Hello, first time poster here. I’ve been using Audacity fairly intensively for certain aspects of music creation for about half a year, but I just recently decided to make it my DAW, so I’m ready to invest some time in learning its capabilities more fully. I’ve been reading the manual/wiki/forums and I’m amazed by the features it offers (that I was not using), the level of knowledge that exists here, as well as the dedication of the developers. So impressive.
Anyway, I have a question about equal loudness curves and the plot spectrum as they relate to music creation, dB levels, mixing, and EQ.
I have read that a general rule of thumb is that for two occurrences of the same basic sound to vary noticeably in terms of volume/dynamics, they need to differ from each other by at least one dB. Less than a dB and it sounds completely unvaried in terms of dynamics (like the “machine gun” snare rolls in really bad EDM). This is a general rule I’ve been using when creating musical parts in Audacity from samples. So, for example, if I’m creating a percussion part (hi hats, cymbal, snare roll, kicks etc) I will usually make two adjacent hits at least a dB apart (say, -2 dB followed by -3 dB) so that a listener is able to perceive them as being distinct, volume-wise. If I have five different hi hat samples in a hi hat pattern, a fairly common things I’ll do is have them set at -1, -2, -3, -4, -5 (or sometimes more like -1, -3, -5, -7, -9). This has been a decent rule of thumb so far, although lately I have been tending to larger differences like 1.5 or 2 dB. I get a decent amount of dynamic variation this way.
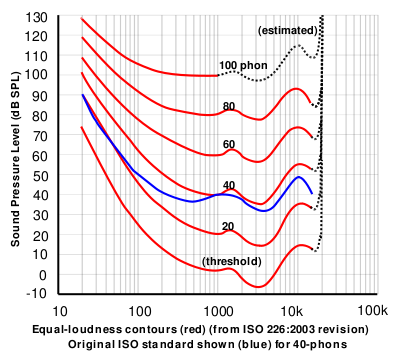
I have also read just the bare minimum about equal loudness curves, and how different frequencies need to be at different dB levels to be perceived by a listener as being equally loud. I get the basic concept, but only have a very rough understanding of how to employ this idea in music creation and mixing (although I find it helps just to be aware of it while mixing, even if you’re still getting the job done primarily through trial and error and active listening).
So my question is how these two things relate, and how to go about analyzing sounds to be able to make smart choices about it. So, for instance, let’s just say that a sound centered at 4,000 Hz only needs to be at -4 dB to be perceived as being equally loud as a different sound centered at 1,000 Hz, at -2 dB (I have no idea if this is even close to accurate – I just chose -2 and -4 to keep the math simple). Does this mean that the dB difference needed between two of “4,000 hZ sounds” would be only half of the dB difference needed between two of “1,000 hZ sounds?” Or the other way around? Or does it really not work this way at all?
Assuming that there is some kind of merit/usefulness to what I wrote above, what would be a good way to go about implementing this knowledge in music creation? I see that Audacity has a “Plot spectrum” function that gives a visual readout of the frequencies present in a given sound. And I also understand that the smaller the audio clip analyzed, the more accurate it is. Would this be a good tool to use for my purposes? Basically, could I analyze a kick drum, see where the predominant frequencies are, compare that to the equal loudness curve, and then use that to determine my minimum dB difference? If so, then using this same method to analyze a hi hat should yield a different minimum dB difference, because the frequency profile of each instrument is pretty drastically different.
Assuming the plot spectrum is a good tool for this purpose, what is the best way to read it? Obviously, most non-synthesized sounds are going to have dB energy across a wide swath of the audible frequency spectrum. What kind of rule of thumb can I use to say “this sound is primarily ______ Hz?” Is it just a matter of looking for the peak, and that’s what I would use?
Or is this all just unnecessary analysis? I’m anticipating that someone will say “just use your ears, son,” which is fine – I agree that ultimately that is the best test of whether any methodology really works. But still, I’m intrigued by the possibilities of this, so I’m curious if anyone has any insight into how I might make it all work for me.
Please correct any misinformation or bad assumptions I have. I’m here to learn.
Thanks.