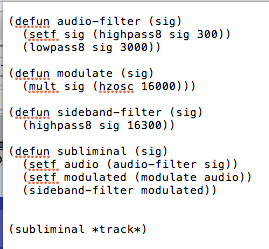
I want to do experiments with silent subliminal. So let’s say I use the silent subliminal script on an audio, it’ll occupy some 3000Hz above and below the chosen frequency. I pan this to one left channel.
In the process of transforming an audio into silent subliminal, 14000Hz information is discarded, is there a way to obtain this discarded information, I want to use this discarded content and pan it to the right channel. Then I want to try playing both at once to see if it has any effect.
Another idea is, since the silent subliminal retains the amplitude of the audio, is there a way to retain the frequency of the audio, I would use one in left ear and another in right ear.
I made the message from simple, good quality mono sound at 44100, 16-bit. At the other end, I expected and got my message at clear but telephone quality. Remember telephones?
In the middle is a very nearly completely silent track with the encoded energy up where only dogs can hear it.
I have actual goal of improving myself through hypnosis and affirmations. I’m coming up with ideas and experiments to find an effective way to make subliminal. I don’t have smoking problem. I’ll try your code and get back to you.
To be clear, it’s not my code. It’s SteveTF’s code. He’s the developer/programmer. I’m the broadcast engineer who knows what Single Sideband is.
Also, I’m the one who insists on being able to reverse the message back to clear voice to keep the process, or at least our part of it, from becoming “magic.”
You copied just the code and not my notes at the top?
Which Audacity do you have?
You should have a plain speech message on the timeline and it should be selected.
The message should be Mono, 44100Hz, 16-bit PCM.
Do you get any errors?
There is one odd test you can do. Briefly listen to your message. Do the conversion and try to listen to it again. It should be silent even though there are blue waves on the timeline.
You should probably use higher resolution display (attached).
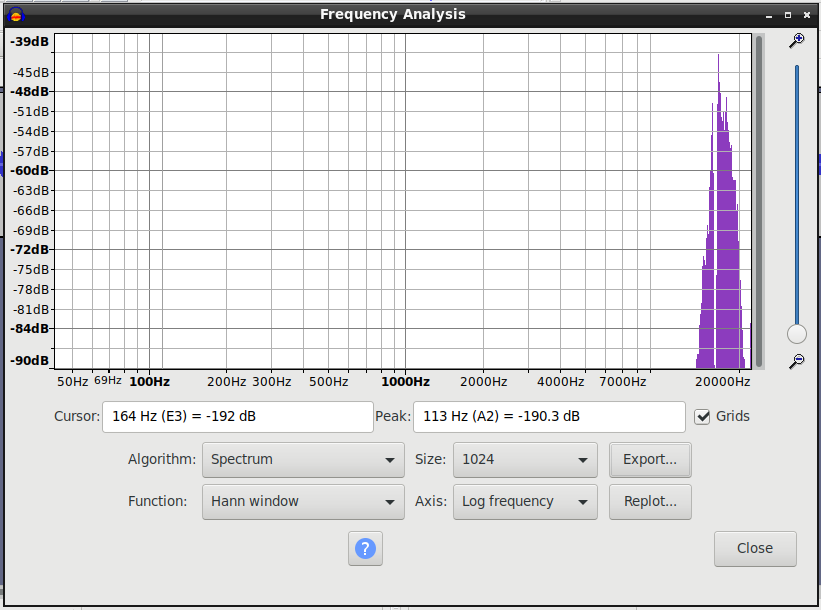
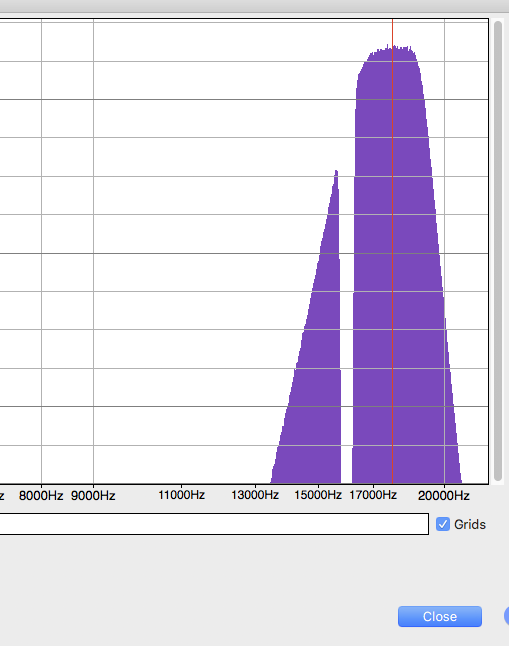
If you’re using the SSB, Suppressed Carrier method called in our postings, then that “hole” is where the carrier was, at 16000 Hz.
In short, that’s normal.
You can also boost the display by dragging the right-hand side of the plot to the right, then click on the top and drag the whole thing to the left-off the screen. Repeat. The section at the right of the sweep will get larger and easier to see.
For reference, bass notes are just to the right of 16000Hz, and the message goes up in pitch until you hit the highest pitch notes around 20000Hz. That’s the limit of most soundcards, speakers, and headphones. Any sound higher pitch than that—“real sound” or sidebands—is lost.
The goal is to snuggle all the audible tones in your affirmation speech between those two points. You can’t hear that high a pitch. That’s what makes it Silent Subliminal.
If you used one of the other subliminal techniques, you’re on your own.
I’m not sure this is going to help, but in normal broadcasting, the right-hand purple blob would be mirror-imaged on the left and the hole would be filled with the broadcast radio transmitter carrier at 880KHz, 1040KHz or whichever AM radio station you’re listening to.
That’s what got my attention about this process. It follows normal engineering practices, and you can reverse it back to clear speech with the supplied decoder.
Whether or not the affirmation works is up to you. Have you decided what the message is going to be?