Please note that I am new in using an audio editor.
After reading some posts, I thought that the word “Nyquist” here refers to a category of “Plug-Ins”.
On the other hand, I noticed that, in the folder “audacity-win-2.3.0”, there are two separate folders titled “Nyquist” and “Plug-Ins”. And the files in these two folders are of different types.
So I am not sure now what could be the main differences between the two words “Nyquist” and “Plug-Ins”.
“Nyquist” is the name of a famous electronic engineer, Harry Nyquist.
He is probably most famous for the sampling theorem that he devised with Claude Shannon, which is now known as the Nyquist–Shannon sampling theorem, or by its shorter (informal) name, the “Nyquist Theorem”.
Nyquist programming language:
There is a programming language, designed specifically for working with sounds and music, by Roger Dannenberg at Carnegie Mellon University. This language was named after Harry Nyquist and the Nyquist–Shannon sampling theorem.
As Roger was also one of the original creators of Audacity, he thought it was a good idea to shoehorn the language into Audacity, and provided a rudimentary interface that allowed scripts (programs) written in the Nyquist language, to run as plug-ins in Audacity.
Nyquist programs are written in plain text, and run in the “Nyquist interpreter”, which is built into Audacity. Because the programs are just plain text, it is relatively easy for Audacity users to write their own Nyquist scripts.
Over the years, the interface between Nyquist and Audacity has been developed, allowing quite sophisticated plug-ins to be created.
Your Question:
The folder “Nyquist” contains files that belong to (are part of) the Nyquist programming language.
The folder “Plug-ins” contains the Nyquist plug-ins that are shipped with Audacity.
Since the “Nyquist Interpreter” is built into Audacity, learning the Nyquist programming language may also help in the future, after being familiar with Audacity. I guess, there are references for this language.
Added:
I downloaded “nyquistman.pdf” from www.cs.cmu.edu.
Added:
Sadly, it turned out that “Nyquist IDE” is among the programs that “Sourceforge” has no right to let me download.
One of the important differences between Nyquist in Audacity and the standalone Nyquist programming language, is that in Audacity, audio that is selected in a track is accessed via the variable TRACK. For mono tracks, the value of TRACK is a “sound” (for stereo tracks, it is an array of two sounds). So, for example, you can apply a 1000 Hz high pass filter to the selected audio by running this code in the Nyquist Prompt:
There is additional documentation in the Audacity wiki, but please note that this is in the process of being updated for Audacity 2.3.1 which is due to be released soon. There’s quite a lot of new stuff for Nyquist in 2.3.1, so you may find that some features described on the wiki are not yet available. https://wiki.audacityteam.org/wiki/Nyquist_Documentation
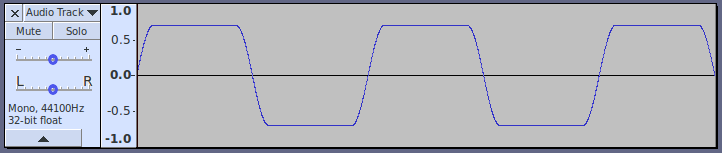
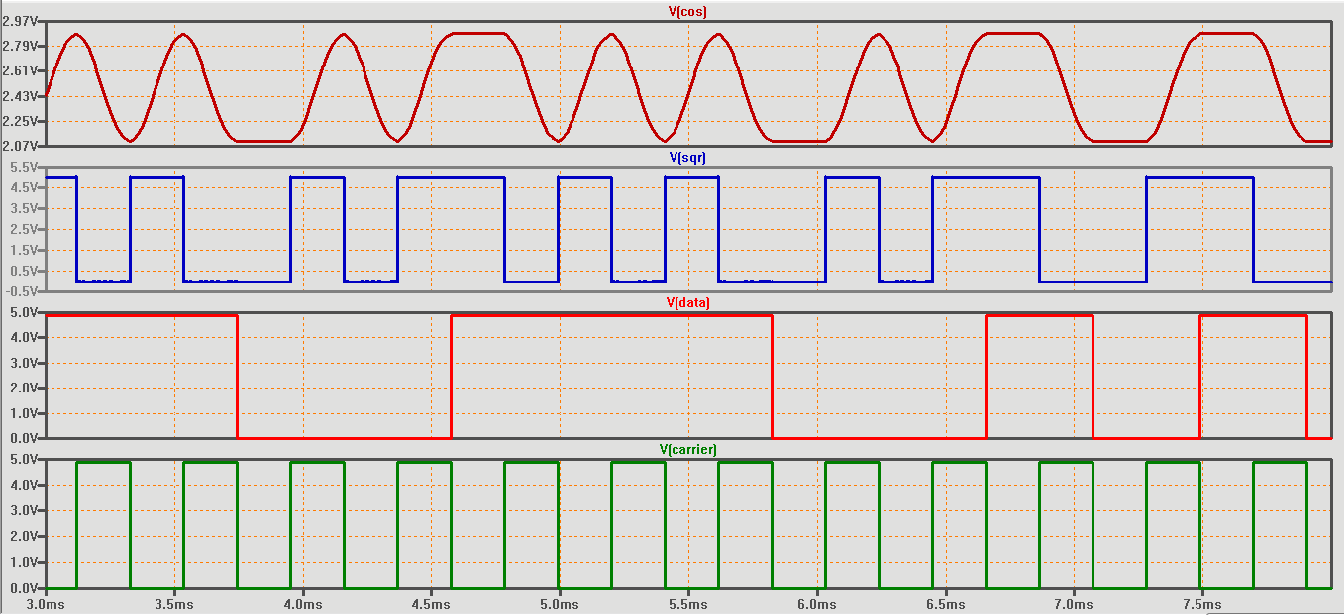
