OK, let’s take a different approach.
The source code says:
snd_xform – return a sound with transformations applied.
The “logical” sound starts at snd->time and runs until some
as yet unknown termination time. (There is also a possibly
as yet unknown logical stop time that is irrelevant here.)
The sound is clipped (zero) until snd->t0 and after snd->stop,
the latter being a sample count, not a time_type.
So, the “physical” sound starts at snd->t0 and runs for up to
snd->stop samples (or less if the sound terminates beforehand).
The snd_xform procedure operates at the “logical” level, shifting
the sound from its snd->time to time. The sound is stretched as
a result of setting the sample rate to sr. It is then (further)
clipped between start_time and stop_time. If initial samples
are clipped, the sound is shifted again so that it still starts
at time. The sound is then scaled by scale.
To support clipping of initial samples, the “physical” start time
t0 is set to when the first unclipped sample will be returned, but
the number of samples to clip is saved as a negative count. The
fetch routine SND_flush is installed to flush the clipped samples
at the time of the first fetch. SND_get_first is then installed
for future fetches.
An empty (zero) sound will be returned if all samples are clipped.
If I run the code (as a test example):
(let ((sound s)
(sr *sound-srate*)
(time 0)
(start 1.25)
(stop 3.5)
(scale 1))
(snd-xform sound sr time start stop scale))
then SND-XFORM behaves exactly as advertised. Do you agree?
Now what happens if we change “time”?
This gets a bit peculiar in Audacity because the start time for returned sounds is always zero. (Note that Nyquist was written as a standalone programming language that was shoehorned into Audacity to provide a simple but powerful tool for rapid development of experimental plug-ins).
(let ((sound s)
(sr *sound-srate*)
(time 2)
(start 1.25)
(stop 3.5)
(scale 1))
(snd-xform sound sr time start stop scale))
In this case, the start time is shifted by Nyquist to 2.0, but when the sound is returned to Audacity, the start time is zero. The act of returning the sound to Audacity has shifted the sound backward to zero.
We can counteract this shift by giving Audacity a “time = 0” reference:
(let ((sound s)
(sr *sound-srate*)
(time 2)
(start 0)
(stop 5)
(scale 1))
(sum (s-rest 1)
(snd-xform sound sr time start stop scale)))
