This plug-in is based on the innovative “cross correlation” code snippet by Robert J. H. that he posted here: https://forum.audacityteam.org/t/need-pointers-on-adding-feature-to-search-pattern/33729/3
NOTE: THIS PLUG-IN IS AN EXPERIMENTAL PROOF OF CONCEPT. Use at your own risk.
The effect also has a lot of limitations as described below.
The main reason that I posted this code is because I spent ages yesterday looking for Robert’s script, which was buried in the middle of a long topic on the “General Audio Programming” board. Having eventually located it, I found that it was written using the old “version 3” syntax, so I updated it for the current (2.3.0) version of Audacity, and made it into a plug-in for easier testing.
Unfortunately, the convolution code in Nyquist is still extremely slow, and even though I have increased the speed by reducing the sample rate, it is still quite a slow effect. This effect may become more practical in future versions of Audacity as I see that the current “stand alone” version of Nyquist has a much faster convolution algorithm.
Don’t expect this effect to match spoken words, other than exact copies of the word. There is usually too much variation in natural speech to achieve a match.
Note that this effect works best at matching very short sounds. At (the maximum) half second duration setting, matches are not likely to be found for much
other than pure tones.
WARNING: During development of this plug-in I found that some settings would cause Audacity to crash. The final version published here appears to be reasonably stable on Audacity 2.3.1 alpha, but crashes very regularly on the Linux version of 2.3.0. Use at your own risk.
The concept:
The idea of this plug-in is to take the first fraction of a second of sound from the start of the selection, and search for it occurring again later in the selection. If a match is found, the plug-in adds a label at each match.
Controls:
-
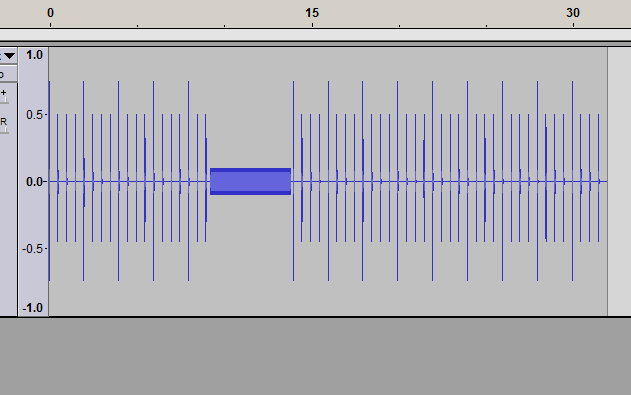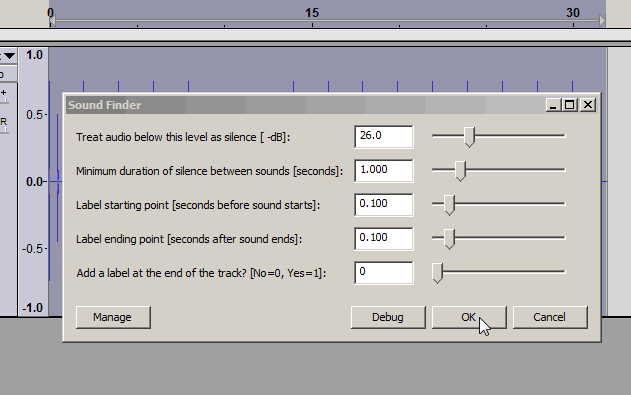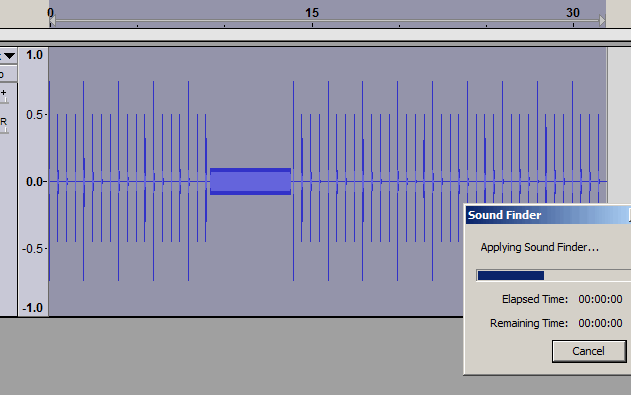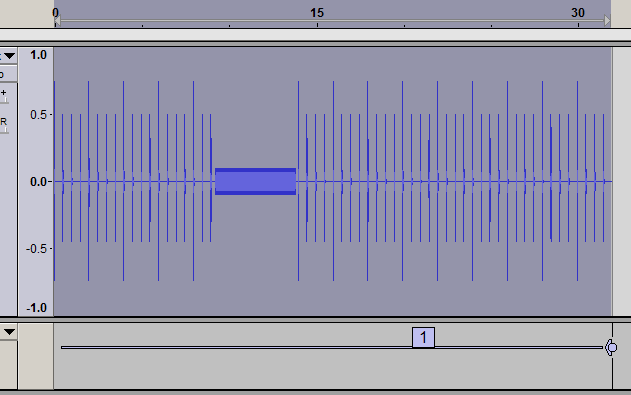
Duration of search pattern (ms) [1ms to 501ms (default 100ms)]
The duration at the start of the selection that forms the “pattern” that the plug-in then searches for. -
Correlation (high = better match) [0.5 to 1.0 (default 0.7)]
The higher the Correlation coefficient, the better the match must be in order for the plug-in to label it.
And the plug-in:
pattern-match.ny (2.45 KB)