but of course it has even fewer settings.
Why did it not detect a “silence” between 1:42 and 1:43? Was it because the silence was too short, or not silent enough?
The problem with having a “maximum sound duration” is: “What should happen if there is no silence within the specified maximum?”
For example, if “Maximum sound duration” is 10 seconds, and there is 11 seconds of continuous sound, what should happen? I don’t see how a plug-in can predict what a user might want in this case, so my current thinking is that it’s better to leave it to the user to decide what to do. In your example, I guess that you would delete label 017 and replace it with two labels (017a and 017b) with the split around 1:42.5.
I can appreciate the difficulty you mention, but I still think it can be done. Is there anyway that I could see the source code and then attempt to modify it to make my own plug-in? If it’s not too difficult, hopefully I can handle it, especially if I’m just modifying code rather than coming up with it from scratch.
Sure, the plug-in IS the source code. Just open the “label-sounds.ny” file in a text editor. The plug-in is written in “Nyquist”, which is a dialect of the LISP programming language. Nyquist is an interpreted language. More info here: https://wiki.audacityteam.org/wiki/Nyquist_Plug-ins_Reference
Also please note that even the “Latest version” has some bugs. They are fixed in my current version, but my current version is incomplete.
I did look at the .ny code, and my hats off to you and others who can manage it. Since the main loop is defined (it seems to me) based on just the minimum sound and minimum silence parameters, I can see why there is no easy way to introduce a maximum sound parameter, as you suggested.
So, I looked for another way, and eventually came up with a work-around. It involves collecting both long duration and short duration silence labels (labled now with thanks to your help here: https://forum.audacityteam.org/t/silence-finder-labels/59528/3), exporting them to Excel, and then running some VBA to generate the desired region labels.
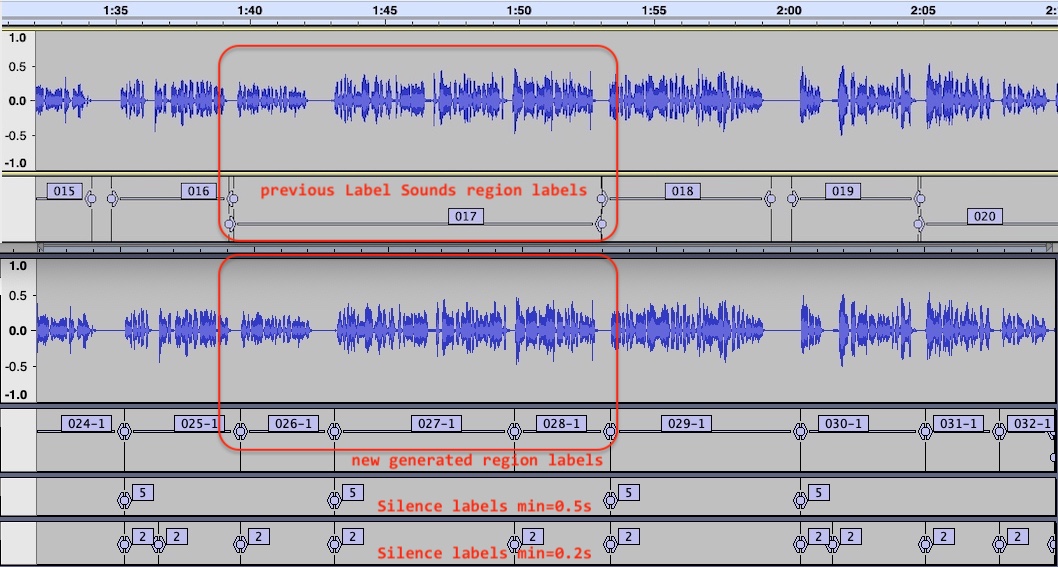
Below is an application to the same problem I mentioned in my original post. In the image below, I’ve repeated that previous image on top, for comparison with the region labels generated using my work-around.
Notice that the region originally labeled “017” now is broken into 3 regions, as desired. To do this my routine prioritizes the longer silence labels over the shorter ones, but choses the shorter ones to comply with both a minimum and maximum sound duration.
While a plug-in would be cleaner, this gives me a way to solve my problem.
I think the reason I didn’t address your question originally was because I didn’t really know the answer. At that point, I had tried many combinations and was frustrated about region labels always present with greater than my desired maximum sound length. But now that I’ve thought of it more, I realize that I was also wanting the tool to prioritize longer silences, indicated by arrows in the figure below. So that is why I eventually decided to write my own code to both (1) prioritize longer silences and (2) specify a maximum sound length.