For instance, you may have heard of transferring digital data (serial bits) via audio port. The method, I follow, uses what we may call “Raised Cosine Square Wave”. I am afraid, it is not described on the internet, and it is not related to what is known as “Raised Cosine Filters”. In brief, the leading and trailing edges of such modulated square wave follow the cosine function (of the suppressed audio carrier); this eliminates the higher harmonies of the carrier without the need of a high pass filter. So I will try, while I learn the Nyquist Language, to find out if it can help in synthesizing such data waves.
So what are you wanting to do:
Generate a “Raised Cosine Square Wave” from a set of data?
Condition an existing signal so that it becomes a “Raised Cosine Square Wave”?
Something else?
What is the application?
Is the use of a “Raised Cosine Square Wave” an established and proven technique for this application, or is it an “idea” that you want to try out?
The innovative idea, presented in the article (PDF above), focuses on radio wave transmissions. So I am not sure if its hardware/software implementation (encoding/decoding) is as simple as in the case of using an audio carrier (of a relatively very low frequency, as 2.4 KHz for example).
Yes, it is to transfer raw data (binary) from/into PC via the soundcard (line-out/line-in port) by a clean audio signal.
Sourceforge (and alike) had always no right to let me download any PC compiler that could be used in creating programs by which data could be transferred via a USB port (the only available port in new laps). So the best I was able doing is writing programs for DOS (using my very old BorlandC 3.1 package). Naturally, a few years ago, I had no choice but to find out an alternative reliable (clean) solution for data transferring. Well, the new speed was/is ridiculously slow but I have always believed that having something is always much better than having nothing
For instance, 40 years ago, I proved, to myself in the least, that demodulating a Double Sideband Suppressed Carrier signal (DSB-SC) is much easier and more reliable than demodulating Single Sideband Suppressed Carrier one (SSB-SC). But this contradicts what even the today’s graduate students in electronic communications used hearing/reading. In other words, my work, which I took advantage for many years in my private short-range RF voice links in the 80’s as a scrambling method at that time, is not yet considered as an ‘established proven technique’ since it is not known by FCC. After all, who would listen seriously to an ordinary person living on Mars
This is off-topic, but just as an interesting point of discussion…
I don’t think it does.
DSB-SC is sometimes used for high speed data transmission, and has historically been used for many types of radio transmission. It has become much less common in more recent times.
Some of the reasons for the reduced popularity are:
Available bandwidth for radio communication has become very crowded, and DSB requires double the bandwidth, so only half as many channels are possible within the same frequency range.
In DSB, the upper sideband is essentially a duplicate of the lower sideband. There is zero increase in the amount of data that can be transmitted.