Now we get the expected behaviour.
As an example - generate a 10 second “Chirp” and apply the above code and the result is (as expected):
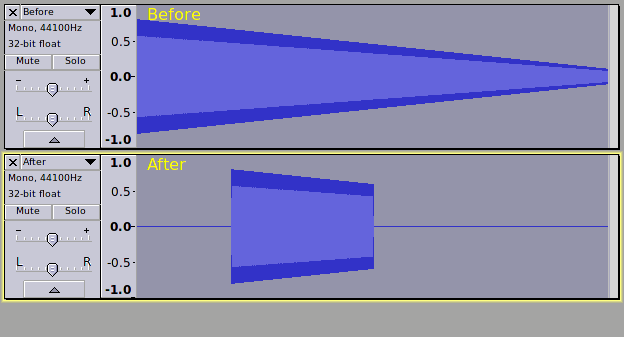
Let’s modify the code a little:
(let ((sound s)
(sr *sound-srate*)
(time 2)
(start 0)
(stop 5)
(scale 1))
(sum (s-rest 0.5)
(snd-xform sound sr time start stop scale)))
Again we get the expected result:
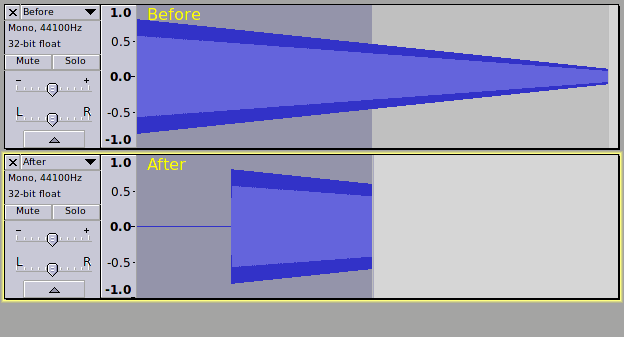
Now let’s shorten the “s-rest” a little more:
(let ((sound s)
(sr *sound-srate*)
(time 2)
(start 0)
(stop 5)
(scale 1))
(sum (s-rest 0.4)
(snd-xform sound sr time start stop scale)))
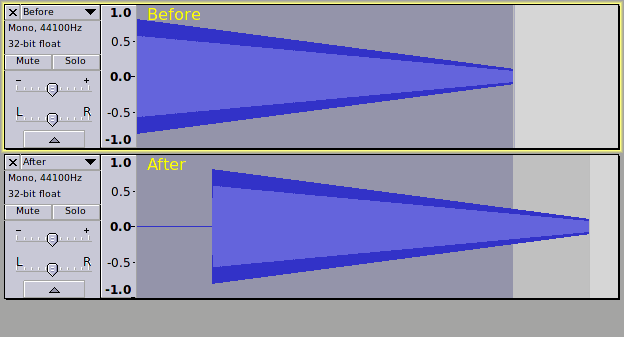
We now have an appearance of “the bug”!
We expected that “sound” would stop at 5.0 seconds because we tried to clip it to 5.0 seconds. When we did this without SIM it worked fine, but for some reason SIM has messed it up! Why?
Simultaneous Behavior
http://www.cs.cmu.edu/~rbd/doc/nyquist/part4.html#27
Strictly speaking, this is wrong!
SIM returns a sound which is the sum of the given behaviours and as the manual stresses “sounds are not behaviors!”- usually we can get away with it, but not this time.
What happens if we (correctly) use CUE in the last example?
(let ((sound s)
(sr *sound-srate*)
(time 2)
(start 0)
(stop 5)
(scale 1))
(sum
(cue (s-rest 0.4))
(cue (snd-xform sound sr time start stop scale))))
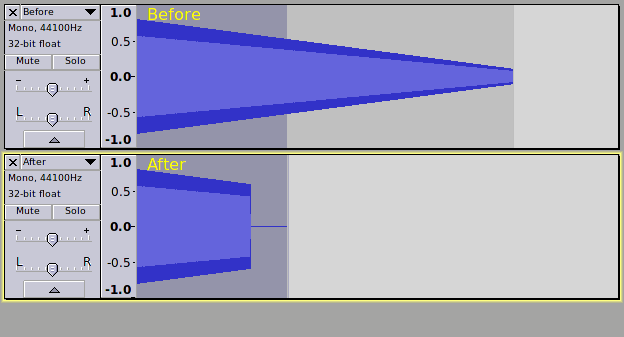
It’s not what we wanted, but it has done the right thing. SIM (or SUM) plays both sounds starting at the same time.
What we actually wanted was to start “sound” at 2.0 seconds, so the “correct” code would be:
(let ((sound s)
(sr *sound-srate*)
(time 2)
(start 0)
(stop 5)
(scale 1))
(sum
(cue (s-rest 0.4))
(at-abs 2
(cue (snd-xform sound sr time start stop scale)))))
but this will not work!
We want snd-xform to set the start and stop time of “sound”, but we are overriding it with (SIM (AT-ABS (CUE … so snd-xform does not get evaluated.
To get this to work (and still be “correct”) we need to evaluate SND-XFORM using the start time and stop time of “sound”.
If we use SIM (or SUM) with a number and a sound, SND-OFFSET is used to perform the operation, and this will then evaluate our SND-XFORM function using the start time and stop time of “sound”.
(let ((sound s)
(sr *sound-srate*)
(time 2)
(start 0)
(stop 5)
(scale 1))
(sum
(cue (s-rest 0.4))
(at-abs 2
(cue (sum 0 (snd-xform sound sr time start stop scale))))))