In the attached project (corresponding to the small portion of audio shown in my original post), I did my best to reproduce what I experienced earlier (it’s a zip archive of a project with just the labels and an mp3 you can drag in). The screenshot below shows 8 label tracks generated with Label Sounds using average level measurement and the parameters shown in the name for each label track. For example, -40, 0.5, 4.0 means threshold -40dB, minimum silence duration 0.5, and minimum sound duration 4.0
The red circles show problems for each label track involving either (1) not prioritizing longer silences or (2) not being able to specify a maximum sound length. I didn’t circle all the problems, just enough to indicate what I mean. Hope this makes sense.
The red arrows represent the longer silences, and my point was that these need to be prioritized over the short silences.
My application is language learning. Listening to a native speaker and repeating what they just said is a good way to learn. However, the learner can only handle so much. So it is good to break the audio into phrases, the shorter the better. However, if the phrases are too short they will lack enough context to make sense.
So the idea is that longer silences correspond to the most significant phrases (such as full sentences) so should have priority over short silences, which usually correspond to clauses, or even words. In practice, it’s not that clean, of course.
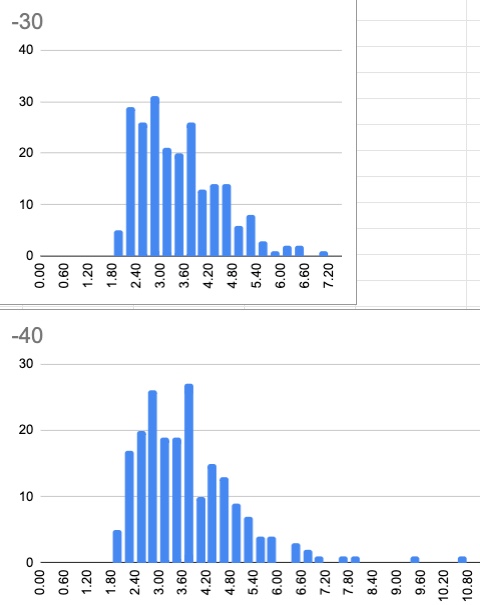
So, now hopefully you see why I wanted code to label the audio based on (1) prioritizing the silence lengths, while at the same time being governed by (2) a maximum sound duration. The noise floor is also important, of course. The 2 histograms below correspond to the sound lengths I generated for one audio using -40 and -30dB. In each case, I used 5 silence tracks using 0.5, 0.4, 0.3, 0.2 and 0.1s, and had min and max sound durations set at 2 and 3.5s
Sometimes shorter and longer sounds get through, both due to the reality of the audio and the fact that my code isn’t perfect.
When programming, it is essential that the program can handle every possible case that it could be exposed to. For a robust program there must be no possible input that can create an “undefined” result.
The problem with having a maximum sound length setting can be seen in this example. Say that we set the minimum sound length to 0.5 seconds and the maximum sound length to 2.5 seconds:
The program needs to define “something” for that long section in the middle.
It could throw an error and cancel the effect, but that could be rather annoying.
It could add a label after 2.5 seconds of the long sound, even though there is no silence there.
It could ignore the max sound length control as there is no obvious place to split.
It could split in the exact middle of that long sound (if longer, split into 3, 4 or however many necessary)
…
Whichever way, it’s unlikely that it will reliably do what the user wants it to do, and it makes the plug-in more complicated.
If you used point labels rather than region labels, then you could easily just add the occasional extra label by hand if required. Is there a reason why you need to use region labels rather than point labels?
I suggest the above. It is realistic – long sounds that cannot be split are easily understandable to a user, and in my experience common. But the existence of exceptions like this, doesn’t lessen the value of having the option when it’s what the user is after.
For the final output, I feel region labels make more sense for a “sound finder” since the thing you’re trying to find (sounds) have a beginning and an end. Regarding adding labels manually, it’s obviously fine as long as there are not too many. But my experiences is that it’s often ‘too many’ which is the whole reason we program.
One thing I find quite interesting is that the “sound finder” methods you’ve made are assessing sound amplitude (average, rms, peak) while the work-around I’ve made does not since it is really manipulations based on a silence finder. Of course, in both cases the dB value is set.