Transmitting DSB requires about 80% more energy compared with SSB,
DSB is more prone to multi-path fading
It is easier to automatically track SSB frequencies (by tracking peak signal) than DSB (requires tracking the silent frequency).
(When I worked at Marconi, we used DSB-SC for transmitting data through microwave pipes. Because the density of signals was low, shortage of bandwidth was not an issue. Because of the frequency stability, the receiver could easily be locked very tightly to the carrier frequency, improving data integrity at relatively high baud rates, despite the low carrier frequency.)
The data-in could be from any file while being treated/read as a binary one; a series of bits from its 8-bit bytes.
In general, speed (carrier frequency) is chosen to be suitable to the audio channel bandwidth via which the transfer is done; for example, 2.4 KHz (2400 bits/sec) seemed good for most voice channels. Higher frequencies could be used if the transfer is between the soundcard and an external MCU.
First, I agree with you on all your points concerning the reduced popularity of DSB-SC.
But would you please tell me, based on your experience and knowledge, if demodulating DSB-SC is now much easier, less expensive and more reliable than demodulating SSB-SC, or not? I mean it is just an academic question.
In case you think it is, I wonder if you have any reference about it. Thank you.
For instance, my simple analogue demodulator (based on PLL with one loop only, unlike Costas Loop) could be integrated as an IC since it has no coil (LC tank) or any other ‘selective’ passive/active filters (as in Squaring Loop topology). In the 80’s, I built it using standard ICs and components. And being based on PLL, I was able varying, at the transmitter, the frequency of the suppressed carrier (at about 6 Hz rate, in +/- 5% range) to produce noise-like interference if tuned on conventional AM MW receivers. Beside the relative simplicity of modulating and demodulating DSB-SC (to me in the least, concerning the demodulator), the transmitter output power, during a conversation, also becomes almost null if no voice (during silent periods).
In this simple example, there are no stop / start / parity bits, just a direct encoding of list of ones and zeros into an audio waveform.
For practical use it would need some modification, particularly as this will cause a stack overflow if the data is too long. Nevertheless, it should be able to handle a few hundred bits.
For long data, you would need to replace the SEQREP function with a DO loop, and handle I/O without retaining the data in RAM.
;type generate
(setf baud 2205) ;This gives an exactly 20 samples per bit packet.
;Define time to transit between low and high states as
;proportion of bit packet time.
(setf transition 0.3)
;Define signal level as bool t or nil.
(setf state t)
;Binary data as list
(setf data (list 1 1 0 1 0 1 0 0 1 0 1 1 0 1 0 0 0 1 0))
;Total length of a single bit
(setf bitdur (/ 1.0 baud))
(defun rise (dur)
(setf hz (/ 0.5 dur))
(osc (hz-to-step hz) dur *sine-table* -90))
(defun fall (dur)
(setf hz (/ 0.5 dur))
(osc (hz-to-step hz) dur *sine-table* 90))
;;;Convert transition time to seconds, rounded to exact number of samples
(defun get-transition-dur (dur ratio)
(let ((ttime (round (* ratio dur *sound-srate*))))
(/ ttime *sound-srate*)))
;;; Generate binary 1.
;;; 'state' is true/false for current signal level
(defun one ()
(setf sig (if state one-const one-rise))
(setf state t)
sig)
;;; Generate binary 0.
;;; 'state' is true/false for current signal level
(defun zero ()
(setf sig (if state zero-fall zero-const))
(setf state nil)
sig)
(defun add-bit (bit)
(if (= bit 1) (one) (zero)))
;; We require a different wave shape depending on current state
(setf one-const
(let ((tdur (get-transition-dur bitdur transition)))
(snd-const 1 0 *sound-srate* (- bitdur tdur))))
(setf one-rise
(let ((tdur (get-transition-dur bitdur transition)))
(seq (rise tdur)
(cue (snd-const 1 0 *sound-srate* (- bitdur tdur))))))
(setf zero-const
(let ((tdur (get-transition-dur bitdur transition)))
(snd-const -1 0 *sound-srate* (- bitdur tdur))))
(setf zero-fall
(let ((tdur (get-transition-dur bitdur transition)))
(seq (fall tdur)
(cue (snd-const -1 0 *sound-srate* (- bitdur tdur))))))
(seqrep (i (length data)) (cue (add-bit (nth i data))))